python爬取校园集市帖子并生成词云图
注:本篇需要python基础,json基础
前言:上篇我们学习了怎么用python获取百度热搜,在这篇中,我们将进一步学习,利用python爬取校园集市帖子并生成词云图
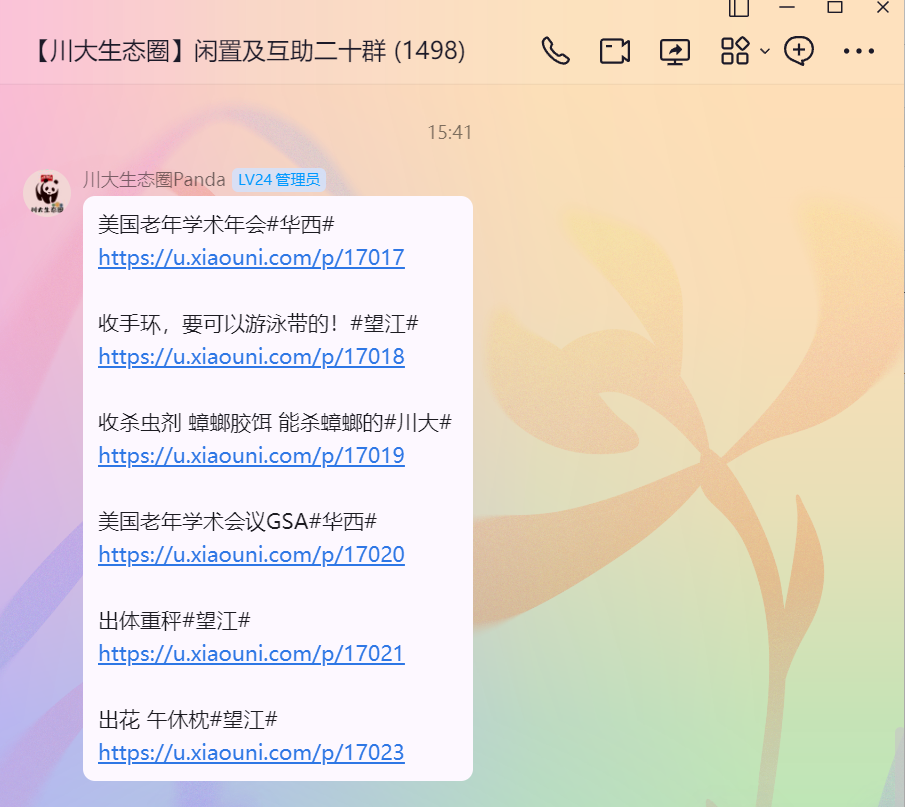
灵感背景:经常在群里看见机器人转发的校园集市帖子,于是想要爬取下来分析一下
第一步,分析请求
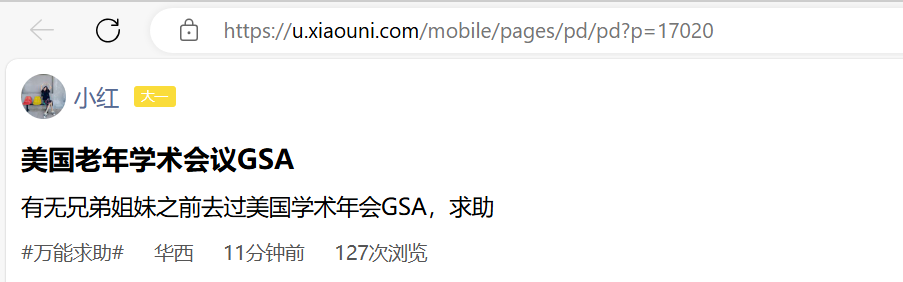
点击链接进入浏览器页面
按下F12打开浏览器开发者界面
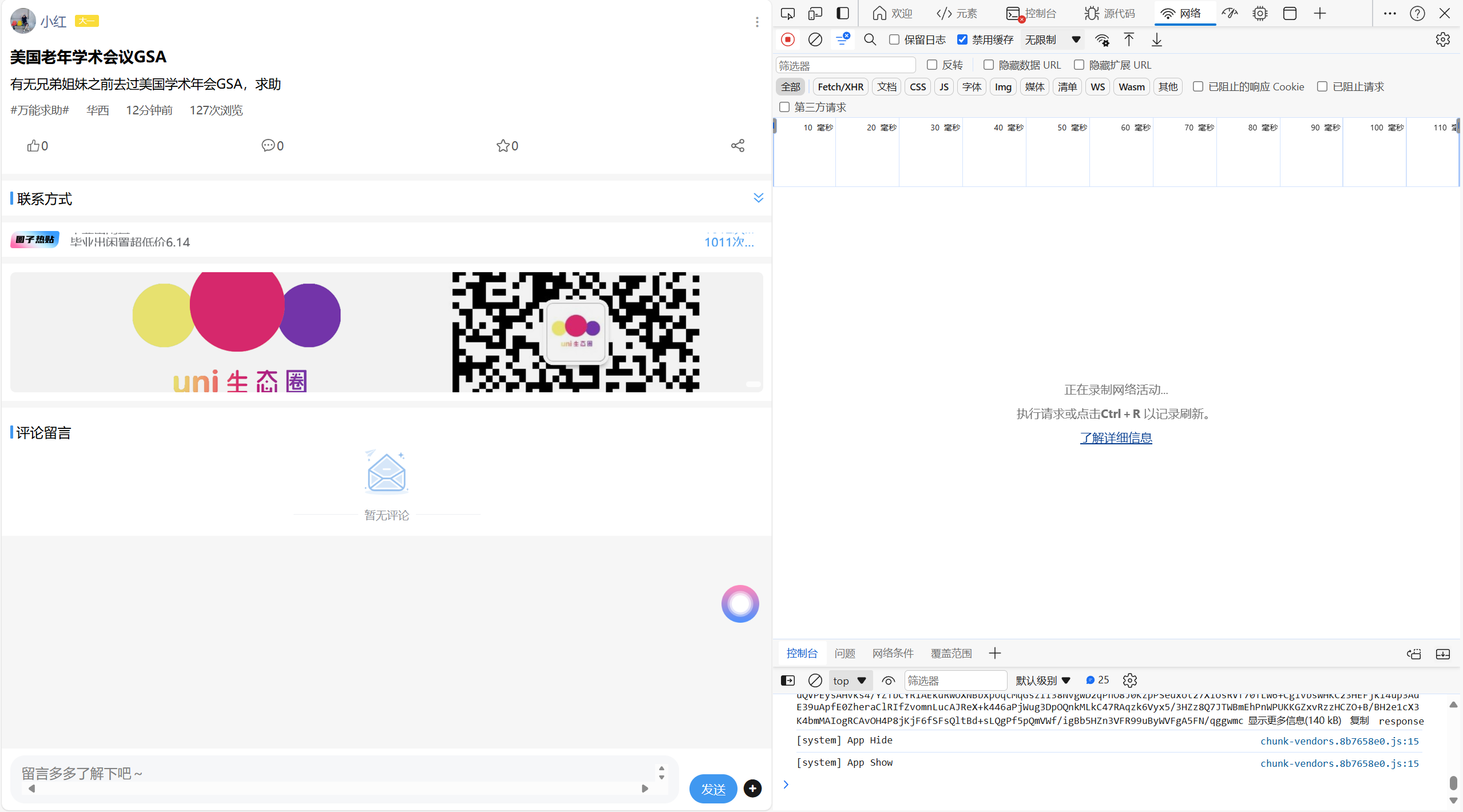
点击网络,按下F5刷新
刷新后如图所示
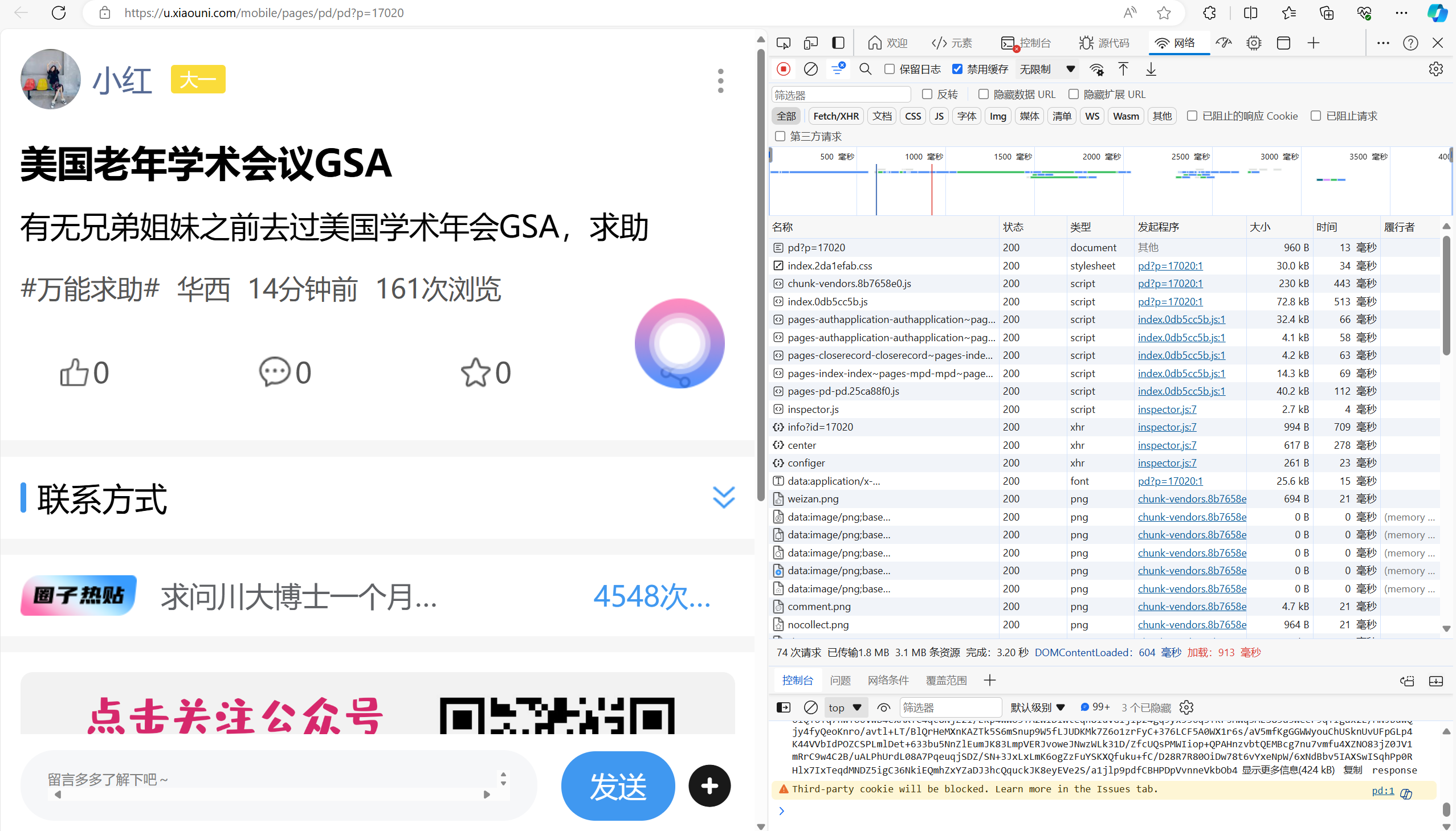
点击预览,寻找目标请求
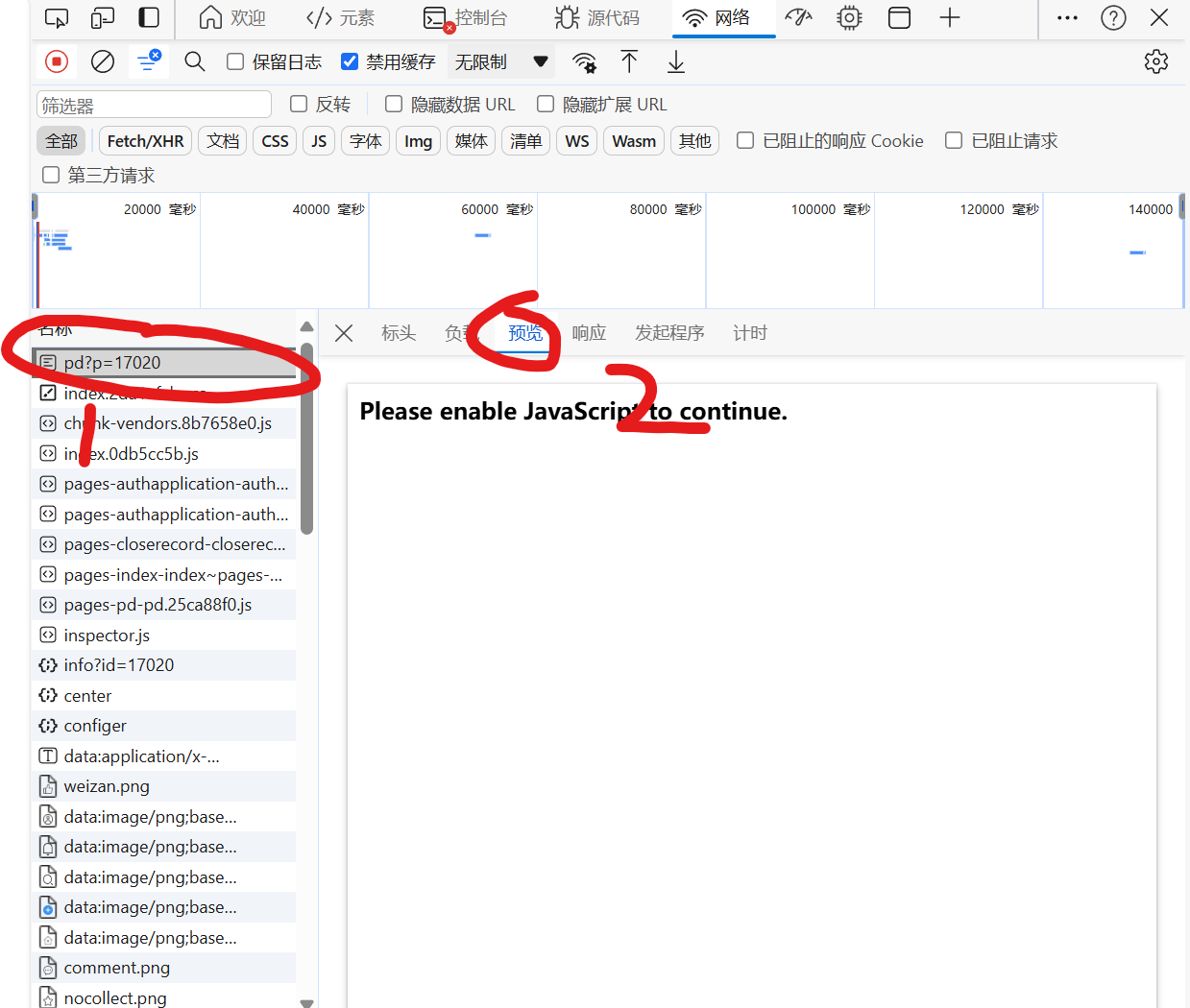
最终找到请求
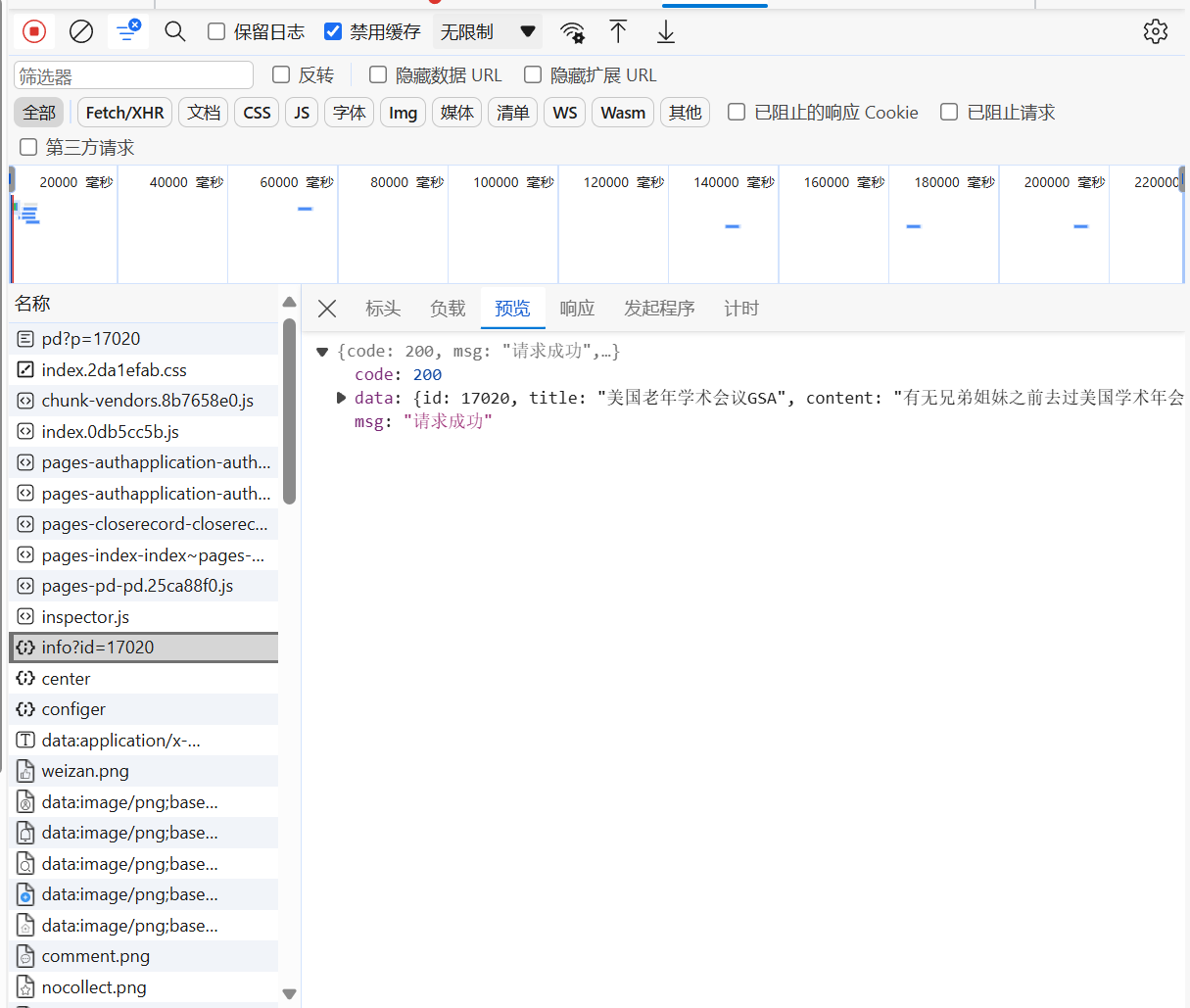
