代码随想录 | 图论 797. 所有可能的路径(dfs) ,200. 岛屿数量 (dfs)200. 岛屿数量 (bfs) ,并查集,1971. 寻找图中是否存在路径
797. 所有可能的路径
https://leetcode.cn/problems/all-paths-from-source-to-target/description/
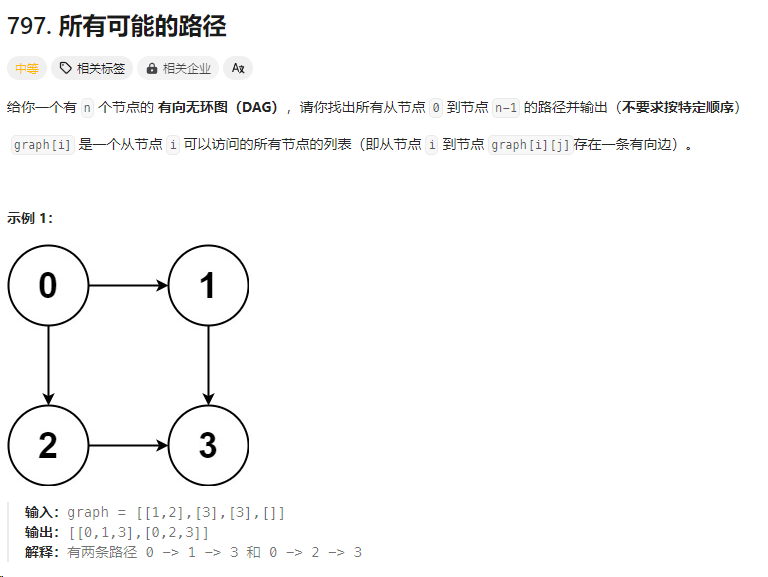
List<List<Integer>> res;
List<Integer> path;
public List<List<Integer>> allPathsSourceTarget(int[][] graph) {
res = new ArrayList<>();
path = new ArrayList<>();
path.add(0);
dfs(graph,0);
return res;
}
//x是已经选择的节点 回溯中往往是要选择的节点
public void dfs(int[][] graph,int x){
if (x == graph.length - 1){
res.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < graph[x].length; i++) {
path.add(graph[x][i]);
dfs(graph,graph[x][i]);
path.remove(path.size()-1);
}
}
总结:dfs,深度优先遍历,跟回溯类似,但是dfs是先把0节点加进去,再进入dfs函数进行递归流程,参数x代表着已经加入的节点,我们这层dfs要找的加的是x的下一个点。而递归往往是在这层backtracking中传的参数包含于这层要加入的节点(往往参数传个foe循环起始值)。
**bfs **
广度优先适合于解决两点之间最短路径问题
200. 岛屿数量 (dfs)
https://leetcode.cn/problems/number-of-islands/description/

boolean[][] visited;
int top;
int bottom;
int left;
int right;
public int numIslands(char[][] grid) {
visited = new boolean[grid.length][grid[0].length];
top = 0;
bottom = grid.length - 1;
left = 0;
right = grid[0].length - 1;
int count = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
if (visited[i][j] == false && grid[i][j] == '1'){
count++;
dfs(grid,i,j);
}
}
}
return count;
}
public void dfs(char[][] grid,int i,int j){
if (i < top || i > bottom || j < left || j > right){
return;
}
if (visited[i][j] == true || grid[i][j] == '0'){
return;
}
visited[i][j] = true;
for (int k = 0; k < 4; k++) {
switch (k){
case 0:{
dfs(grid,i-1,j);
break;
}
case 1:{
dfs(grid,i+1,j);
break;
}
case 2:{
dfs(grid,i,j-1);
break;
}
case 3:{
dfs(grid,i,j+1);
break;
}
}
}
}
总结:遍历所有点,如果是陆地而且未被遍历过,就从这个点开始走一次dfs。
**200. 岛屿数量 (bfs) **
https://leetcode.cn/problems/number-of-islands/

boolean[][] visited;
int[][] move = {{-1,0},{1,0},{0,-1},{0,1}};
int top;
int bottom;
int left;
int right;
public int numIslands(char[][] grid) {
visited = new boolean[grid.length][grid[0].length];
int count = 0;
top = 0;
bottom = grid.length - 1;
left = 0;
right = grid[0].length - 1;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
if (visited[i][j] == false && grid[i][j] == '1'){
count++;
bfs(grid,i,j);
}
}
}
return count;
}
public void bfs(char[][] grid,int x,int y){
Deque<int[]> deque = new ArrayDeque<>();
deque.offer(new int[]{x,y});
visited[x][y] = true;
while (!deque.isEmpty()){
int[] cur = deque.poll();
int curx = cur[0];
int cury = cur[1];
for (int i = 0; i < 4; i++) {
int newx = curx + move[i][0];
int newy = cury + move[i][1];
if (newx < top || newx > bottom || newy < left || newy > right)continue;
if (visited[newx][newy] == false && grid[newx][newy] == '1'){
deque.offer(new int[]{newx,newy});
visited[newx][newy] = true;
}
}
}
}
总结:bfs广度优先,广度优先不是递归了,是队列,每次进队节点就立即标记为访问过。
并查集
并查集常用来解决连通性问题。
大白话就是当我们需要判断两个元素是否在同一个集合里的时候,我们就要想到用并查集。
并查集模板
并查集模板
int[] father;
// 并查集初始化
public void init() {
for (int i = 0; i < father.length; i++) {
father[i] = i;
}
}
// 并查集里寻根的过程
public int find(int u) {
if (u == father[u]) {
return u;
} else {
father[u] = find(father[u]);
return father[u];
}
}
// 判断 u 和 v是否找到同一个根
public boolean isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 将v->u 这条边加入并查集
public void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
总结:并查集用来检查两个玩意在不在一个集合里,可能是两个点之间有没有路径。并查集要有init(),join(),find(),isSame(),这个模板是路径压缩的模板,每次join边的时候不是直接让v指向u,而是让v的根指向u的根,这样并查集就是一颗扁平的树,层数很低。
1971. 寻找图中是否存在路径
https://leetcode.cn/problems/find-if-path-exists-in-graph/description/

int[] father;
public boolean validPath(int n, int[][] edges, int source, int destination) {
father = new int[n];
init();
for (int i = 0; i < edges.length; i++) {
int u = edges[i][0];
int v = edges[i][1];
join(u,v);
}
return isSame(source,destination);
}
public void init(){
for (int i = 0; i < father.length; i++) {
father[i] = i;
}
}
public void join(int u,int v){
u = find(u);
v = find(v);
if (u == v) return;
father[v] = u;
}
public int find(int u){
if (father[u] == u) {
return u;
}else {
father[u] = find(father[u]);
return father[u];
}
}
public boolean isSame(int u,int v){
u = find(u);
v = find(v);
return u == v;
}
总结:并查集的应用罢了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号