Java内存模型详解
前言
Java内存模型是Java程序员学习JVM前必须要掌握的基础知识 ,也是面试中经常会被问到的问题点。但是要真正完全弄清楚它,还是有点难度的,因为Java内存模型是不可见的,它并不是一个真实的东西,它只是一个概念、一个规范。
计算机硬件体系介绍,CPU多级缓存
要想完全搞清楚Java内存模型,先要了解计算机硬件架构,特别是计算机CPU和主存之间的架构。在计算机中,cpu和内存的交互最为频繁,相比内存,磁盘读写太慢,内存相当于高速的缓冲区。但是随着cpu的发展,内存的读写速度也远远赶不上cpu。因此cpu厂商在每颗cpu上加上高速多级缓存,用于缓解这种情况。现在cpu和内存的交互大致如下。
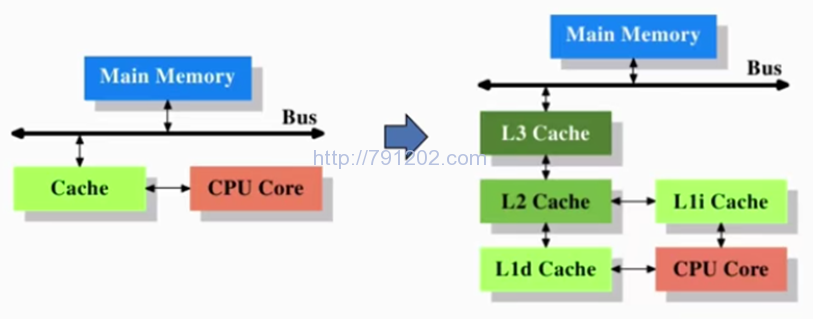
CPU多级缓存
三级缓存(L1、L2、L3),L1最靠近CPU核心,L2其次,L3再次。运行速度方面:L1最快、L2次快、L3最慢;容量大小方面:L1最小、L2较大、L3最大。CPU会先在最快的L1中寻找需要的数据,找不到再去找次快的L2,还找不到再去找L3,L3都没有那就只能去内存找了。其中一级缓存还分为一级数据缓存(Data Cache,D-Cache,L1d)和一级指令缓存(Instruction Cache,I-Cache,L1i),分别用于存放数据及执行数据的指令解码,两者可同时被CPU访问,减少了CPU多核心、多线程争用缓存造成的冲突,提高了处理器的效能。一般CPU的L1i和L1d具备相同的容量。
缓存一致性问题
给CPU加上了高速缓存,主内存存取速度赶不上CPU的问题貌似就解决了,一切看似都很美好。但是科技在不断进步,CPU厂商们也在不断推陈出新,于是多核CPU出现了,每个CPU上又有高速缓存,CPU与内存的交互就变的比原来复杂了,如下图所示。
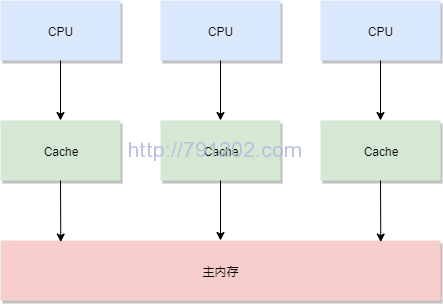
这就引发了新的问题,缓存一致性问题。为什么会出现这个问题呢?CPU需要修改某个数据,是先去Cache中找,如果Cache中没有找到,再去内存中找,然后把数据复制到Cache中,下次就不需要再去内存中寻找了,然后进行修改操作。而修改操作的过程是先在Cache里面修改数据,然后再把数据刷新到主内存。其他CPU需要读取数据,也是先去Cache中去寻找,如果找到了就不会去内存找了。 所以当两个CPU的Cache同时都拥有某个数据,其中一个CPU修改了数据,另外一个CPU是无感知的,并不知道这个数据已经不是最新的了,它要读取数据还是从自己的Cache中读取,这样就导致了“缓存不一致”。其实对于这样的描述并不是十分准确,因为计算、读取等操作都是在CPU的寄存器中进行的,这样的描述是为了让问题变得更简单,相信学过计算机体系的人应该非常清楚整个流程,在这里就简单的描述下。
如何解决 “缓存不一致” ?
