
线上OOM排查步骤总结
1、使用dmesg命令查看系统日志
dmesg |grep -E 'kill|oom|out of memory',可以查看操作系统启动后的系统日志,这里就是查看跟内存溢出相关联的系统日志。
2、这时候,需要启动项目,使用ps命令查看进程
ps -aux|grep java 或者是 ps -ef|grep java 命令查看一下你的java进程,就可以找到你的java进程的进程id。
3、接着使用top命令
top命令显示的结果列表中,会看到%MEM这一列,这里可以看到你的进程可能对内存的使用率特别高。以查看正在运行的进程和系统负载信息,包括cpu负载、内存使用、各个进程所占系统资源等。
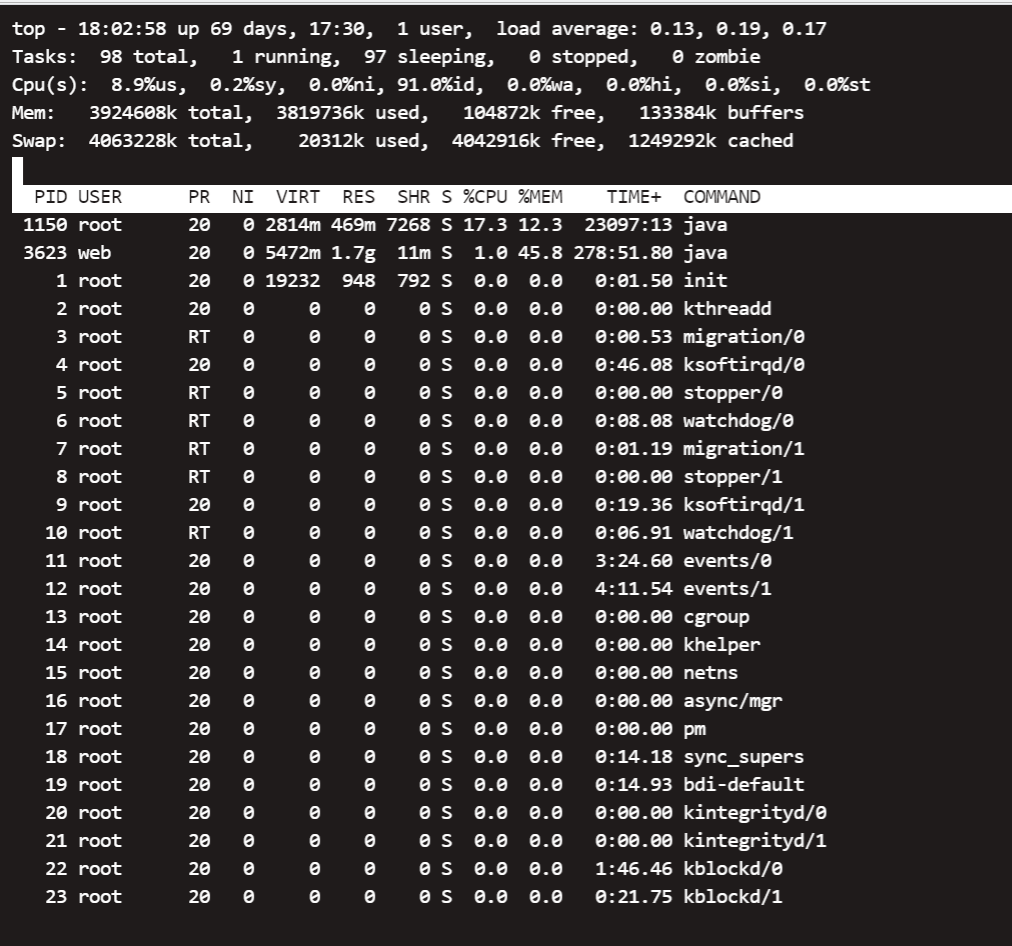
4、使用jstat命令
用jstat -gcutil 20886 1000 10命令,就是用jstat工具,对指定java进程(20886就是进程id,通过ps -aux | grep java命令就能找到),按照指定间隔,看一下统计信息,这里会每隔一段时间显示一下,包括新生代的两个S0、s1区、Eden区,以及老年代的内存使用率,还有young gc以及full gc的次数。
使用 jstat -gcutil 8968 500 5 表示每500毫秒打印一次Java堆状况(各个区的容量、使用容量、gc时间等信息),打印5次
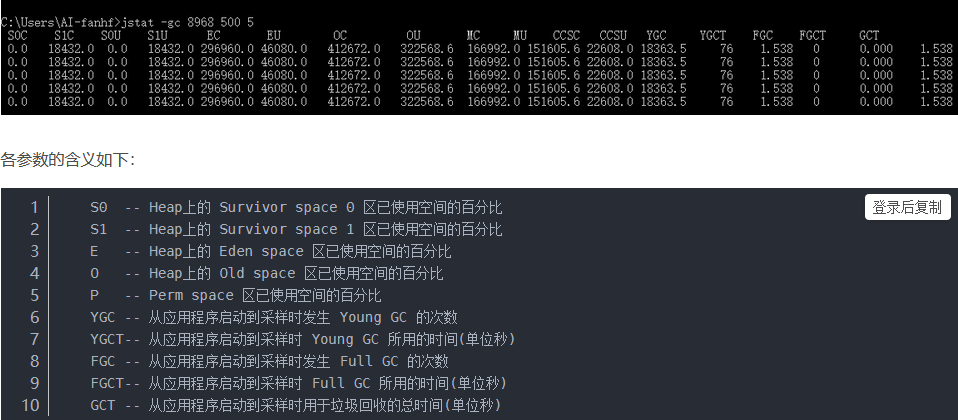
例如:
看到的东西类似下面那样:
S0 S1 E O YGC FGC
26.80 0.00 10.50 89.90 86 954
其实如果大家了解原理,应该知道,一般来说大量的对象涌入内存,结果始终不能回收,会出现的情况就是,快速撑满年轻代,然后young gc几次,根本回收不了什么对象,导致survivor区根本放不下,然后大量对象涌入老年代。老年代很快也满了,然后就频繁full gc,但是也回收不掉。
然后对象持续增加不就oom了,内存放不下了,爆了呗。
所以jstat先看一下基本情况,马上就能看出来,其实就是大量对象没法回收,一直在内存里占据着,然后就差不多内存快爆了。
