
Python实现单向无序链表(Singly linked list)
概念介绍
在计算机科学中,链表代表着一种多个数据元素的线性集合。链表的顺序不由其在内存中的物理位置决定,而是通过每一个元素指向另一个元素来实现。链表中,一个实体对象为一个节点(Node),每个节点同时保存其数据(data)和一个引用(reference)指向另一个节点。特别需要说明的是,链表这种数据类型必须有一个元素为链首元素(空链表除外)。
由于没有物理位置上的先后顺序(在内存中随机存储),链表与其他数据结构相比,随机读写(random access)更低效。而修改或删除链表中的节点却更高效(修改节点之间的指向)。
链表节点实现
首先是实现其节点数据类型,每个节点初始化时,传入数据属性(data),而next属性为指向下一个节点(默认为空)。然后实现每个属性的get和set方法。
class Node:
def __init__(self, init_data):
self.data = init_data
self.next = None
def get_data(self):
return self.data
def get_next(self):
return self.next
def set_data(self, new_data):
self.data = new_data
def set_next(self, new_next):
self.next = new_next
## 链表实现 ## 下面一一介绍链表的初始化,打印方法(print),插入,删除,增加,获取链表长度,检查是否为空等类方法。记住,链表中的每个元素为上面介绍的节点类。特别注意的是,该链表所代表的节点是无序的,即每个节点的数据成员没有按照大小顺序排序。下一篇博文将介绍有顺序的节点链表。 初始化构造方法构造一个空的链表,其链首节点为空。 ```Python class UnorderedList: def __init__(self): self.head = None ```
__str__方法的实现方式是:将链表中的节点从链首开始遍历,每个节点的数据成员(data)append进一个list,最后返回str(list)。 ```Python def __str__(self): print_list = [] current = self.head while current is not None: print_list.append(current.get_data()) current = current.get_next() return str(print_list) ```
查看是否为空时,直接检查链首节点是否为空即可。 ```Python def is_empty(self): return self.head is None ```
