常用内置函数、三元运算、递归
常用内置函数
abs/round/sum
>>> abs(1) >>> abs(-1) # 求绝对值 >>> round(1.234,2) 1.23 >>> round(1.269,2) # 四舍五入 1.27 >>> sum([1,2,3,4]) >>> sum((1,3,5,7)) # 接收数字组成的元组/列表
>>> def func():pass >>> callable(func) # 判断一个变量是否可以调用 函数可以被调用 True >>> a = 123 # 数字类型a不能被调用 >>> callable(a) False >>> chr(97) # 将一个数字转换成一个字母 'a' >>> chr(65) 'A' >>> dir(123) # 查看数字类型中含有哪些方法 ['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes'] >>> dir('abc') ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
eval/exec
>>> eval('1+2-3*4/5') # 执行字符串数据类型的代码并且将值返回 0.6000000000000001 >>> exec('print(123)') # 执行字符串数据类型的代码但没有返回值 123
enumerate
>>> enumerate(['apple','banana'],1) # 会给列表中的每一个元素拼接一个序号 <enumerate object at 0x113753fc0> >>> list(enumerate(['apple','banana'],1)) [(1, 'apple'), (2, 'banana')]
max/min
>>> max(1,2,3,) # 求最小值 3 >>> min(2,1,3) # 求最大值 1
sorted
将给定的可迭代对象进行排序,并生成一个有序的可迭代对象。