5、使用jmap命令查看
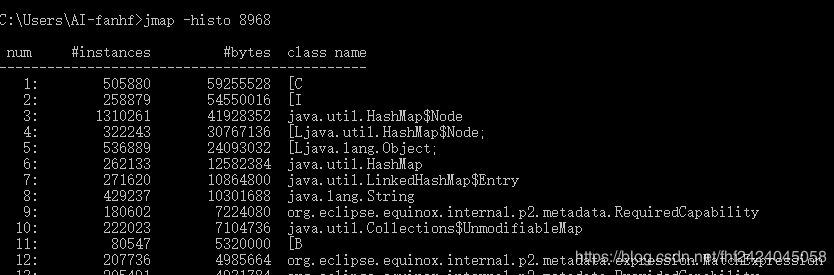
执行jmap -histo pid可以打印出当前堆中所有每个类的实例数量和内存占用,如下,class name是每个类的类名([B是byte类型,[C是char类型,[I是int类型),bytes是这个类的所有示例占用内存大小,instances是这个类的实例数量。
6、把当前堆内存的快照转储到dumpfile_jmap.hprof文件中,然后可以对内存快照进行分析
使用jmap -dump:format=b,file=文件名 [pid],就可以把指定java进程的堆内存快照搞到一个指定的文件里去,但是jmap -dump:format其实一般会比较慢一些,也可以用gcore工具来导出内存快照
例如:jmap -dump:format=b,file=D:/log/jvm/dumpfile_jmap.hprof 20886
接着就是可以用MAT工具,或者是Eclipse MAT的内存分析插件,来对hprof文件进行分析,看看到底是哪个王八蛋对象太多了,导致内存溢出了
8、总结:
一般常见的OOM,要么是短时间内涌入大量的对象,导致你的系统根本支持不住,此时你可以考虑优化代码,或者是加机器;要么是长时间来看,你的很多对象不用了但是还被引用,就是内存泄露了,你也是优化代码就好了;这就会导致大量的对象不断进入老年代,然后频繁full gc之后始终没法回收,就撑爆了
要么是加载的类过多,导致class在永久代理保存的过多,始终无法释放,就会撑爆
我这里可以给大家最后提一点,人家肯定会问你有没有处理过线上的问题,你就说有,最简单的,你说有个小伙子用了本地缓存,就放map里,结果没控制map大小,可以无限扩容,最终导致内存爆了,后来解决方案就是用了一个ehcache框架,自动LRU清理掉旧数据,控制内存占用就好了。
另外,务必提到,线上jvm必须配置-XX:+HeapDumpOnOutOfMemoryError,-XX:HeapDumpPath=/path/heap/dump。因为这样就是说OOM的时候自动导出一份内存快照,你就可以分析发生OOM时的内存快照了,到底是哪里出现的问题。
