Spark API 之 combineByKey(一)
1 前言
combineByKey是使用Spark无法避免的一个方法,总会在有意或无意,直接或间接的调用到它。从它的字面上就可以知道,它有聚合的作用,对于这点不想做过多的解释,原因很简单,因为reduceByKey、aggregateByKey、foldByKey等函数都是使用它来实现的。
combineByKey是一个高度抽象的聚合函数,可以用于数据的聚合和分组,由它牵出的shuffle也是Spark中重中之重,现在就让我们去看看它到底是怎么去实现的。
不足或错误之处, 烦请指出更正。
2 方法源码介绍
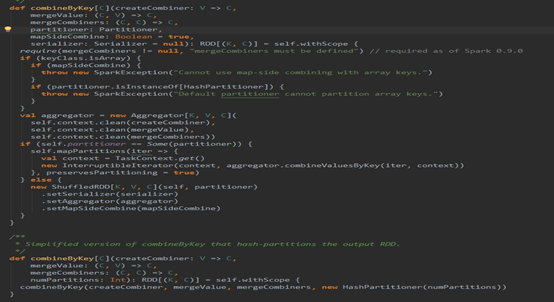
这是PairRDDFunctions里面的combineByKey的方法片段,这两个方法放在一块,就是说明了,调用该方法若不填分区函数Partitioner则使用HashPartitioner,默认情况下会使用Map段合并(这个是对shuffle而言的)。
3 方法源码走读
废话不多说,直接贴源码,
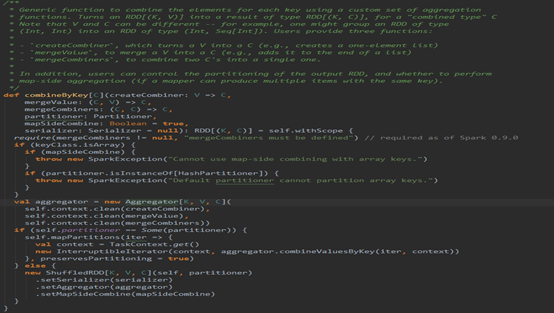
有注释,则看注释,注释要表达的意思就是combineByKey是一个范函数,使用一组自定义聚合函数以Key为聚合条件进行聚合,至于其他的就不多说了,往下看代码。
首先就进行了判断,Key是否为数组,假如是数组则不能使用Map段合并和HashPartitioner,原因:
要想进行Map段合并和Hash分区,那么Key就必须可以通过比较内容是否相同来确定Key是否相等以及通过内容计算hash值,进而进行合并和分区,然而数组判断相等和计算hash值并不是根据它里面的内容,而是根据数组在堆栈中的信息来实现的。
接着往下,构造了一个Aggregator,这玩意可以说是combineByKey的核心,因为聚合全是交给它来完成的。进去看看下Aggregator。

上面是Aggregator的默认构造器,需要传入三个自定义的方法,现在重点说说这三个方法的意义:
首先紧跟着Aggregator的三个泛型,第一个K,这个是你进行combineByKey也就是聚合的条件Key,可以是任意类型。后面的V,C两个泛型是需要聚合的值的类型,和聚合后的值的类型,两个类型是可以一样,也可以不一样,例如,Spark中用的多的reduceByKey这个方法,若聚合前的值为long,那么聚合后仍为long。再比如groupByKey,若聚合前为String,那么聚合后为Iterable<String>。
再看三个自定义方法:
- createCombiner
这个方法会在每个分区上都执行的,而且只要在分区里碰到在本分区里没有处理过的Key,就会执行该方法。执行的结果就是在本分区里得到指定Key的聚合类型C(可以是数组,也可以是一个值,具体还是得看方法的定义了。)
2. mergeValue
这方法也会在每个分区上都执行的,和createCombiner不同,它主要是在分区里碰到在本分区内已经处理过的Key才执行该方法,执行的结果就是将目前碰到的Key的值聚合到已有的聚合类型C中。
其实方法1和2放在一起看,就是一个if判断条件,进来一个Key,就去判断一下若以前没出现过就执行方法1,否则执行方法2.
3. mergeCombiner
前两个方法是实现分区内部的相同Key值的数据合并,而这个方法主要用于分区间的相同Key值的数据合并,形成最终的结果。
接下来就看看Aggregator实现了哪些方法。
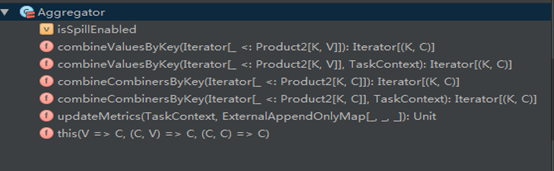
从它的方法列表上来看,其实就它只有三个方法,那就依次来看看这三个方法是干嘛的:
- combineValuesByKey
看到这个名字,再根据构造器,就可以猜出,这个方法主要实现的就是分区内部的数据合并。看它的代码:
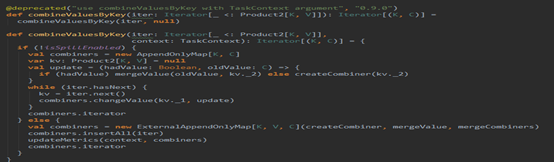
这里根据是否可以刷磁盘分了两条路,其实做的事情都是一样的,区别是在存储数据的时候一个当内存不够是直接oom,一个是可以刷磁盘。代码的实现很简单,就是迭代一个分区的数据,然后不断插入或更新Map里面的数据,这里就不再细说。
2. combineCombinersByKey
这个方法主要是实现分区间的数据合并,也就是合并combineValuesByKey的结果,看它是怎么实现的:

代码就不说了,和combineValuesByKey如出一辙,只是使用的自定义的方法不同而已。
3. updateMetrics
这个方法和刷磁盘有关,

就是记录下,当前是否刷了磁盘,刷了多少。
到这里Aggregator就结束了,接着combineByKey往下。
实例化Aggregator后,接着就是判断,是否需要重新分区(shuffle):
- 不需要分区
当self.partitioner == Some(partitioner)时,也就是分区实例是同一个的时候,就不需要分区了,因此只需要对先用的分区进行combineValuesByKey操作就好了,没有分区间的合并了,也不需要shuffle了。
2. 需要分区
两个分区器不一样,需要对现在分区的零散数据按Key重新分区,目的就是在于将相同的Key汇集到同一个分区上,由于数据分布的不确定性,因此有可能现在的每个分区的数据是由重新分区后的所有分区的部分数据构成的(宽依赖),因此需要shuffle,则构建ShuffledRDD,
其实到这里,我们就应该意识到,combineByKey的关键在于分区器partitioner,它是针对分区的一个操作,分区器的选择就决定了执行combineByKey后的结果,如果所给的分区器不能保证相同的Key值被分区到同一个分区,那么最终的合并的结果可能存在多个分区里有相同的Key。
Shuffle的目的就是将零散于所有分区的数据按Key分区并集中。
需要shuffle的部分下部分再细说。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号