>>> sorted([1, 4, 5, 12, 45, 67]) # 排序,并生成一个新的有序列表 [1, 4, 5, 12, 45, 67]
还接受一个key参数和reverse参数。
>>> sorted([1, 4, 5, 12, 45, 67], reverse=True)
[67, 45, 12, 5, 4, 1]
list1 = [ {'name': 'Zoe', 'age': 30}, {'name': 'Bob', 'age': 18}, {'name': 'Tom', 'age': 22}, {'name': 'Jack', 'age': 40}, ] ret = sorted(list1, key=lambda x: x['age']) print(ret) # [{'name': 'Bob', 'age': 18}, {'name': 'Tom', 'age': 22}, {'name': 'Zoe', 'age': 30}, {'name': 'Jack', 'age': 40}]
zip
zip函数接收一个或多个可迭代对象作为参数,最后返回一个迭代器:
>>> x = ["a", "b", "c"] >>> y = [1, 2, 3] >>> a = list(zip(x, y)) # 合包 >>> a [('a', 1), ('b', 2), ('c', 3)] >>> b =list(zip(*a)) # 解包 >>> b [('a', 'b', 'c'), (1, 2, 3)]
zip(x, y) 会生成一个可返回元组 (m, n) 的迭代器,其中m来自x,n来自y。 一旦其中某个序列迭代结束,迭代就宣告结束。 因此迭代长度跟参数中最短的那个序列长度一致。
>>> x = [1, 3, 5, 7, 9] >>> y = [2, 4, 6, 8] >>> for m, n in zip(x, y): ... print(m, n) ... 2 4 6 8
如果上面不是你想要的效果,那么你还可以使用 itertools.zip_longest() 函数来代替这个例子中的zip。
