HAZELCAST
1.1Hazelcast概述
Hazelcast是基于内存的数据网格开源项目,同时也是该公司的名称。Hazelcast提供弹性可扩展的分布式内存计算,Hazelcast被公认是提高应用程序性能和扩展性最好的方案。Hazelcast通过开放源码的方式提供以上服务。更重要的是,Hazelcast通过提供对开发者友好的Map、Queue、ExecutorService、Lock和JCache接口使分布式计算变得更加简单。例如,Map接口提供了内存中的键值存储,这在开发人员友好性和开发人员生产力方面提供了NoSQL的许多优点。
除了在内存中存储数据外,Hazelcast还提供了一组方便的api来访问集群中的cpu,以获得最大的处理速度。轻量化和简单易用是Hazelcast的设计目标。Hazelcast以Jar包的方式发布,因此除Java语言外Hazelcast没有任何依赖。Hazelcast可以轻松地内嵌已有的项目或应用中,并提供分布式数据结构和分布式计算工具。
Hazelcast 具有高可扩展性和高可用性(100%可用,从不失败)。分布式应用程序可以使用Hazelcast进行分布式缓存、同步、集群、处理、发布/订阅消息等。Hazelcast基于Java实现,并提供C/C++,.NET,REST,Python、Go和Node.js客户端。Hazelcast遵守内存缓存协议,可以内嵌到Hibernate框架,并且可以和任何现有的数据库系统一起使用.
如果你正在寻找基于内存的、高速的、可弹性扩展的、对开发者友好的NoSQL,Hazelcast是一个很棒的选择。
1.2 Hazelcast的特点
- 简单
Hazelcast基于Java语言编写,没有任何其他依赖。Hazelcast基于熟悉的Java util包对外暴露相同的API和接口。只要将Hazelcast的jar包添加到classpath中,便可以快速使用JVM集群,并开始构建可扩展的应用程序。 - 节点对等
和大多数NoSQL解决方案不同,Hazelcast集群中的节点是对等的,集群中没有主备角色之分,因此Hazelcast无单点故障问题。集群内所有节点存储和计算同量数据。可以把Hazelcast内嵌到已有的应用程序中或使用客户端服务器模式(应用程序作为Hazelcast集群中一个节点的客户端)。 - 可扩展
Hazelcast被设计为可以扩展到成百上千个节点,简单的增加节点,新加入的节点可以自动发现集群,集群的内存存储能力和计算能力可以维持线性增加。集群内每两个节点之间都有一条TCP连接,所有的交互都通过该TCP连接。 - 快、快、快
所有数据都存储在内存中,Hazelcast支持快速写和更新操作。
1.3 Hazelcast中的分片
Hazelcast中的分片也称为分区,Hazelcast默认271个分区。Hazlecast通常也会对分区备份,并将副本分布到集群的不同节点上,通过数据冗余提高可靠性,这种数据的存储方式和kafka、Redis Cluster类似。给定一个key,在Hazelcast集群中查找key对应数据的过程如下图所示:

1.4 Hazelcast的拓扑结构
Hazelcast集群有两种部署模式:内嵌模式,客户端/服务器模式。
-
内嵌模式
如果您有一个应用程序,其主要关注点是异步或高性能计算和执行大量任务,在这种应用场景使用内嵌部署模式比较合适,在内嵌部署模式下,Hazelcast集群中的一个节点包括:应用程序,Hazelcast分区数据,Hazelcast服务三部分。内嵌部署模式的优势是读取数据延迟低。内嵌部署模式如下图所示:
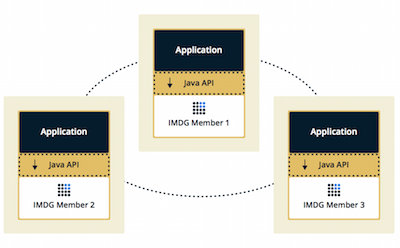
- 客户端/服务器部署模式
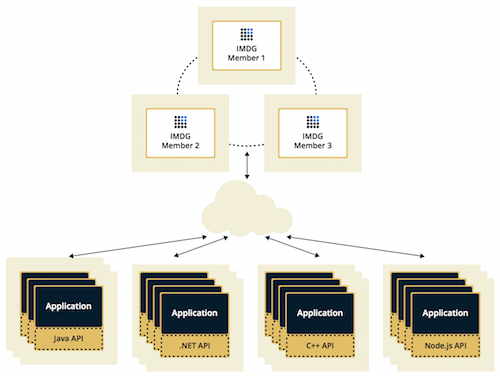
1.5 为什么选择Hazelcast
1.5.1传统的数据一致性方案
数据是软件系统的核心,在传统的架构中,通常使用关系型数据库存储并提供数据访问服务。应用程序直接和数据交互,数据库在另外的机器上通常存在一个备份。为了提高性能,需要对数据库调优或购买更高性能的服务器,这需要大量的投资和努力。
架构通常的做法是在更加靠近数据库的地方保存一份数据的备份,通常采用外部K-V存储技术或二级缓存来降低数据库访问压力。然而,当数据的性能达到极限或应用程序更多的请求是写请求时,这种方案对降低数据库的访问压力无能为力,因为不管是K-V存储还是二级多级缓存方案都只能降低数据库读压力。即便应用程序大多数是读请求,上述方案也有很多问题:当数据变化后,对缓存的影响是什么,缓存如何处理数据变化(目前公司的项目也在考虑方案解决整个问题),在这种条件下缓存存活时间(TTL)和直写缓存(Write-through )的概念诞生了。
考虑TTL的情况,如果访问的频率比TTL更低(TTL=30s,每次请求间隔35S),则每次访问的数据都不在缓存中,都需要从数据库读取数据,缓存每次都被穿透。另一方面,考虑直写缓存场景,如果集群中缓存的数据有多份,同样会面临数据一致性问题。数据一致问题可以通过节点间的互相通信解决,当一个数据不可用时,该消息可以在集群内的节点之间传播。
基于TTL和直写缓存可以设计一个理想的缓存模型,在该领域已经有缓存服务器和内存数据库等。然而,这些解决方案都是具有由其他技术提供的分布式机制的独立的单机实例(本质不是分布式集群,只是通过其他技术附加了集群特性)。回到问题的起点,如果产品是单节点,或者发行版没有提供一致性,总有一天会遇到容量问题。
1.5.2Hazelcast的一致性解决方案
围绕分布式思想设计的Hazelcast提供一种全新访问处理数据的方法。为了提高灵活性和性能,Hazelcast在集群周围共享数据。Hazelcast基于内存的数据网格为分布式数据提供集群和高可扩展性。
集群无主节点是Hazelcast的一个主要特性,从功能上来讲,集群内每个节点都被配置为对等。第一个加入集群的节点负责管理集群内其他所有节点,例如数据自动平衡、分区表更新广播。如果第一个节点下线,第二个加入集群的节点负责管理集群其他节点。第一个节点故障切换方式如下图所示:

Hazelcast是数据的另一个主要特征是完全内存中举行。这是太快了。在失败的情况下,比如一个成员崩溃,没有数据将丢失自Hazelcast分发拷贝的数据在所有集群成员。
所示的特性列表分布式数据结构一章Hazelcast支持许多分布式数据结构和分布式计算工具。这些提供强大的方式访问分布式集群内存和cpu访问真正的分布式计算。
1.5.3 Hazelcast独特的优势
-
Hazelcast是开源的。
-
Hazelcast只是一个JAR文件。你不需要安装软件。
-
Hazelcast是一个库,它并不对Hazelcast用户架构。
-
Hazelcast提供开箱即用的分布式数据结构,比如地图,队列,多重映射,话题,锁定和执行者。
-
没有“大师”,意思是没有单点故障在Hazelcast集群;集群中的每个成员配置为功能是一样的。
-
当内存的大小和计算需求的增加,新成员可以动态地加入到Hazelcast集群规模弹性。
-
数据成员失败的弹性。数据备份是分布在集群。这是一个很大的好处,当集群中的一员崩溃,数据不会丢失。
-
成员都意识到彼此不像在传统的键值缓存解决方案。
-
你也可以建立自己的custom-distributed数据结构使用服务编程接口(SPI)如果你不满意所提供的数据结构。
最后,Hazelcast具有一个富有活力的开源社区,使其不断发展。
Hazelcast适合当你需要:
-
分析应用程序需要大数据处理数据分区。
-
网格中的保留经常被访问的数据。
-
缓存,尤其是一个开源JCache提供者与弹性分布式可伸缩性。
-
主数据存储的应用程序最大的性能、可伸缩性和低延迟的要求。
-
一个内存中的NoSQL键值存储。
-
发布/订阅应用程序之间的通信以最高速度和可伸缩性。
-
应用程序需要在分布式和规模弹性云环境。
-
高可用性的分布式缓存的应用程序。
-
连贯性和Terracotta的替代品。
1.6 数据分区
Hazelcast中的分片也叫做分区,分区是一个内存段,分区中存储数百或数千数据实体,分区的存储容量取决于节点自身的存储能力。
Hazelcast默认提供271个分区,类似Redis拥有16384个槽位。当启动只有一个节点的Hazelcast集群时,节点拥有全部271个分区。Hazelcast集群只有一个节点的条件下的分区分布如下图所示:

