比MySQL快839倍!揭开分析型数据库JCHDB的神秘面纱

前不久,京东智联云云产品研发部架构师王向飞老师在线上公开课《Clickhouse在京东智联云的大规模应用和架构改良》中,介绍了Clickhouse 数据库在京东智联云的落地应用与优化改进经历,为想要深入了解Clickhouse的小伙伴们送上了一堂干货满满的技术分享课程。
精彩分享回顾:《亿级数据库毫秒级查询?看完这一篇,海量数据赋能你也行》
现在,这个基于Clickhouse的分析型云数据库JCHDB已正式上线,大家可以前往京东智联云控制台开通试用。
JCHDB是京东智联云基于ClickHouse打造的联机分析(OLAP)服务,采用分布式架构,可实现多核、多节点的并行化大型查询,其查询性能比传统开源数据库快1~2个数量级,可充分满足大型业务系统数据分析的需求。

ClickHouse是Yandex公司开源的一款分析型数据库。Yandex是俄罗斯最大的提供搜索服务的公司,包含各类在线流量分析服务。ClickHouse就是在这样的背景下出现的。下面有一组数据,可以先来让你感受一下ClickHouse的强悍性能:
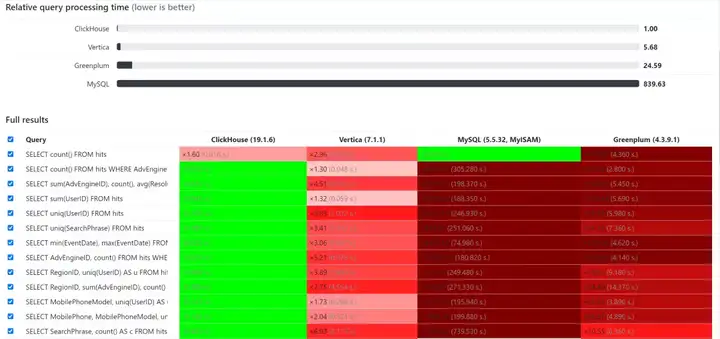
▲各种类型数据库在1亿数据量下的查询性能▲
上图列举了包含count、sum、group by、order by等情况的查询对比,同等条件下,ClickHouse的查询性能异常强悍:
- 是MySQL的839倍
- 是Greenplum的24倍
- 是Vertica的5倍
那么,ClickHouse 为什么能这么快呢?下面我就带大家来一起揭开它的神秘面纱:
1列式存储与高效的数据压缩
ClickHouse为了处理大数据量,同样选择了列式存储,这种方式不但可以节省数据查询时的IO,更有利于数据压缩。ClickHouse在数据压缩上默认使用LZ4算法,总体压缩比可达8:1。高压缩比减小了数据体量,进而会提高磁盘IO及网络IO的效率,但压缩和解压还是会消耗CPU资源,所以ClickHouse对数据块的大小做了优化控制来达到最佳效果。
2分布式多主架构提高并发性能
ClickHouse使读请求可以随机打到任意节点,均衡读压力,写请求也无需转发到master节点,不会产生单点压力。并且使用分片(shard)分区(partition)的概念,使数据可以通过随机或是hash的方式准均分地落在所有分片上,即数据的水平拆分,加速数据查询时的并行能力。在节点内部使用分区分割表数据,在进一步提升并行处理能力的同时,更能加快数据块的快速定位。
3向量引擎利用SIMD指令实现并行计算
向量引擎是ClickHouse很重要的一个特点,向量计算就是ClickHouse自底向上极尽优化设计思路的重要体现。向量引擎借助CPU的SIMD实现,对多个数据块来说,一次SIMD指令会同时操作多个块,大大减少了命令执行次数,缩短了计算时间。向量引擎在结合多核后会将ClickHouse的性能淋漓尽致的发挥出来。
4稀疏索引及跳数索引
ClickHouse使用稀疏索引大大提高了搜索性能。ClickHouse的索引是固定间隔(默认8192)抽样形成的,而不是一一对应的索引,这样就在大数据量情况下,大大缩减了索引大小,进而可以将索引加载到内存中,加快索引速度。如果不够快,ClickHouse还提供了二级索引(跳数索引),这类索引是建立在主键索引(稀疏索引)之上的,以跳表的原理为实现,加快主键索引的定位速度。当然这种设计对于单条数据的查询来讲并不适合,这也是ClickHouse作为OLAP行数据库对OLTP类部分功能舍弃,也证明了ClickHouse对于OLAP领域的特有针对性。
5提供丰富的表引擎匹配各类分析场景
ClickHouse针对特殊业务需求做许多业务抽象,如:
- ReplacingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- SummingMergeTree
- AggregatingMergeTree
如果数据有去重场景可以使用前三种,如果数据有简单字段预聚合操作可以使用SummingMergeTree,如果有自定义复杂预聚合操作可以使用AggregatingMergeTree。总之,ClickHouse通过各类表引擎,省去了对数据预处理的环节,加快了数据处理速度。
6支持数据采样统计
这是ClickHouse比较特别的一个设计,支持百分比数据采样,并进行统计分析,有很多场景是不需要取到所有完整数据的,或者在大数据量条件下只需获取大体趋势,这类场景不需要业务端做额外工作,使用ClickHouse就可以了。
其实ClickHouse并不是在某个方面用了特别的技术,而是在所有可以优化的方面都极尽优化,所以跬步千里。

ClickHouse是针对OLAP场景而设计研发的,所以在OLTP场景还是会有些水土不服,所以结合以上特点,推荐ClickHouse在如下场景中使用:
- 海量数据的存储和查询统计
- 用户行为分析
- 实时报表
- 商业智能
- 其他实时分析的业务或场景