解决这个问题的方法有很多,比如:
1.总线加锁(此方法性能较低,现在已经不会再使用)。
2.MESI协议: 这是Intel提出的,MESI协议也是相当复杂,在这里我就简单的说下:当一个CPU修改了Cache中的数据,会通知其他缓存了这个数据的CPU,其他CPU会把Cache中这份数据的Cache Line置为无效,要读取数据的话,直接去内存中获取,不会再从Cache中获取了。
下图很好的阐释了多核CPU下, MESI协议是如何工作的。

MESI协议 ,四种数据状态:Modify、Exclusive、Shared、Invalid
有了 MESI协议 ,我们再来看看多核CPU缓存与主内存的关系。

Java线程与硬件处理器
其实,我们在Java中开启一个线程,最终也是交给CPU去执行。 具体的流程是:我们在使用Java线程,内部会调用操作系统(OS)的内核线程(Kernel-Level Thread),这种线程是操作系统内核(Kernel)直接支持的,内核通过调度器,对线程进行调度,并将线程交给各个CPU内核去处理。 如下图所示:
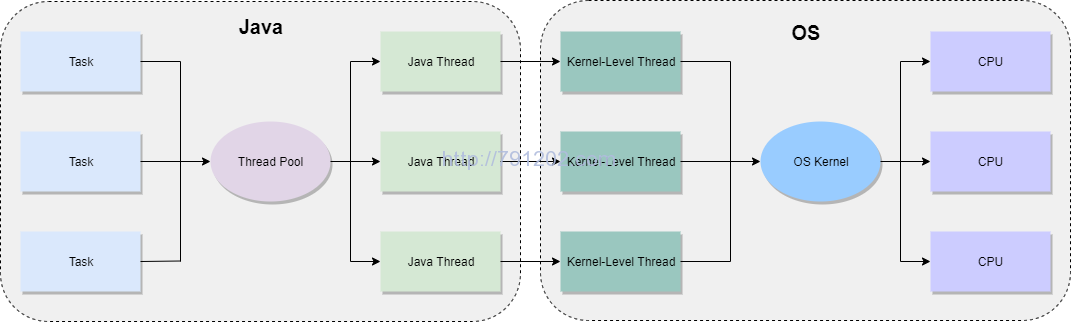
Java内存模型概念
Java内存模型(jmm, Java Memory Model):JMM规范了java虚拟机与计算机内存是如何协同工作的,规定了一个线程如何和何时可以看到其他线程修改过的共享变量的值,以及在必须时如何同步的访问共享变量。JMM是java虚拟机规范定义的,用来屏蔽掉java程序在各种不同的硬件和操作系统对内存的访问的差异,这样就可以实现java程序在各种不同的平台上都能达到内存访问的一致性。正如文章开头所说JMM其实是不存在的,它只是一个规范,最终Java程序都会交给CPU去运行,所以上面是计算机硬件体系是基础,有了上面的基础,才有了Java内存模型,或者说Java的内存模型就是利用了计算机硬件体系。
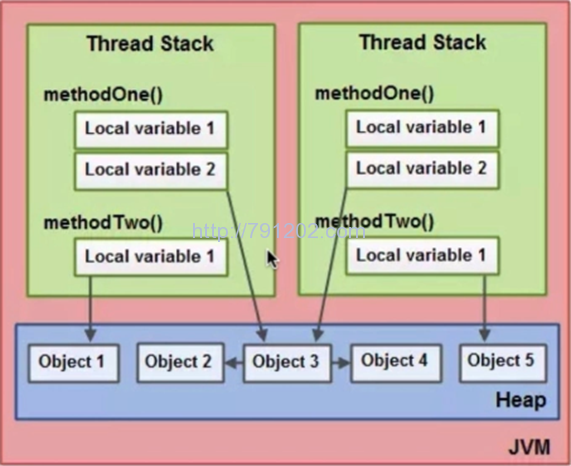
本地内存:我们知道,Java里面每个线程都有一个自己的本地内存(上图绿色区域),存放的是私有变量和主内存数据的副本。如果私有变量是基本数据类型,则直接存放在本地内存,如果是引用类型变量,存放的是引用(指针),实际的数据存放在主内存。本地内存是不共享的,只有属于它的线程可以访问。也有好多人把本地内存称之为线程栈或者工作空间。
主内存:存放的是共享的数据,所有线程都可以访问。当然它也有不少其他称呼,比如堆内存,共享内存等等。
Java内存模型规定了所有对共享变量的读写操作都必须在本地内存中进行,需要先从主内存中拿到数据,复制到本地内存,然后在本地内存中对数据进行修改,再刷新回主内存。
并发编程的问题
前面说的和硬件有关的概念你可能听得有点蒙,还不知道他到底和软件有啥关系。但是关于并发编程的问题你应该有所了解,比如原子性问题,可见性问题和有序性问题。
其实,原子性问题,可见性问题和有序性问题。是人们抽象定义出来的。而这个抽象的底层问题就是前面提到的缓存一致性问题、处理器优化问题和指令重排问题等。
这里简单回顾下这三个问题,并不准备深入展开,感兴趣的读者可以自行学习。我们说,并发编程,为了保证数据的安全,需要满足以下三个特性:
原子性是指在一个操作中就是cpu不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行。
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性即程序执行的顺序按照代码的先后顺序执行。
有没有发现,缓存一致性问题其实就是可见性问题。而处理器优化是可以导致原子性问题的。指令重排即会导致有序性问题。所以,后文将不再提起硬件层面的那些概念,而是直接使用大家熟悉的原子性、可见性和有序性。
Java内存模型的实现
了解Java多线程的朋友都知道,在Java中提供了一系列和并发处理相关的关键字,比如volatile、synchronized、final、concurrent包等。其实这些就是Java内存模型封装了底层的实现后提供给程序员使用的一些关键字在开发多线程的代码的时候,我们可以直接使用synchronized等关键字来控制并发,从来就不需要关心底层的编译器优化、缓存一致性等问题。所以,Java内存模型,除了定义了一套规范,还提供了一系列原语,封装了底层实现后,供开发者直接使用。本文并不准备把所有的关键字逐一介绍其用法,因为关于各个关键字的用法,网上有很多资料。读者可以自行学习。本文还有一个重点要介绍的就是,我们前面提到,并发编程要解决原子性、有序性和一致性的问题,我们就再来看下,在Java中,分别使用什么方式来保证。
原子性
在Java中,为了保证原子性,提供了两个高级的字节码指令monitorenter和monitorexit。在synchronized的实现原理文章中,介绍过,这两个字节码,在Java中对应的关键字就是synchronized。因此,在Java中可以使用synchronized来保证方法和代码块内的操作是原子性的。
可见性
Java内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值的这种依赖主内存作为传递媒介的方式来实现的。Java中的volatile关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。因此,可以使用volatile来保证多线程操作时变量的可见性。除了volatile,Java中的synchronized和final两个关键字也可以实现可见性。只不过实现方式不同,这里不再展开了。
有序性
在Java中,可以使用synchronized和volatile来保证多线程之间操作的有序性。实现方式有所区别:
volatile关键字会禁止指令重排。synchronized关键字保证同一时刻只允许一条线程操作。好了,这里简单的介绍完了Java并发编程中解决原子性、可见性以及有序性可以使用的关键字。读者可能发现了,好像synchronized关键字是万能的,他可以同时满足以上三种特性,这其实也是很多人滥用synchronized的原因。但是synchronized是比较影响性能的,虽然编译器提供了很多锁优化技术,但是也不建议过度使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号