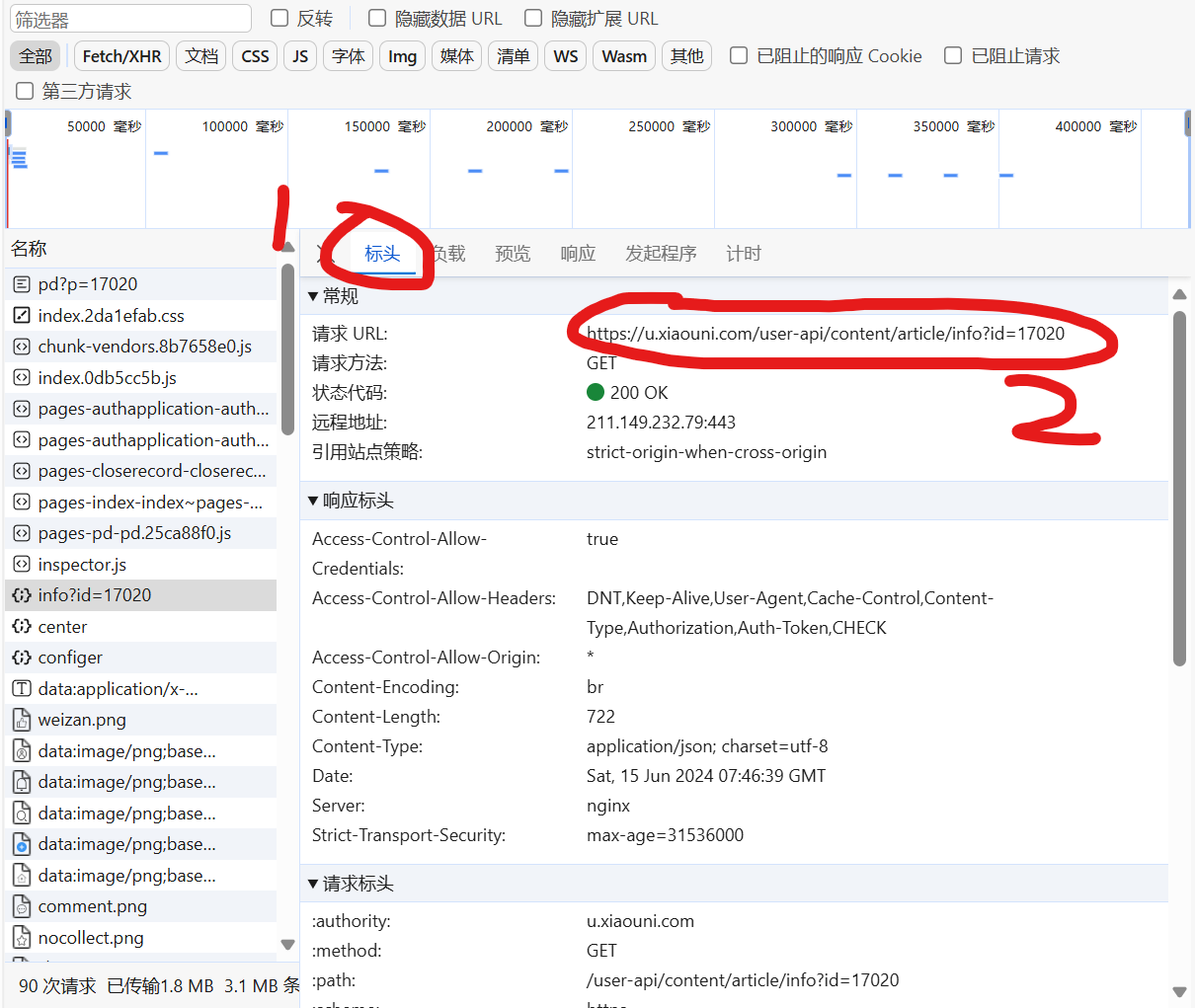
点击标头,获取url
第二步,编写代码
import requests
#发送http请求
url = 'https://u.xiaouni.com/user-api/content/article/info?id=17020'
response = requests.get(url=url)
#打印结果
print(response.text)
结果如下
{"code":200,"msg":"\u8bf7\u6c42\u6210\u529f","data":{"id":17020,"title":"\u7f8e\u56fd\u8001\u5e74\u5b66\u672f\u4f1a\u8baeGSA","content":"\u6709\u65e0\u5144\u5f1f\u59d0\u59b9\u4e4b\u524d\u53bb\u8fc7\u7f8e\u56fd\u5b66\u672f\u5e74\u4f1aGSA\uff0c\u6c42\