
过滤序列中的元素
序列中的数据,经常需要提取特定条件的数据,或减少序列中的数据。
常用的方式是使用列表生成式(list comprehension),如下:
>>> mylist = [1, 4, -5, 10, -7, 2, 3, -1]
>>> [n for n in mylist if n > 0]
[1, 4, 10, 2, 3]
>>> [n for n in mylist if n < 0]
[-5, -7, -1]
用列表生成式的一个弊端是,如果原始输入很大,它可能会产生一个很大的list,比较占用内存。 如果这是一个问题,可以使用生成器表达式(generator expression)迭代生成过滤值。如下:
>>> pos = (n for n in mylist if n > 0)
>>> pos
<generator object <genexpr> at 0x10d6a4750>
>>> for i in pos:
... print(i)
...
1
4
10
2
3
有些时候,过滤条件比价复杂,难以使用简单的列表生成式或生成器表达式来过滤。比如说,过滤条件涉及到异常的处理或其他更复杂的情形。对于以上情况,我们可以将过滤条件的代码放在单独的函数中,然后使用内置的filter()。如下所示:
values = ['1', '2', '-3', '-', '4', 'N/A', '5']
def is_int(val):
try:
x = int(val)
return True
except ValueError:
return False
ivals = list(filter(is_int, values))
print(ivals)
# Outputs ['1', '2', '-3', '4', '5']
filter()构造了一个迭代器,可以转化为list或tuple等。
列表生成式和生成器表达式是最简单的过滤序列元素的方式,在过滤的同时,也可以进行数据的重新构造和转换。如下:
>>> mylist = [1, 4, -5, 10, -7, 2, 3, -1]
>>> import math
>>> [math.sqrt(n) for n in mylist if n > 0]
[1.0, 2.0, 3.1622776601683795, 1.4142135623730951, 1.7320508075688772]
>>>
过滤的一种变体涉及用新值替换不符合标准的值而不是丢弃它们,如下:
>>> clip_neg = [n if n > 0 else 0 for n in mylist]
>>> clip_neg
[1, 4, 0, 10, 0, 2, 3, 0]
>>> clip_pos = [n if n < 0 else 0 for n in mylist]
>>> clip_pos
itertools模块提供了一个compress()函数,也可以用于过滤序列元素。
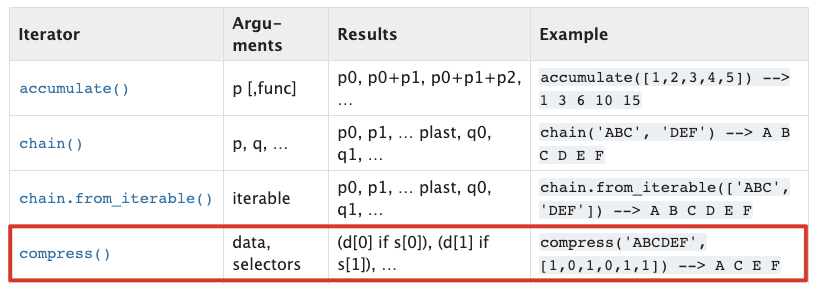
函数参数为一个迭代器对象,一个Boolean过滤选择器序列。作为输出,它提供了其中选择器中的相应元素为True的那些元素。如果你尝试将一个序列的过滤结果应用于另一个相关序列,这可能很有用。如下所示:
>>> addresses = [
... '5412 N CLARK',
... '5148 N CLARK',
... '5800 E 58TH',
... '2122 N CLARK',
... '5645 N RAVENSWOOD',
... '1060 W ADDISON',
... '4801 N BROADWAY',
... '1039 W GRANVILLE',
... ]
counts = [ 0, 3, 10, 4, 1, 7, 6, 1]
>>> from itertools import compress
>>> more5 = [n > 5 for n in counts]
>>> more5
[False, False, True, False, False, True, True, False]
>>> list(compress(addresses, more5))
['5800 E 58TH', '1060 W ADDISON', '4801 N BROADWAY']
>>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号