size方法同样是遍历链表,并使用count变量计数。 ```Python def size(self): current = self.head count = 0 while current is not None: count += 1 current = current.get_next() return count ```
以上是基本的查询大小,初始化,查看是否为空,打印等操作,不涉及到增删改查。下面来重点介绍链表的增删改查。方法有add(self, item):item为数据元素,可以用来构造Node类实例;remove(self, item):删除数据成员为item的指定节点;search(self, item):查找数据成员为item的指定节点;append(self, item):将数据成员为item的节点添加到链表尾部;index(self, item):类比Python的List对象,给链表中的节点标记索引;insert(self, pos, item):在指定位置插入数据成员为item的节点,pos同index方法的返回值;pop(self, index=None):参考List的pop方法,移除指定位置的节点并返回其数据成员。下面依次实现其API方法。
add方法很简单,构造以item为数据成员的Node实例,并将其指向链首节点temp.set_next(self.head),然后将temp节点赋值给链首节点。
def add(self, item):
temp = Node(item)
temp.set_next(self.head)
self.head = temp
remove方法的实现就有点复杂,比如有一个链表是如下图所示,我们要找到数据元素为17的节点,并将它删除,然后将剩下的链表重新连接起来。
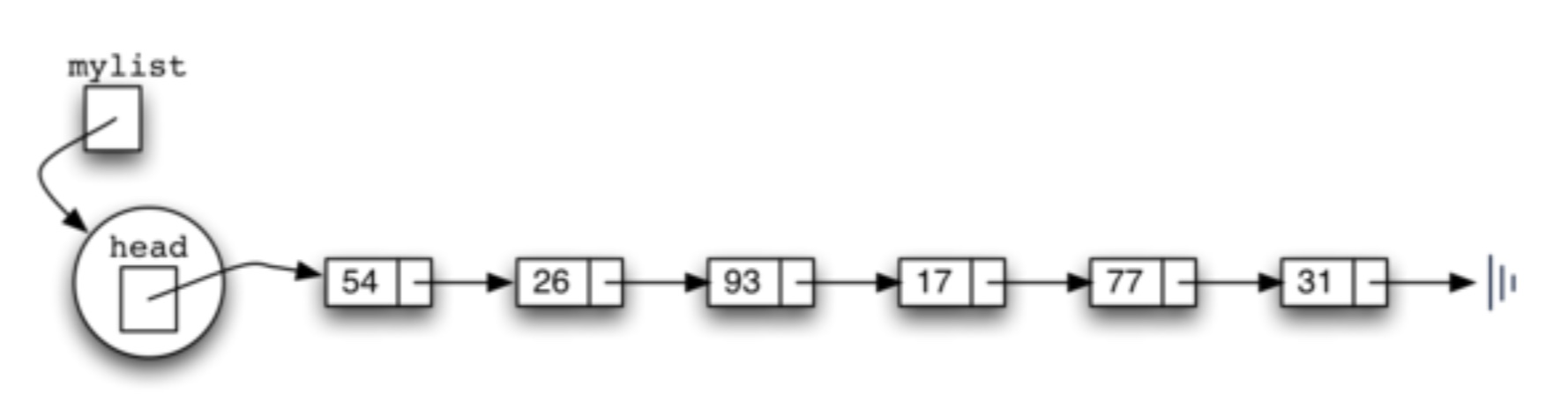
我们需要依次遍历每个节点,直到找到数据元素为17的节点,然后将17之前的节点和17之后的节点连接起来。17之后的节点可以用current.get_next()(current为当前节点,即为17所在的节点)方法,但17之前的节点却没有方法获取,因为我们没有set_previous的方法,且此时链表是单向的,从链首直到链尾。因此,可以用一个变量(previous)保存当前链表节点的前一个节点。每次移动当前链表时,当前链表的上一个链表也随之移动。如下图。
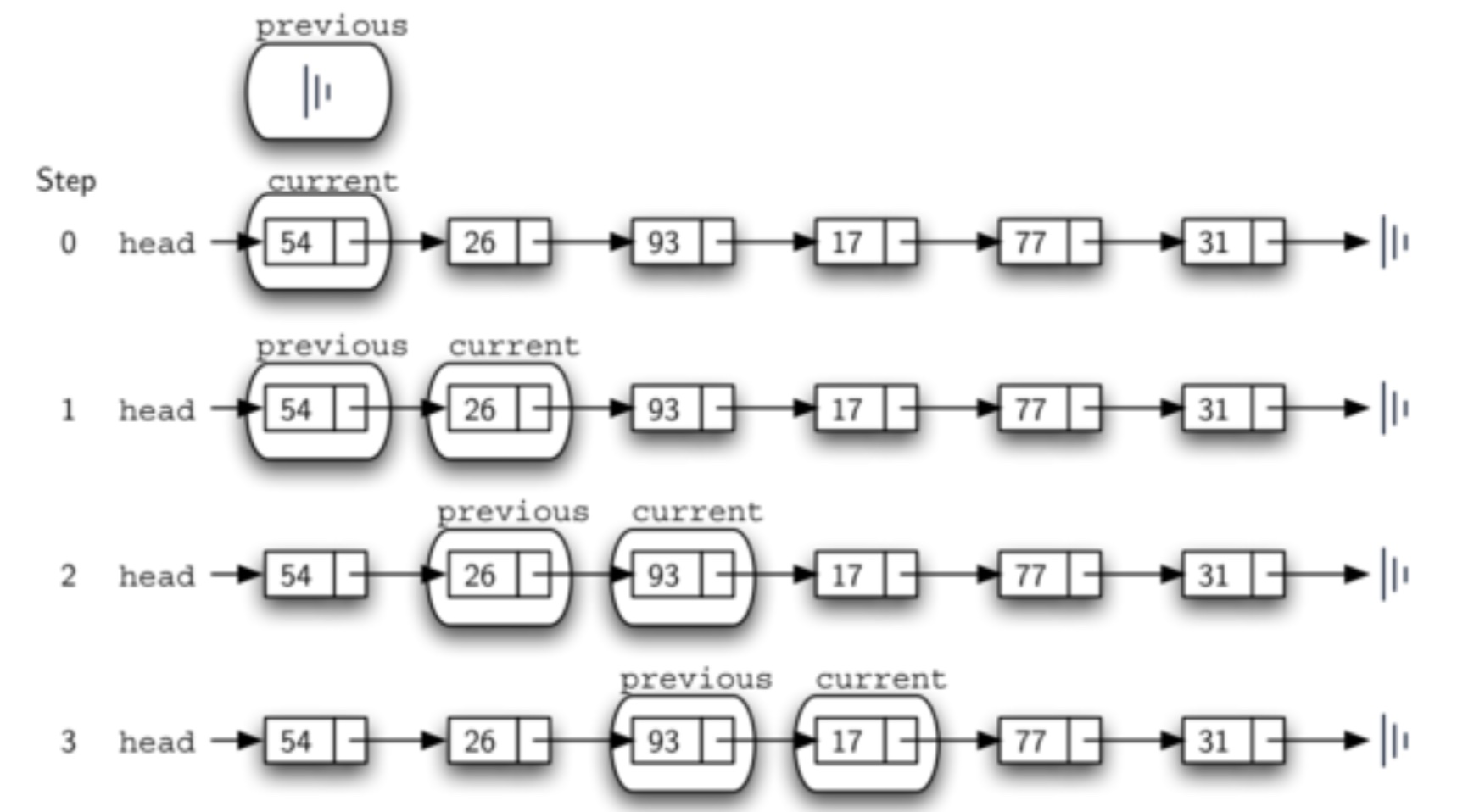
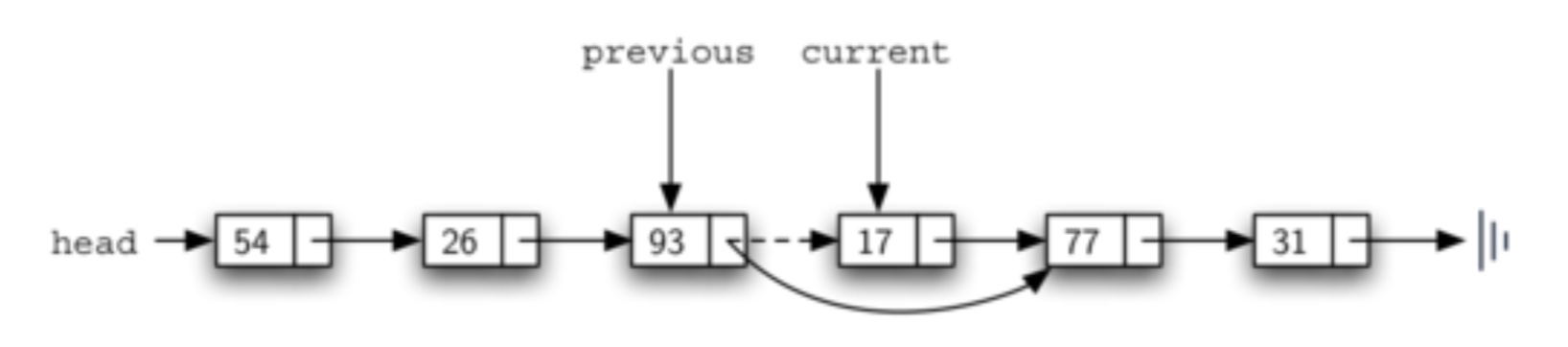
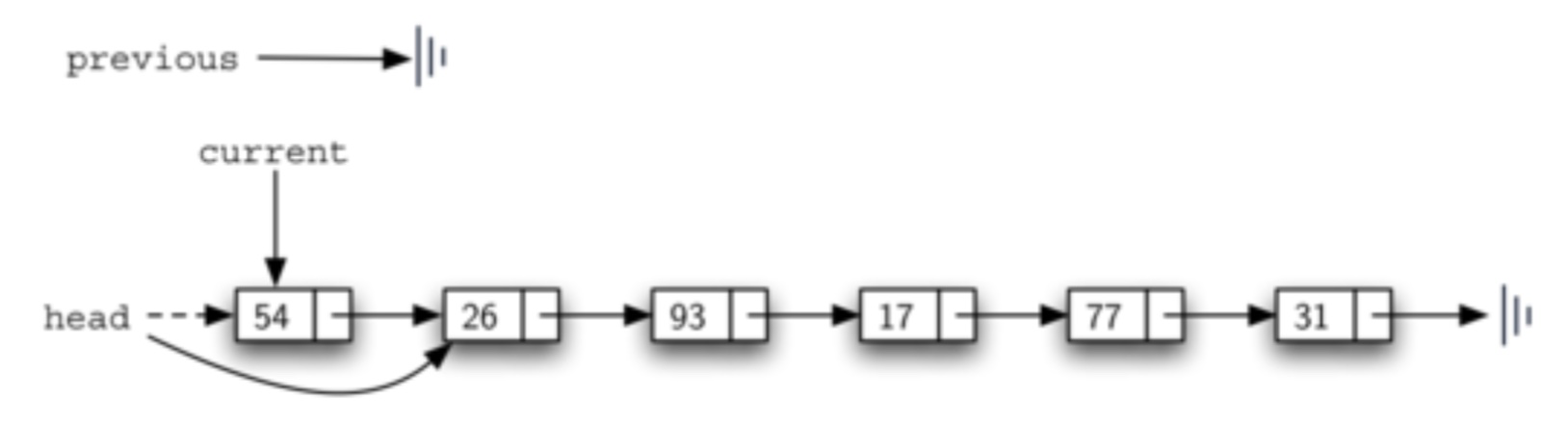
因此,实现方法如下面的代码,首先查找指定要移除的节点。若当前节点的上一个节点为None,则当前节点为链首节点,移除链首节点时,只需将链首节点赋值为当前节点的下一个节点,self.head = current.get_next()。