u52a9","user_id":16872,"reading":243,"contact_id":16736,"school_id":1,"classify_id":2,"created_at":1718436786,"images":[],"art_like":0,"is_end":0,"is_top":0,"is_rec":0,"status":1,"account":"\u82f9\u679c\u53d1\u7b8d","avatar":"https:\/\/os.xiaouni.com\/uploadsimage\/2023\/09-01\/c3e65afd79583b01.jpg","zone_id":4,"is_like":0,"is_collect":0,"collect_count":0,"comment_count":0,"user":{"id":16872,"is_authority":0,"nickname":"\u5c0f\u7ea2","portrait":"https:\/\/thirdwx.qlogo.cn\/mmopen\/vi_32\/ECkvJVPXNstK1G0syFKuAvko2dF3qibGKLich2mscnYPfiaDylZrLICCG9phvUKbBaDAuk8JgbVibYyyd1AWgs9Qqg\/132","leaver_color":"#FADC3A","leaver_name":"\u5927\u4e00"},"contact":{"id":16736,"money":"0","contact_way_id":2,"contact_info":"3076689048","contact_name":"","contact_way":{"id":2,"name":"QQ"}},"school":{"id":1,"name":"\u534e\u897f"},"classify":{"id":2,"name":"\u4e07\u80fd\u6c42\u52a9","is_anonymous":0}}}
我们发现这个是json格式的内容,而且是以unicode进行编码的结果