>>> from itertools import zip_longest >>> x = [1, 3, 5, 7, 9] >>> y = [2, 4, 6, 8] >>> for m, n in zip_longest(x, y): ... print(m, n) ... 2 4 6 8 None
zip其他常见应用:
>>> keys = ["name", "age", "salary"] >>> values = ["Andy", 18, 50] >>> d = dict(zip(keys, values)) >>> d {'name': 'Andy', 'age': 18, 'salary': 50}
map
map()接收两个参数func(函数)和seq(序列,例如list)。如下图:
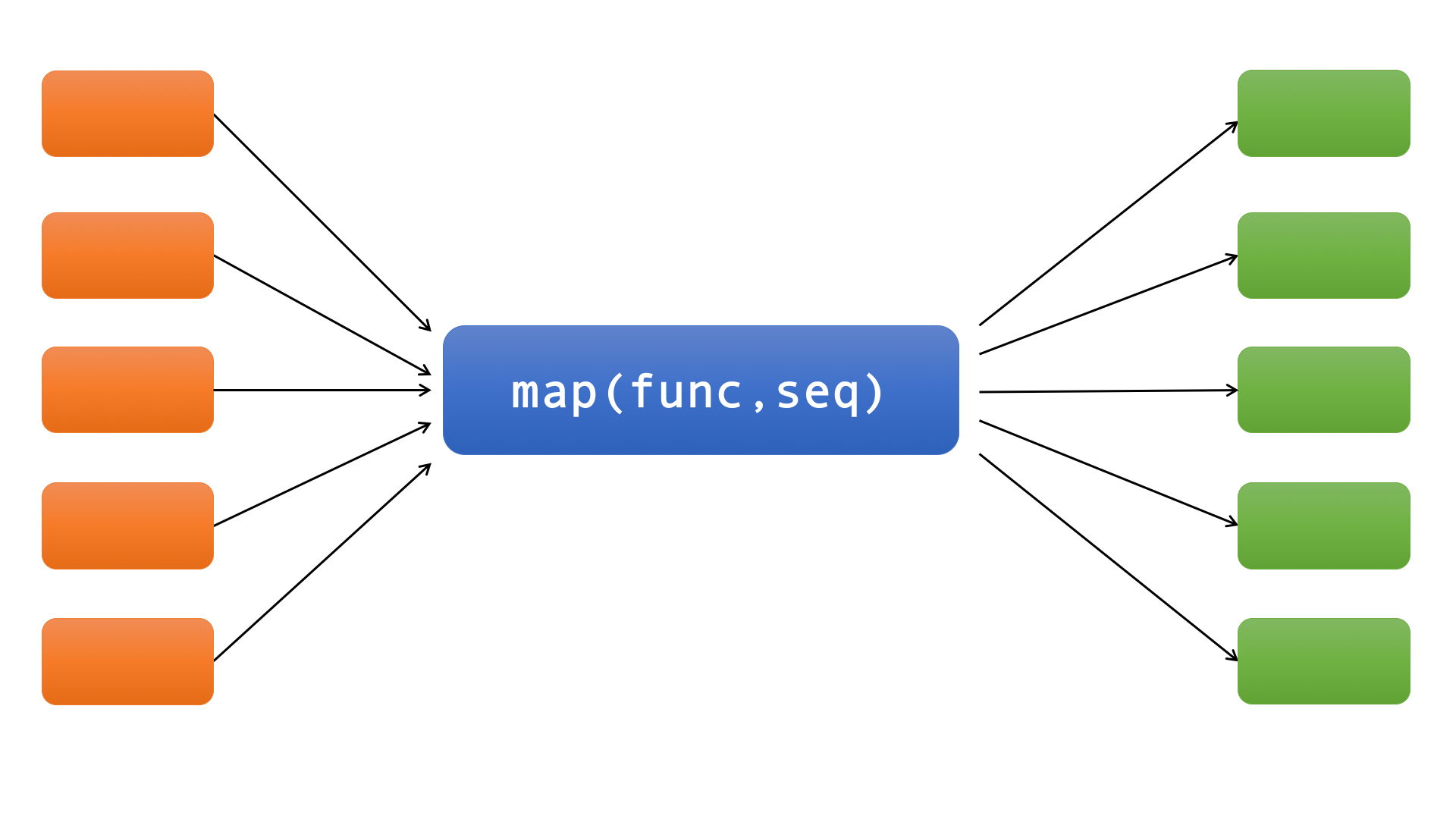
map()将函数func应用于序列seq中的所有元素。在Python3之前,map()返回一个列表,列表中的每个元素都是将列表或元组“seq”中的相应元素传入函数func返回的结果。Python 3中map()返回一个迭代器。
因为map()需要一个函数作为参数,所以可以搭配lambda表达式很方便的实现各种需求。
例子1:将一个列表里面的每个数字都加100:
>>> l = [11, 22, 33, 44, 55] >>> list(map(lambda x:x+100, l)) [111, 122, 133, 144, 155]
例子2:
使用map就相当于使用了一个for循环,我们完全可以自己定义一个my_map函数:
def my_map(func, seq): result = [] for i in seq: result.append(func(i)) return result
测试一下我们自己的my_map函数:
>>> def my_map(func, seq): ... result = [] ... for i in seq: ... result.append(func(i)) ... return result ... >>> l = [11, 22, 33, 44, 55] >>> list(my_map(lambda x:x+100, l)) [111, 122, 133, 144, 155]
我们自定义的my_map函数的效果和内置的map函数一样。
当然在Python3中,map函数返回的是一个迭代器,所以我们也需要让我们的my_map函数返回一个迭代器:
def my_map(func, seq): for i in seq: yield func(i)
测试一下:
>>> def my_map(func, seq): ... for i in seq: ... yield func(i) ... >>> l = [11, 22, 33, 44, 55] >>> list(my_map(lambda x:x+100, l)) [111, 122, 133, 144, 155]
与我们自己定义的my_map函数相比,由于map是内置的因此它始终可用,并且始终以相同的方式工作。它也具有一些性能优势,通常会比手动编写的for循环更快。当然内置的map还有一些高级用法:
例如,可以给map函数传入多个序列参数,它将并行的序列作为不同参数传入函数:
拿pow(arg1, arg2)函数举例,
>>> pow(2, 10) >>> pow(3, 11) >>> pow(4, 12) >>> list(map(pow, [2, 3, 4], [10, 11, 12])) [1024, 177147, 16777216]
filter
filter函数和map函数一样也是接收两个参数func(函数)和seq(序列,如list),如下图:
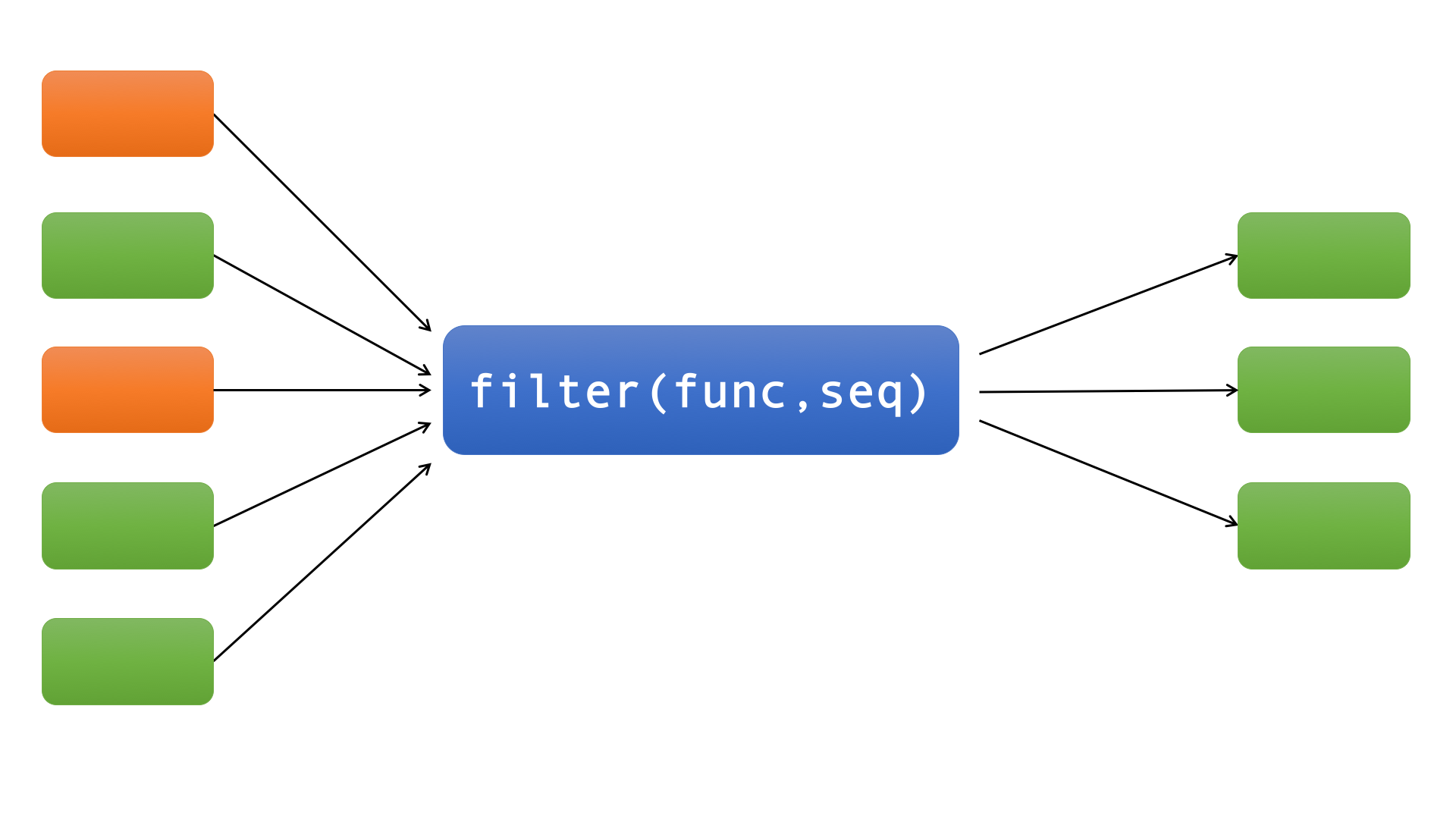
filter函数类似实现了一个过滤功能,它过滤序列中的所有元素,返回那些传入func后返回True的元素。也就是说filter函数的第一个参数func必须返回一个布尔值,即True或者False。