若当前节点的上一个节点(previous)不为空,则直接将previous的下一个节点设置为当前节点的下一个节点,改变previous的指向,则当前节点被移除,previous.set_next(current.get_next())。
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.get_data() == item:
found = True
else:
previous = current
current = current.get_next()
if previous is None:
self.head = current.get_next()
else:
previous.set_next(current.get_next())
search方法很简单,依次遍历链表各个节点,找到则返回True,否则为False。
def search(self, item):
current = self.head
while current is not None:
if current.get_data() == item:
return True
current = current.get_next()
return False
append方法是将指定数据成员为item的节点添加到链表尾部,若链表首部为空,则将self.head直接赋值为node;否则依次遍历各个节点,直至找到当前链表的尾部节点,将当前节点的下一个节点赋值为node,current.set_next(node)。
def append(self, item):
node = Node(item)
current = self.head
if current is None:
self.head = node
while current.get_next() is not None:
current = current.get_next()
current.set_next(node)
index方法是参考Python内置List的index,查找指定数据成员为item的节点所在链表的位置(仅作为标记使用,不表示内存中存储的先后关系)。用index变量保存索引值,每次遍历节点时,若未找到指定节点,则索引值+1,直到找到便返回。
def index(self, item):
index = 0
current = self.head
while current is not None:
if current.get_data() == item:
return index
current = current.get_next()
index += 1
return -1
insert方法同样参考List,在指定索引值处插入数据成员为item的节点。值得注意的是,若链表中有n个节点,则可插入的位置为n+1。同样是遍历链表,若pos == 0,则在链首位置插入节点,node.set_next(self.head), self.head = node实现其功能。若pos != 0,则需要引入当前节点的上一个节点,用变量previous代表(同remove)。实现方式类似remove,不再过多解释。