我们进一步修改代码,获取帖子标题和内容
import json
import requests
# 发送http请求
url = 'https://u.xiaouni.com/user-api/content/article/info?id=17020'
response = requests.get(url=url)
# json格式化
json_data = json.loads(response.text)
# 获取标题和内容
title = json_data['data']['title']
content = json_data['data']['content']
# 打印标题和内容
print('title:\t'+title,'\ncontent:'+content)
结果如下
title: 美国老年学术会议GSA
content:有无兄弟姐妹之前去过美国学术年会GSA,求助
成功获取集市帖子
第三步,批量获取帖子
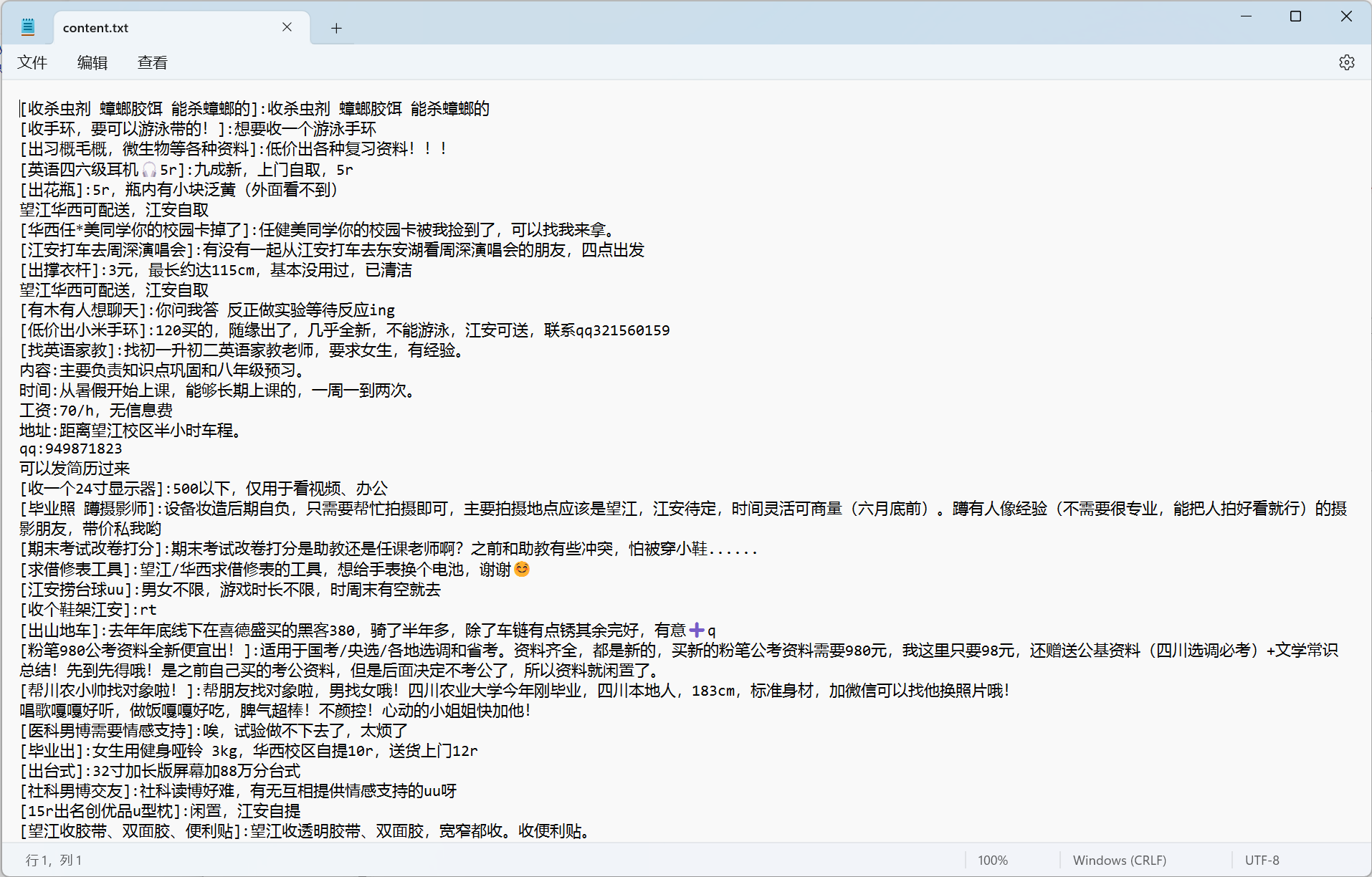