下面这个例子,是使用filter从一个列表中过滤出大于33的数:
>>> l = [30, 11, 77, 8, 25, 65, 4] >>> list(filter(lambda x: x>33, l)) [77, 65]
利用filter()还可以用来判断两个列表的交集:
>>> x = [1, 2, 3, 5, 6] >>> y = [2, 3, 4, 6, 7] >>> list(filter(lambda a: a in y, x)) [2, 3, 6]
补充:reduce
reduce
注意:Python3中reduce移到了functools模块中,你可以用过from functools import reduce来使用它。
reduce同样是接收两个参数:func(函数)和seq(序列,如list),如下图:
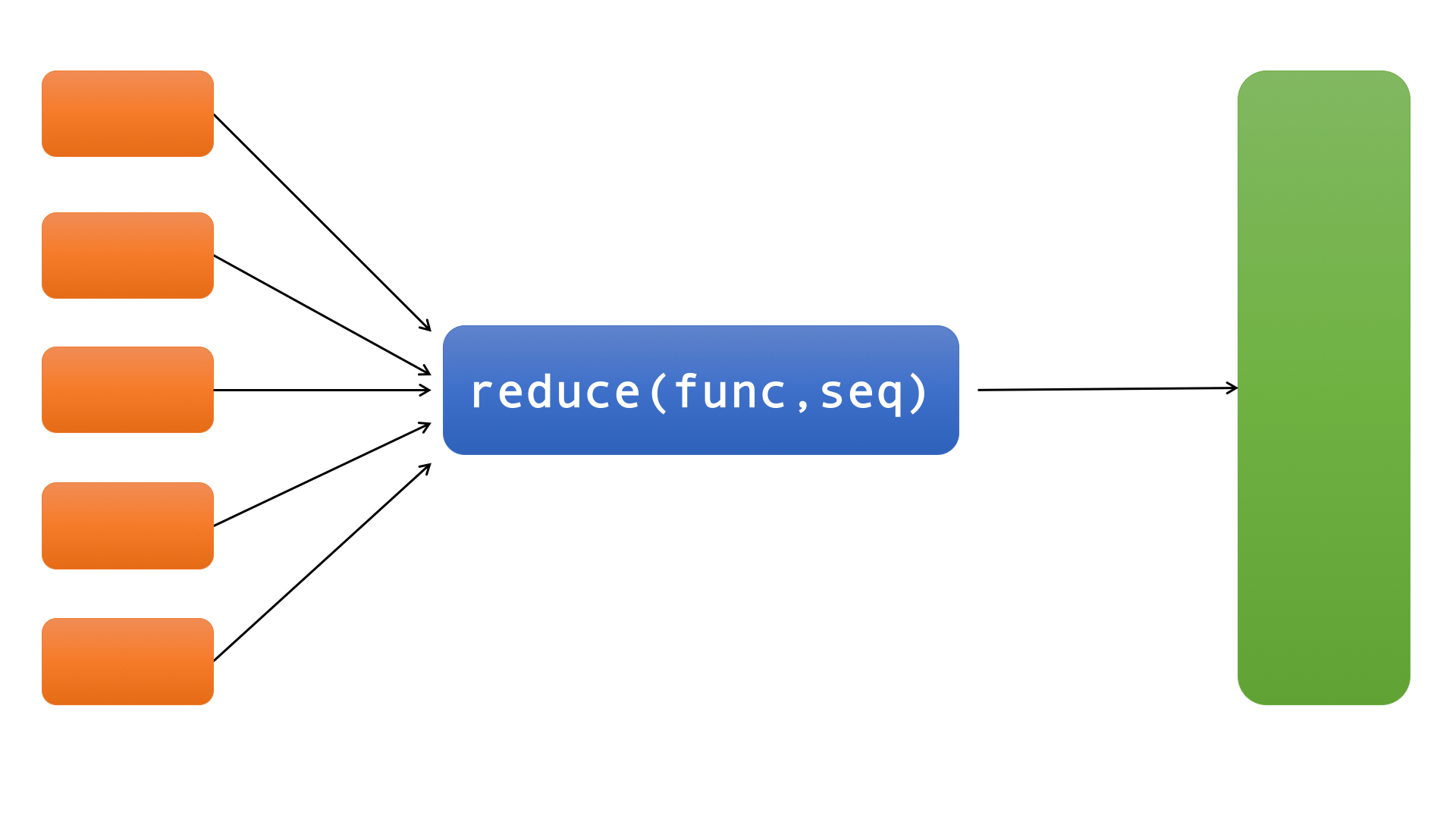
reduce最后返回的不是一个迭代器,它返回一个值。
reduce首先将序列中的前两个元素,传入func中,再将得到的结果和第三个元素一起传入func,…,这样一直计算到最后,得到一个值,把它作为reduce的结果返回。
原理类似于下图:

看一下运行结果:
>>> from functools import reduce >>> reduce(lambda x,y:x+y, [1, 2, 3, 4]) 10
再来练习一下,使用reduce求1~100的和:
>>> from functools import reduce >>> reduce(lambda x,y:x+y, range(1, 101)) 5050
lambda
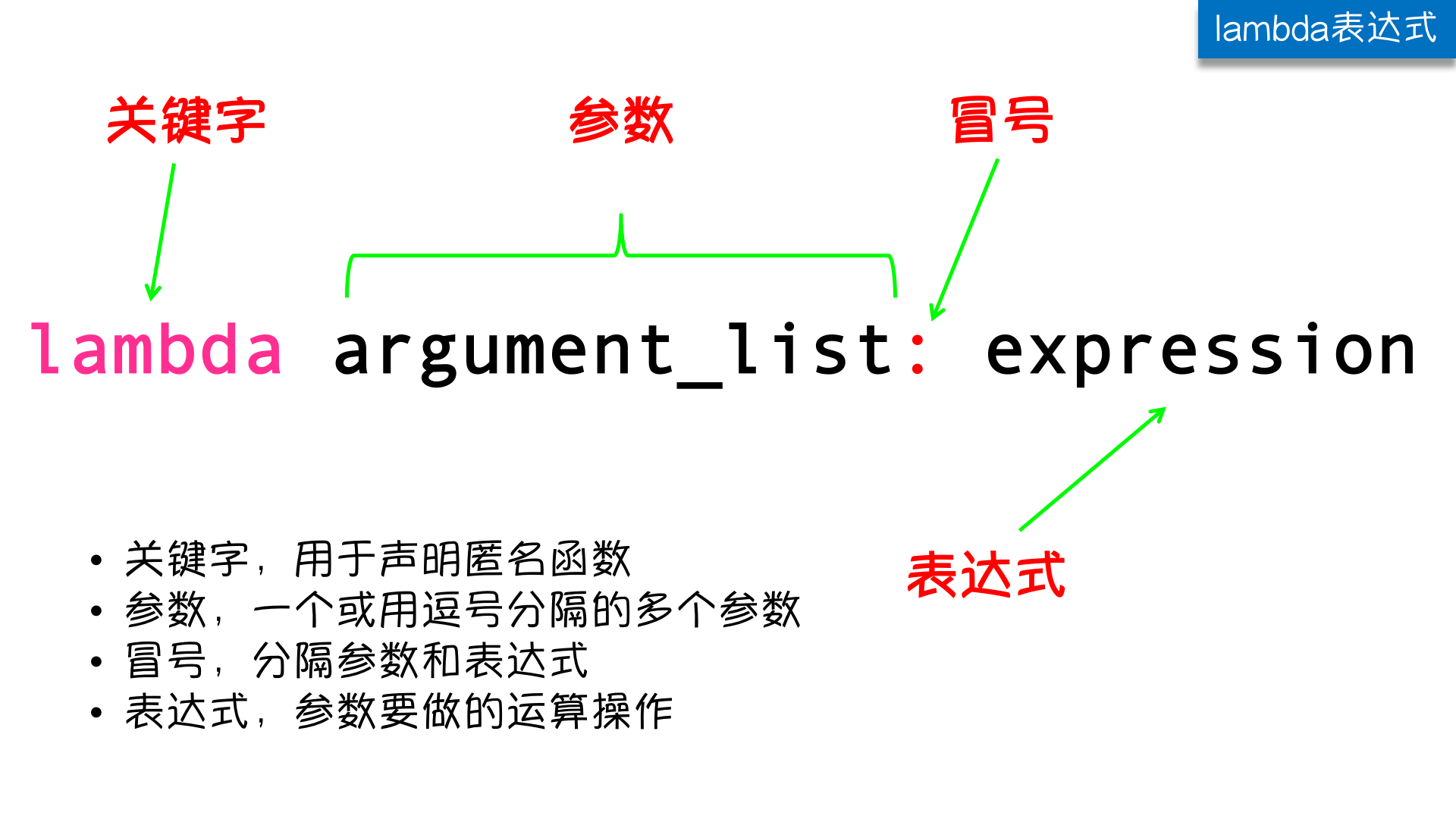
lambda是匿名函数,也就是没有名字的函数。lambda的语法非常简单:
直白一点说:为了解决那些功能很简单的需求而设计的一句话函数
注意:
使用lambda表达式并不能提高代码的运行效率,它只能让你的代码看起来简洁一些。