结合种种优势及京东集团内部多年的使用经验,京东智联云基于开源ClickHouse研发了分析型数据库JCHDB服务,并将其对外赋能。京东智联云JCHDB主要是依赖开源ClickHouse,并基于云K8s平台构建的分新型数据库服务,可以为用户提供快速创建、自定义规格、规格变配等服务的同时,可以让用户使用ClickHouse各种丰富的功能。
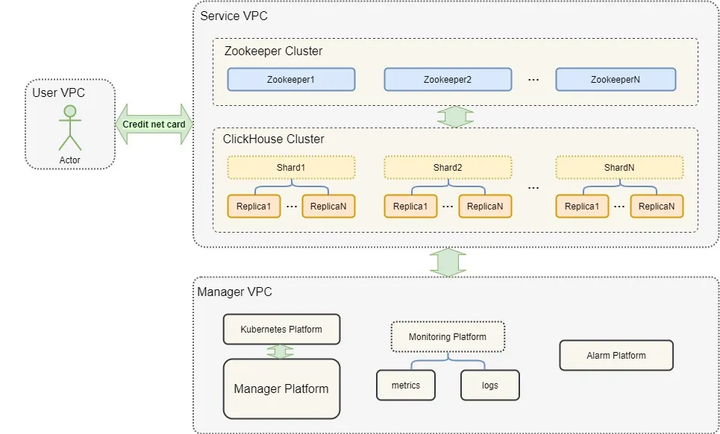
▲JCHDB架构图▲
JCHDB采用Zookeeper集群和ClickHouse集群的组合方式结合ReplicatedMergeTree表引擎来提供多副本机制,使多副本实现单写,并且多节点异步同步数据。这样可确保数据的冗余存储,保证数据的高可用性。JCHDB通过用户VPC、服务VPC和管理VPC互相隔离的方式保证ClickHouse节点的数据安全性。同时,JCHDB通过将丰富的指标及日志数据对接到统一监控平台,实现了数据库节点对用户的可观测性,可使用户更加透明安心地使用JCHDB。

ClickHouse的集群架构天然就适合跑在K8s上,外加K8s已经成熟的StatefulSet,更加适合使用K8s进行调度,并且基于K8s进行架构部署也会更好地顺应多云思想。
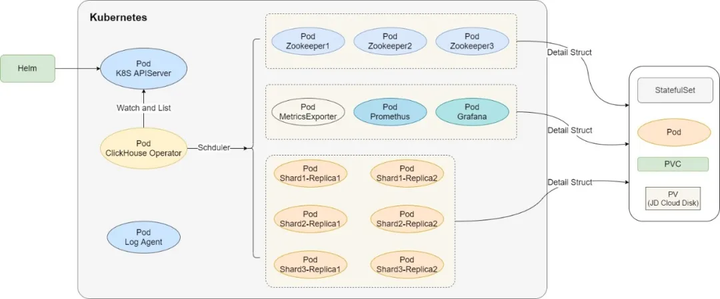
▲JCHDB K8s架构图▲
针对ClickHouse集群的复杂度,使用Operator自定义CRD进行监听和调度。以Helm的方式进行chart包管理,通过values.yaml进行渲染,可灵活对集群进行复杂多样的属性配置。利用StatefulSet并挂载云盘,使存储和计算分离,同时也可以使pod故障实现秒级恢复。JCHDB不但使用多副本保证计算节点的高可用,还使用云盘三备份方式保证数据的高可用。

JCHDB支持多可用区部署。虽然上面提到了很多可以保证高可用的机制和措施,但如果大部分数据库实例都被调度到了同一台物理机,在这台物理机突发故障的时候也是不可想象的。
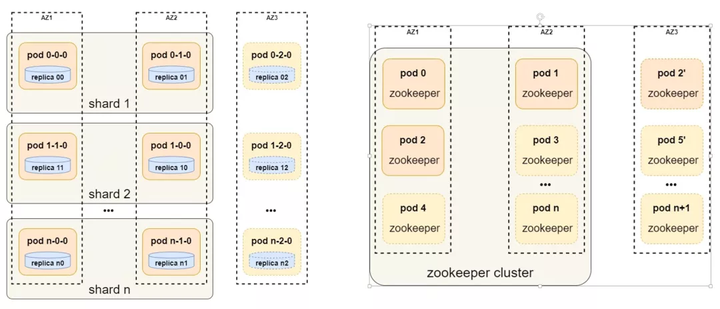
▲JCHDB多可用区架构图▲
JCHDB会根据用户对可用区的选择实现不同的调度方式,如果用户选择3副本3可用区,则会将3个副本节点调度到3个可用区,如果多余3个节点,会在此基础上再近似均分的方式进行调度。ClickHouse和Zookeeper节点都是类似的调度方式。如果用户选择了单可用区,也会保证同分片的不同副本节点不会被调度到同一台物理机。用户可以根据自己的需求自行选择可用区配置。

JCHDB不但提供了许多实例级的基础指标(如CPU使用率、内存使用率、磁盘使用及IO指标等),还提供了针对ClickHouse的许多相关指标(QPS、每秒插入记录数、积压job数、当前活跃连接数等)。
▲JCHDB部分指标数据监控图▲

当然,以上所述只是JCHDB的冰山一角,本篇文章先让大家对JCHDB有个初步了解,欢迎有兴趣的或有需求的同学们来试用。点击 【阅读】 即可详细了解 京东智联云JCHDB。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号