我们改进代码,获取最近的300条帖子,写到一个txt文件中方便后续使用
import json
import requests
class getContent:
def __init__(self, id: int):
self.url = 'https://u.xiaouni.com/user-api/content/article/info?id=' + str(id)
def run(self):
# 发送http请求
response = requests.get(url=self.url)
# json格式化
json_data = json.loads(response.text)
# 获取状态码,标题和内容
status_code = json_data['code']
if status_code == 200:
title = json_data['data']['title']
content = json_data['data']['content']
# 返回标题和内容
return '['+title+']:'+content+'\n'
else:
return 'none'
for i in range(1, 301):
id = 17020 - i
print(i)
text = getContent(id).run()
if text != 'none':
with open('content.txt', 'a', encoding='utf-8') as f:
f.write(text)
结果如下
第四步,绘制词云图
编写一个新的python脚本,将上面获取到的帖子内容绘制成词云图
这步需要安装jieba库(注:这里只是jieba库的简单运用,并未排除一些无意义的词,若要更加出色的表现,可进行jieba库的学习)和wordcloud库
pip install jieba
pip install wordcloud
接下来编写代码
import jieba # 用于文章分词
import wordcloud # 用于将词语生成词云图
# 读取文本
with open("content.txt", encoding="utf-8") as f:
s = f.read()
# 生成分词列表
ls = jieba.lcut(s)
# 从后向前遍历列表,删除长度小于2的元素
for i in range(len(ls) - 1, -1, -1):
if len(ls[i]) < 2:
del ls[i]
text = ' '.join(ls) # 连接成字符串
stopwords = ["可以", "一个", "有没有"] # 去掉不需要显示的词
wc = wordcloud.WordCloud(font_path="msyh.ttc", width=2560, height=1600, background_color='white', max_words=300,
stopwords=stopwords) # msyh.ttc电脑本地字体,防止中文乱码
wc.generate(text) # 生成词云图
wc.to_file("1.png") # 保存词云图片
打开1.png结果如下 (词语出现频率越高,在词云图中的字就越大)

成功实现词云图绘制
