python爬虫获取百度热搜
注:本篇学习需要python基础,html基础,xpath基础
前言:在上篇中,我们学习了怎么用python发送网页请求来获取网站的源代码,在这篇中,我们将进一步学习
本篇目标:利用python爬虫获取百度热搜
第一步,用浏览器打开百度热搜网站
百度热搜网址 https://top.baidu.com/board?tab=realtime
页面如下:

第二步,按下F12键打开浏览器开发者界面,找到热搜文本元素

第三步,右键单击文本元素复制Xpath
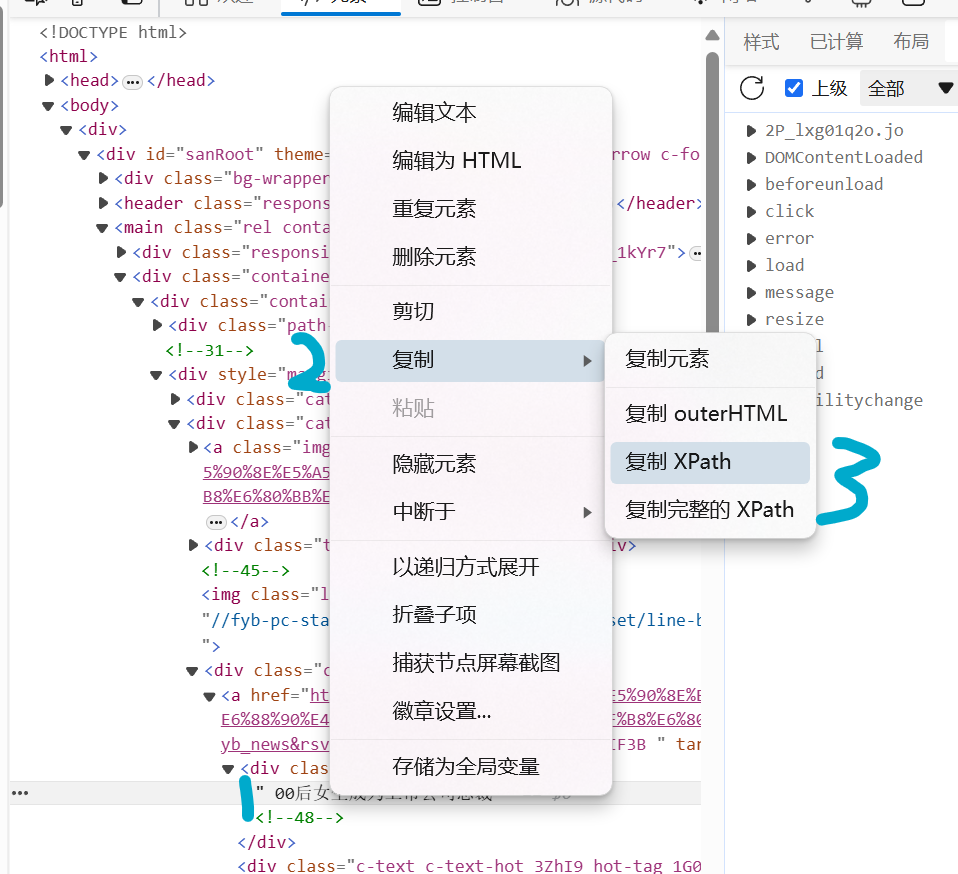
第四步,编写代码
import requests
from lxml import etree
# 发送HTTP请求获取网页内容
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
# 解析网页代码
doc = etree.HTML(response.text)
# 寻找Xpath结果
result = doc.xpath(r'//*[@id="sanRoot"]/main/div[2]/div/div[2]/div[2]/div[2]/a/div[1]/text()') #这里粘贴复制下来的xpath
# 打印结果
print(result[0])
结果如下:
00后女生成为上市公司总裁
我们成功获取到了第一个热搜,但是我们想要全部的热搜怎么办?
于是我们继续复制第二个热搜的xpath,与第一个对比
第一个 //*[@id="sanRoot"]/main/div[2]/div/div[2]/div[ 2 ]/div[2]/a/div[1]/text()
第二个 //*[@id="sanRoot"]/main/div[2]/div/div[2]/div[ 3 ]/div[2]/a/div[1]/text()
我们发现中间有一个数字不同,因此发现规律,接下来我们改进代码
import requests
from lxml import etree
# 发送HTTP请求获取网页内容
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
# 解析网页代码
doc = etree.HTML(response.text)
# 拼接xpath获取结果
for i in range(1,12):
xpath = '//*[@id="sanRoot"]/main/div[2]/div/div[2]/div['+str(i)+']/div[2]/a/div[1]/text()'
res = doc.xpath(xpath)
# 打印结果
print(str(i)+":"+res[0])
结果如下:
1: 中国为何始终属于“全球南方”
2: 00后女生成为上市公司总裁
3: 菲律宾“坐滩”军舰有多毒
4: 应对高温“渴”不容缓
5: 浙传毕业大片 这知识学了是真用
6: 大学生39天减重近20斤后“猝死”
7: 内蒙古一停工写字楼内发现遗体
8: 四级结束 已老实
9: 棚改小面积能换更大平方?谣言
10: 李开复:对中国大模型DAU很失望
11: 4名小男孩合力挪走挡路树枝
目标达成,在下一篇文章中,我们将进一步进阶学习