#这段代码 def func(x, y): return x + y#换成匿名函数 lambda x, y:x+y
ambda表达式和定义一个普通函数的对比:
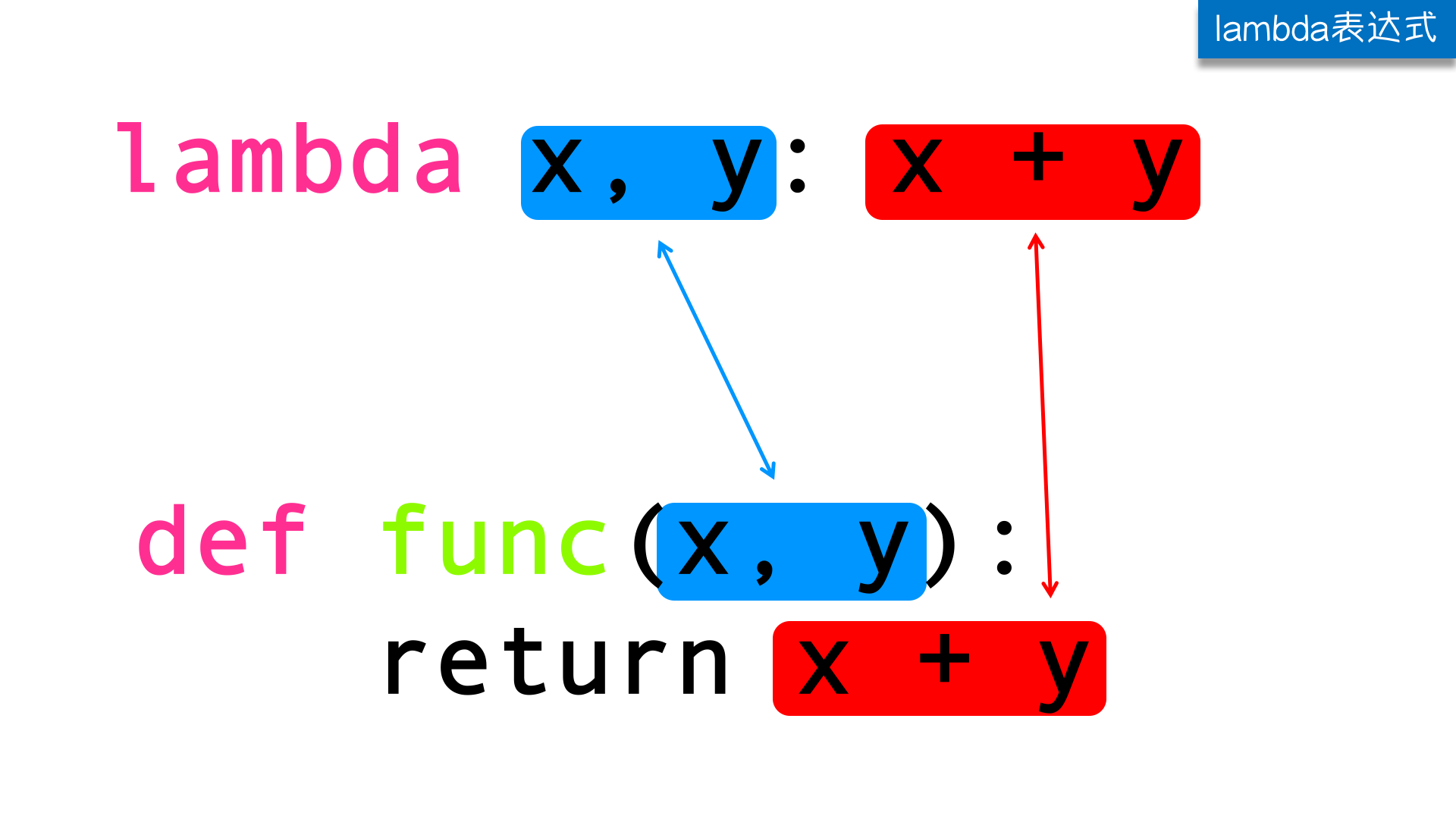
我们可以将匿名函数赋值给一个变量然后像调用正常函数一样调用它。
匿名函数的调用和正常的调用也没有什么分别。 就是 函数名(参数) 就可以了~~~
练一练:
请把以下函数变成匿名函数 def func(x, y): return x + y
上面是匿名函数的函数用法。除此之外,匿名函数也不是浪得虚名,它真的可以匿名。在和其他功能函数合作的时候
l=[3,2,100,999,213,1111,31121,333] print(max(l)) dic={'k1':10,'k2':100,'k3':30} print(max(dic)) print(dic[max(dic,key=lambda k:dic[k])])
res = map(lambda x:x**2,[1,5,7,4,8]) for i in res: print(i) 输出 25 16
res = filter(lambda x:x>10,[5,8,11,9,15]) for i in res: print(i) 输出 15
面试题练一练
1.现有两个元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]


#答案一 test = lambda t1,t2 :[{i:j} for i,j in zip(t1,t2)] print(test(t1,t2)) #答案二 print(list(map(lambda t:{t[0]:t[1]},zip(t1,t2)))) #还可以这样写 print([{i:j} for i,j in zip(t1,t2)]) 复制代码
1.下面程序的输出结果是: d = lambda p:p*2 t = lambda p:p*3 x = 2 x = d(x) x = t(x) x = d(x) print x 练习2
