

L1和L2 详解(范数、损失函数、正则化)
一、易混概念
对于一些常见的距离先做一个简单的说明
1.欧式距离
假设X和Y都是一个n维的向量,即
则欧氏距离:
2.L2范数
假设X是n维的特征
L2范数:
3.闵可夫斯基距离
这里的p值是一个变量,当p=2的时候就得到了欧氏距离。
4.曼哈顿距离
来源于美国纽约市曼哈顿区,因为曼哈顿是方方正正的。
二、损失函数
L1和L2都可以做损失函数使用。
1. L2损失函数
L2范数损失函数,也被称为最小平方误差(LSE)。它是把目标值 与估计值
的差值的平方和最小化。一般回归问题会使用此损失,离群点对次损失影响较大。
2. L1损失函数
也被称为最小绝对值偏差(LAD),绝对值损失函数(LAE)。总的说来,它是把目标值 与估计值
的绝对差值的总和最小化。
3. 二者对比
L1损失函数相比于L2损失函数的鲁棒性更好。
因为L2范数将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数大的多,因此模型会对这种类型的样本更加敏感,这就需要调整模型来最小化误差。但是很大可能这种类型的样本是一个异常值,模型就需要调整以适应这种异常值,那么就导致训练模型的方向偏离目标了。
三、正则化
1. 正则化为什么可以避免过拟合?
正规化是防止过拟合的一种重要技巧。
正则化通过降低模型的复杂性, 缓解过拟合。过拟合发生的情况,拟合函数的系数往往非常大,为什么?
如下图所示,就是过拟合的情况,拟合函数考虑到了每一个样本点,最终形成的拟合函数波动很大,也就是在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的系数非常大,就是模型中的w会很大。
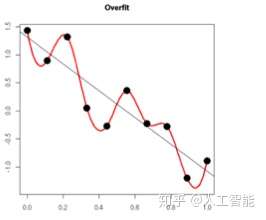
2. L1正则
L1正则常被用来进行特征选择,主要原因在于L1正则化会使得较多的参数为0,从而产生稀疏解,我们可以将0对应的特征遗弃,进而用来选择特征。一定程度上L1正则也可以防止模型过拟合。
假设 是未加正则项的损失,
是一个超参,控制正则化项的大小。
对应的损失函数:
3. L2正则
主要用来防止模型过拟合,直观上理解就是L2正则化是对于大数值的权重向量进行严厉惩罚。鼓励参数是较小值,如果 小于1,那么
会更小。
对应的损失函数:
4. 为什么L1会产生稀疏解
稀疏性:很多参数值为0。
1)梯度的方式:
对其中的一个参数 计算梯度,其他参数同理,
是步进,
是符号函数
>0,
=1;
<0,
=-1。
L1的梯度:
L2的梯度:
当 小于1的时候,L2的惩罚项会越来越小,而L1还是会非常大,所以L1会使参数为0,而L2很难。
2)图形的方式:
损失函数L与参数 的关系图,绿点是最优点。
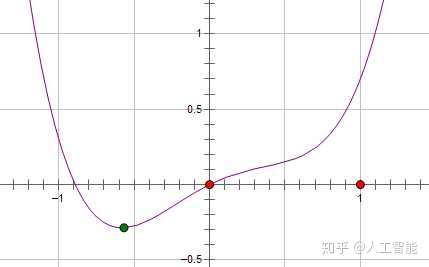
如果加上L2正则,损失函数L为 ,对应的函数是蓝线,最优点是黄点。
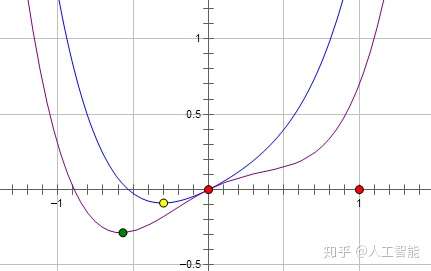
如果是加上L1损失,那么损失函数L是 ,对应的函数是粉线,最优点是红点,参数
变为0。
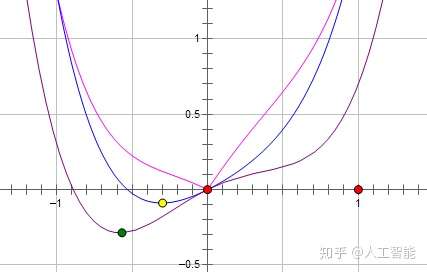
两种正则化,能不能将最优的参数变为0,取决于最原始的损失函数在0点处的导数,如果原始损失函数在0点处的导数 不为0,则加上L2正则化项
之后,导数依然不为0,说明在0这点不是极值点,最优值不在w=0处。
而施加 正则项时,导数在
这点不可导。不可导点是否是极值点,就是看不可导点左右的单调性。单调性可以通过这个点左、右两侧的导数符号判断,导数符号相同则不是极值点,左侧导数正,右侧导数负,则是极大值,左侧导数负,右侧导数正,极小值。
根据极值点判断原则, 左侧导数
,只要正则项的系数
大于
,那么左侧导数小于0,
右侧导数
,所以
就会变成一个极小值点,所以L1经常会把参数变为0,产生稀疏解。