9、修改代码调优,修改jvm配置调优,部署接口压测
代码进行优化、根据压测的情况去进行一定的jvm参数的调优,一个系统的QPS,一个是系统的接口的性能,压测到一定程度的时候 ,机器的cpu、内存、io、磁盘的一些负载情况,jvm的表现
10、流程

附加:系统频繁full gc:
比OOM稍微好点的是频繁full gc,如果OOM就是系统自动就挂了,很惨,你绝对是超级大case,但是频繁full gc会好多,其实就是表现为经常请求系统的时候,很卡,一个请求卡半天没响应,就是会觉得系统性能很差。
首先,你必须先加上一些jvm的参数,让线上系统定期打出来gc的日志:
-XX:+PrintGCTimeStamps
-XX:+PrintGCDeatils
-Xloggc:<filename>
这样如果发现线上系统经常卡顿,可以立即去查看gc日志,大概长成这样:
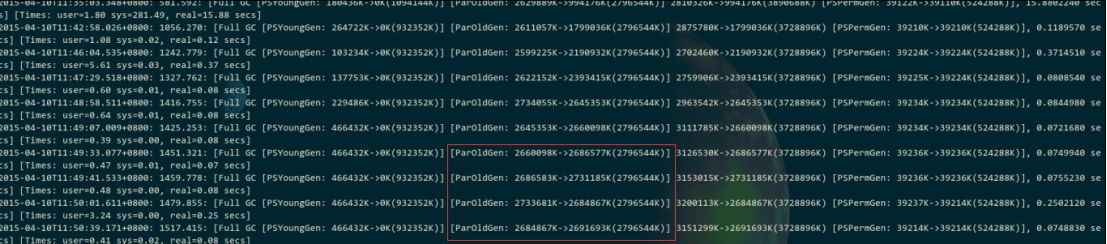
如果要是发现每次Full GC过后,ParOldGen就是老年代老是下不去,那就是大量的内存一直占据着老年代,啥事儿不干,回收不掉,所以频繁的full gc,每次full gc肯定会导致一定的stop the world卡顿,这是不可能完全避免的。接着采用跟之前一样的方法,就是dump出来一份内存快照,然后用Eclipse MAT插件分析一下好了,看看哪个对象量太大了。接着其实就是跟具体的业务场景相关了,要看具体是怎么回事,常见的其实要么是内存泄露,要么就是类加载过多导致永久代快满了,此时一般就是针对代码逻辑来优化一下。
给大家还是举个例子吧,我们线上系统的一个真实例子,大家可以用这个例子在面试里来说,比如说当时我们有个系统,在后台运行,每次都会一下子从mysql里加载几十万行数据进来各种处理,类似于定时批量处理,这个时候,如果对几十万数据的处理比较慢,就会导致比如几分钟里面,大量数据囤积在老年代,然后没法回收,就会频繁full gc。
当时我们其实就是根据这个发现了当时两台机器已经不够了,因为我们当时线上用了两台4核8G的虚拟机在跑,明显不够了,就要加机器了,所以增加了机器,每台机器处理更少的数据量,那不就ok了,马上就缓解了频繁full gc的问题了。