三元运算
三元运算(三目运算)在Python中也叫条件表达式。三元运算的语法非常简单,主要是基于True/False的判断。如下图:

使用它就可以用简单的一行快速判断,而不再需要使用复杂的多行if语句。 大多数时候情况下使用三元运算能够让你的代码更清晰。
三元运算配合lambda表达式和reduce,求列表里面值最大的元素:
>>> from functools import reduce >>> l = [30, 11, 77, 8, 25, 65, 4] >>> reduce(lambda x,y: x if x > y else y, l) 77
再来一个,三元运算配合lambda表达式和map的例子:
将一个列表里面的奇数加100:
>>> l = [30, 11, 77, 8, 25, 65, 4] >>> list(map(lambda x: x+100 if x%2 else x, l)) [30, 111, 177, 8, 125, 165, 4]
递归
递归是一种解决问题的思路。
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def story(): s = """ 从前有个山,山里有座庙,庙里有个老和尚在讲故事, 讲的什么呢? """ print(s) story() story()
初识递归
递归的定义—— 在一个函数里再调用这个函数本身
现在我们已经大概知道刚刚讲的story函数做了什么,就是 在一个函数里再调用这个函数本身 ,这种魔性的使用函数的方式就叫做 递归 。
刚刚我们就已经写了一个最简单的递归函数。
递归的最大深度——1000
正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去。
但是我们之前已经说过关于函数调用的问题,每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题。
