kafka
1 Kafka是什么?
是 一个分布式流处理平台.
我们知道流处理平台有以下三种特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
Kafka适合什么样的场景?
(1)“削峰填谷”。所谓的“削峰填谷”就是指缓冲上下游瞬时突发流量,使其更平滑。
(2)解耦,即允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(3)异步通信,即允许把一个消息放入队列,但并不立即处理它们,然后再需要的时候才去处理它们。
具体名词术语
- 消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
- 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
- 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
- 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
- 副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
- 生产者:Producer。向主题发布新消息的应用程序。
- 消费者:Consumer。从主题订阅新消息的应用程序。
- 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
- 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
- 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
概念
- Kafka作为一个集群,运行在一台或者多台服务器上.
- Kafka 通过 topic 对存储的流数据进行分类。
- 每条记录中包含一个key,一个value和一个timestamp(时间戳)。
Kafka有四个核心的API:
- The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
- The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
- The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
总体架构
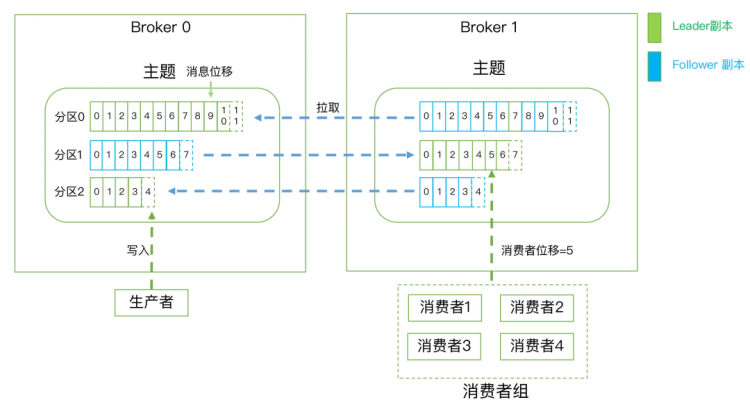
- 一个主题有多个分区(叫消息划分成多个部分)
- 一个分区有多个副本(在不同服务器上)
- 一个分区有一个领导者副本和多个跟随着副本(分布在不同的broker服务器内)
- 生产者将消息安装轮询或者键值对(hash)的方式存入不同分区
- Kafka提出了消费组的概念,多个消费者实例共同组成的一个组,组内每个消费者并行消费以实现高吞吐。
- 注意一个分区只会由组内固定的一个消费者进行消费。
- 维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
- Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。
- 每条消息记录会广播到所有的消费组.
- follower制作冗余,不提供服务。只有等Leader挂掉之后,follower才有机会成为leader提供服务。
- 消费者实例可以分布在多个进程中或者多个机器上。
- 但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息。
写入流程
- 创建一条记录,记录中一个要指定对应的topic和value,key和partition可选。 先序列化,然后按照topic和partition,放进对应的发送队列中。kafka produce都是批量请求,会积攒一批,然后一起发送,不是调send()就进行立刻进行网络发包。发送到partition分为两种情况(指定了key,按照key进行哈希,相同key去一个partition。没有指定key,round-robin来选partition)
- 生产者将消息发送至该 partition leader。之后生产者会根据设置的 request.required.acks 参数不同,选择等待或或直接发送下一条消息。
request.required.acks = 0 表示 Producer 不等待来自 Leader 的 ACK 确认,直接发送下一条消息。在这种情况下,如果 Leader 分片所在服务器发生宕机,那么这些已经发送的数据会丢失。
request.required.acks = 1 表示 Producer 等待来自 Leader 的 ACK 确认,当收到确认后才发送下一条消息。在这种情况下,消息一定会被写入到 Leader 服务器,但并不保证 Follow 节点已经同步完成。所以如果在消息已经被写入 Leader 分片,但是还未同步到 Follower 节点,此时Leader 分片所在服务器宕机了,那么这条消息也就丢失了,无法被消费到。
request.required.acks = -1 表示 Producer 等待来自 Leader 和所有 Follower 的 ACK 确认之后,才发送下一条消息。在这种情况下,除非 Leader 节点和所有 Follower 节点都宕机了,否则不会发生消息的丢失。
消费流程
消息有生产者发布到kafka集群后,会被消费者消费。
kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息。如下图所示,有两个消费者(不同消费者组)拉取同一个主题的消息,消费者A的消费进度是3,消费者B的消费进度是6。消费者拉取的最大上限通过最高水位(watermark)控制,生产者最新写入的消息如果还没有达到备份数量,对消费者是不可见的。这种由消费者控制偏移量的优点是:消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费。
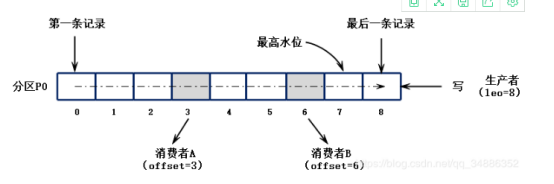
Kafka的做法是生产者发布的所有消息会一致保存在Kafka集群中,不管消息有没有被消费。用户可以通过设置保留时间来清理过期的数据,比如,设置保留策略为两天。那么,在消息发布之后,它可以被不同的消费者消费,在两天之后,过期的消息就会自动清理掉。
消费组与分区重平衡
可以看到,当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为重平衡(rebalance)。重平衡是 Kafka 一个很重要的性质,这个性质保证了高可用和水平扩展。不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。后面我们会讨论如何安全的进行重平衡以及如何尽可能避免。
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的 broker 来保持在消费组内存活。
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;
在 0.10.1 版本,Kafka 对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。另外更高版本的 Kafka 支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
持久化
Kafka 对消息的存储和缓存严重依赖于文件系统。kafka建立在简单的读取和向文件后追加两种操作之上,这和日志解决方案相同。
这有着明显的性能优势,由于性能和数据大小完全分离开来——服务器现在可以充分利用大量廉价、低转速的1+TB SATA硬盘。
为什么使用文件系统?
- 文件系统在一定的条件下足够快
性能约为600MB/秒,但随机写入的性能仅约为100k/秒,相差6000倍以上。
操作系统对文件系统进行了大量的优化。
现代操作系统提供了 read-ahead 和 write-behind 技术,read-ahead 是以大的 data block 为单位预先读取数据,而 write-behind 是将多个小型的逻辑写合并成一次大型的物理磁盘写入。
- 文件系统不会对gc产生负担
Kafka 建立在 JVM 之上,任何了解 Java 内存使用的人都知道两点:
- 对象的内存开销非常高,通常是所存储的数据的两倍(甚至更多)。
- 随着堆中数据的增加,Java 的垃圾回收变得越来越复杂和缓慢。
受这些因素影响,相比于维护 in-memory cache 或者其他结构,使用文件系统和 pagecache 显得更有优势.
- 存储紧凑的字节结构而不是独立的对象,有望将缓存容量再翻一番
- 不会产生额外的 GC 负担
- 服务重新启动,缓存依旧可用
- 所有保持 cache 和文件系统之间一致性的逻辑现在都被放到了 OS 中,这样做比一次性的进程内缓存更准确、更高效
kafka给出了一个非常简单的设计:相比于维护尽可能多的 in-memory cache,并且在空间不足的时候匆忙将数据 flush 到文件系统,我们把这个过程倒过来。所有数据一开始就被写入到文件系统的持久化日志中(先写入page cache再写入系统),而不用在 cache 空间不足的时候 flush 到磁盘。实际上,这表明数据被转移到了内核的 pagecache 中。
page cache,又称pcache,其中文名称为页高速缓冲存储器,简称页高缓。page cache的大小为一页,通常为4K。在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。
高效性
- 使用顺序读写
- 小型 I/O 操作.
为了避免这种情况,kafka是建立在一个 “消息块” 的抽象基础上,合理将消息分组。 这使得网络请求将多个消息打包成一组,而不是每次发送一条消息,从而使整组消息分担网络中往返的开销。
- 高效的字节拷贝。kafka采用sendfile方式减少用户态和核心态的切换,减少一次cpu拷贝。
总结
kafa是一个专门面向消息队列,日志,流处理平台的框架,根据数据线性读写的特性,采用多种适合的设计,所打造的高效和高可用的系统。主要涉及如下:
- 将一个topic划分多个分区,并且不同分区可以交给不同的消费者处理(分流,保证高效性),每个分区有多个备份在不同的broker(保证可靠性)。
- 将多个消息组成“消息块”,减少网络往返的开销。
- 采用零拷贝技术sendfile减少拷贝和操作系统状态的切换。
- 采用文件系统避免频繁的gc
随笔(错漏百出,博君一笑):
一个系统业务如何高效一般有下面几种手段:
分流:例子,增加车道,可以快速减少拥堵。(分区和消费组)
分工:例子,采用dma 专门处理数据传输。(心跳broker)
整合:例子,将多个快递汇聚成一车发送,减少处理的数量。(消息块)
升级:例子,坐火车改为做飞机。(sendfile)
缩减:例子, 减少没必要的包装。(文件系统)
优化:例子,高峰期采用排队进。(顺序读写)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号