Hazelcast集群新增加一个节点,或启动一个包含两个节点的Hazelcast集群,分区的分布情况如下图所示:

黑色字体表示的分区为主分区,蓝色字体表示主分区的副本。
不断加入新的节点,Hazelcast会一个一个的把主分区和主分区副本迁移到新加入的节点上,保证主备分区的一致性和冗余性。当集群有四个节点时, 集群分区的一种可能方案如下:

Hazelcast将分区均匀的分布到集群的各个节点,Hazelcast自动创建分区的副本,并将副本分布到各个节点来提供可靠性。以上图片展示的Hazelcast分区仅仅是为了方便和清晰的描述Hazelcast分区机制。通常来说分区的分布不是有序的,Hazelcast使用一种随机的方式分布各个分区。这里重点说明Hazelcast均匀的分布分区和分区副本。Hazelcast 3.6版本引入轻量化节点(存储轻量化节点),轻量化节点是一种新的节点类型,轻量化节点不持有任何分区数据。轻量化节点主要用于计算型任务和监听器注册,尽管轻量化节点不保存分区数据,但是轻量化节点可以访问集群中其他节点所持有的分区数据。
1.6.1 数据如何被分区
Hazelcast使用一种哈希算法将数据分布到特定分区。给定一个key,分区计算过程如下:
- 将key序列化为byte数组。
- 计算byte数组的哈希值。
- 哈希值与分区数求余,得到分区ID(注意不是节点数)。
同一个key的分区ID必须保持一致。
1.6.2 分区表
启动集群内的一个节点时,该节点会自动创建一个分区表。分区表存储分区ID和集群内其他的节点信息。分区表的主要目的是让集群内的所有节点(包括轻量节点)了解分区信息,确保每个节点都知道数据存储在哪个分区,哪个节点上。最早加入集群的节点周期性的向集群内其他节点发送分区表。通过这种方式,当分区关系发生变化时,集群内的所有节点都可以感知该变化。当一个节点加入或离开集群时,分区关系就会发生变化。
当集群内最早加入的节点故障时,剩余节点中最早加入集群的节点负责周期性的向其他节点发送分区表
发送分区表的周期默认是15S,如果想修改周期,可以通过设置环境变量hazelcast.partition.table.send.interval来进行修改。
1.6.3 重分区
重分区是Hazelcast重新分配分区关系的过程,以下两种情况会触发Hazelcast执行重分区动作。
- 一个节点加入集群.
- 一个节点离开集群.
在这种情况下,最早加入集群的节点会更新分区关系表,并将更新后的分区表发送给集群内其他节点。轻量节点加入集群不会触发重分区动作,因为轻量节点主要执行计算任务,本身不保存任何分区数据。
1.7 使用场景
- 共享服务器配置和服务器信息,
- 集群数据变更通知,
- 作为简单的内存缓存,
- 作为一个在特定节点执行特定任务的调度器,
- OSGI框架下不同节点共享信息.
- 集群内共享数千个key,
- 作为Cassadra的前端.
- 集群内分发用户状态,不同对象间传递信息,共享系统数据结构,
- 多租户缓存,每个租户都有自己独立的缓存,
- 共享数据集合,
- 从亚马逊EC2分发和收集服务负载信息,
- 作为性能检测的实时流,
- Session存储器


 浙公网安备 33010602011771号
浙公网安备 33010602011771号