Python为了杜绝此类现象,强制的将递归层数控制在了1000 (你写代码测试可能只测出997或998)。
我们可以通过下面的代码来查看此限制:
import sys print(sys.getrecursionlimit())
1000是Python为了我们程序的内存优化所设定的一个默认值,我们当然还可以通过一些手段去修改它:
import sys print(sys.setrecursionlimit(100000))
我们可以通过这种方式来修改递归的最大深度,刚刚我们将Python允许的递归深度设置为了10w,至于实际可以达到的深度就取决于计算机的性能了。
不过我们还是非常不推荐修改这个默认的递归深度,因为如果用1000层递归都没有解决的问题要么是不适合使用递归来解决要么就是你代码写的太烂了~~~
江湖上流传这这样一句话叫做:人理解循环,神理解递归。
注意Python解释器不支持尾递归优化。
再谈递归
这里我们又要举个例子来说明递归能做的事情。
首先我们需要记住构成递归需具备的条件:
1. 子问题须与原始问题为同样的事,且更为简单(问题相同,但规模在变小);
2. 不能无限制地调用本身,须有个出口,化简为非递归状况处理。
总结一下:
递归是用来解决那些问题可以简化为很多相同的规模小很多的子问题的场景。
就是把大问题分成小问题,小问题本质上合大问题是一样的问题。
比如:list1 = [1, [2, [3, [4, [5, [6, [7, [8, [9]]]]]]]]],把里面的每一个数字都打印出来。
def tell(x): for i in x: if not isinstance(i, list): print(i) else: tell(i) tell(list1)
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
再比如斐波那契数列,这种典型的可以使用递归解决的问题,都可以清晰的分为回溯和递推两个阶段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号