def insert(self, pos, item):
node = Node(item)
if pos == 0:
node.set_next(self.head)
self.head = node
else:
current = self.head
previous = None
while self.index(current.get_data()) != pos:
previous = current
current = current.get_next()
if current is None:
break
previous.set_next(node)
node.set_next(current)
pop的实现则更为复杂,index默认不给参数时,pop方法默认移除链表尾部节点。其次需要考虑index值为负数的情况(同List中的index效果),以及index out of range的情况。若index超出范围,则直接抛出异常。首先若index == None,则将index的值赋值为self.size() - 1(代表移除最后一个元素)。若index为负数,则将其转换为正数代表的索引位置。最后检查index是否在范围内,不在就抛出IndexError。
确定完index的有效值后,开始遍历节点,同样需要考虑只有链首节点的情况。
def pop(self, index=None):
if index is None:
index = self.size() - 1
if index < 0:
index = self.size() - abs(index)
if index < 0 or (index >= self.size()):
raise IndexError
current = self.head
previous = None
while self.index(current.get_data()) != index:
previous = current
current = current.get_next()
item = current.get_data()
if previous is None:
self.head = current.get_next()
else:
previous.set_next(current.get_next())
return item
总结:通过实现链表的增删改查,可以了解基础数据类型的实现方式,以及其在各个方面的优势和劣势,如增删以及random access等。值得注意的是,虽然链表在增删操作上有优势,但要查找到指定元素,仍然没有普通的List快。查找需要依次遍历各个节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号