NLP带来的“科幻感”超乎你的想象 - ACL2020论文解读(一)
作者:京东AI研究院

近些年,人工智能无疑是信息技术领域最热门的技术之一。人工智能战胜世界围棋冠军、人工智能战胜游戏高手、人工智能医生看病会诊……不断进步的科技正推动着人工智能从一个无法实现的幻想,不断突破人类的想象,完成一个又一个挑战。
AI写科幻剧本?科幻小说都不敢写
2018年,在全球科幻电影节( Sci-Fi London Film Festival)上的一项名为“48小时内电影创作挑战”(SFL 48 Hour Film Challenge)的活动中,来自纽约的导演Oscar Sharp和他在纽约大学AI研究院的同事Ross Goodwin利用人工智能(这套人工智能称自己为Benjamin)创作出了一个剧本,并在48小时内将这个剧本拍摄出来了。虽然电影只有短短 9 分钟,但这也是世界上第一部由AI创作并拍摄出来的电影,这在以前是科幻小说都不敢写的故事。

在此之后,人工智能在电影业中不断得到更多落地应用。2019年,迪士尼研究所和罗格斯大学的科学家共同发表了关于AI文本生成动画模型的论文。研究人员表示,这种算法只要在输入的文本中描述某些活动即可,不需要注释数据和进行大量训练就能产生动画。
现在,使用机器编写剧本的想法正在受到如Netflix、Hulu、好莱坞等世界级影视科技公司的青睐。机器学习——使用算法分析大量数据以给出决策建议——正在渗透到电影业的各个角落。
人工智能剧本创作的关键技术——自然语言生成
而在使用人工智能进行影视剧本创作中,NLP 领域的自然语言生成技术是其中的关键技术之一。
但自然语言生成技术的应用场景和研究意义远不止于影视剧本创作。在电商场景下,可用于营销内容生成以及面向复杂问题回答与人机交互的自动文本生成;融媒体场景下,结合文本与语音合成技术可应用于新闻自动播报、直播文字、多语言/跨语言自动文摘;学术研究场景中,学术文献、综述生成、内容反馈、自动作文等都是自动文摘的落地应用场景。
详情可点击查看:
➡️ 京东商城背后AI技术揭秘(一)——基于关键词自动生成摘要
➡️ 京东商城背后AI技术揭秘(二)——基于商品要素的多模态商品摘要
NLP 最高级别学术认可——ACL 论文收录
NLP(Natural Language Processing)领域中有一个全球最高级别的学术会议——ACL 会议(Annual Meeting of the Association for Computational Linguistics),它由计算语言协会在 1962 年举办第一届,其后每年一届,致力于推动自然语言处理相关研究的发展和国际学术交流。
ACL 议题涉及对话(Dialogue)、篇章(Discourse)、评测( Eval)、信息抽取(IE)、信息检索(IR)、语言生成(Language Generation)、语言资源(Language Resource)、机器翻译(Machine Translation)、多模态(Multimodal)、音韵学/ 形态学( Phonology / Morphology)、自动问答(Queston Answering)、语义(Semantics)、情感(Sentiment)、语音(Speech)、、文摘(Summarisation)、句法(Syntax)等多个方面。
近日,ACL 2020 公布了今年大会的论文录用结果。根据官方公布的数据,本届大会共收到 3429 篇投稿论文,投稿数量创下了所有 ACL 旗下会议新高。ACL 除了在国际 AI 学界具有顶级影响力外,其审稿规范和审稿质量,也是当今 AI 领域国际顶级会议中公认的翘楚,论文被录取的难度十分高。以 2019 ACL 为例,论文录取率仅为 22.7% 。因此,研究论文能够被 ACL 录用,不仅意味着研究成果得到了国际学术界的认可,也证明了研究本身在实验严谨性、思路创新性等方面的实力。
京东 AI 研究院专注于持续性的算法创新,80% 的研究都由京东实际的业务场景需求为驱动,聚焦 NLP语音、计算机视觉、机器学习(包括深度学习和强化学习)等领域。在ACL 2020 中,京东 AI 研究院提交论文经过重重审核,最终被大会收录。
今天,我们就将为大家解读其中的一篇_:Self-Attention Guided Copy Mechanism for Abstractive Summarization_
论文对现有自动文摘的研究方法进行了优化,使通过该新模型生成的摘要内容更加精确。
论文解读

1 摘要
自动文本摘要(简称“自动文摘”)是自然语言处理领域中的一个传统任务,其目的是为输入文本生成一段简化文本。常用的自动文摘方法包括抽取式自动文摘(Extractive Summarization)和生成式自动文摘(Abstractive Summarization)。抽取式自动文摘方法抽取输入文本中的原始句子组成摘要;生成式自动文摘方法利用自然语言生成技术生成摘要。
自动文摘模型的关键是准确识别出输入文本中的重要信息,并输出涵盖这些信息的流畅文本。抽取式自动文摘方法可以显式的对输入文本的每个句子的重要性进行建模,但是输出的摘要是通过拼接句子构成的,句间的流畅性无法得到保证。生成式自动文摘方法通常可以输出较为流畅的摘要,但是有时无法完全准确捕捉到输入文本中的重要的信息。
本文所介绍的是自动文摘模型提出了一种自注意力(Self-Attention)指导的复制机制,该方法融合了抽取式自动文摘方法和生成式自动文摘方法,在多个文本摘要数据集上取得了比对比模型更好的性能。
我们首先介绍一下一些相关背景知识,包括自注意力机制,复制机制和抽取式自动文摘方法TextRank算法。
2算法及模型
《Attention is all you need》提出了基于自注意力机制的Transformer框架,在机器翻译任务上超过了当时其他的模型。简单来说,自注意力机制将文本中的词两两计算相似度,然后对这些相似度进行归一化得到权重矩阵,最后将这些权重和相应的词进行加权求和得到下层的隐层表达。
复制机制是自动文摘模型中的一个常用机制。传统的文本生成在计算生成每个词的概率时,所有的词被限制在一个固定大小的词表中,即生成的词必须来自于这个固定大小的词表。复制机制除了会在这个固定大小的词表中生成某个词,还会选择性的在输入文本中选择一个词,这个词不受词表限制。复制机制实际上和人类在做摘要时的逻辑相吻合,即输入文本中的某些词,尤其是那些关键词,组成了这个文本的主干。我们只需要将这些关键词从输入中“复制”到输出中,然后再做一个适当的加工,使输出的摘要更加自然。复制机制的动机就是自动识别出这些关键词,然后将其“复制”到输出摘要中。TextRank算法一种基于图模型的经典抽取式自动文摘方法,其基本思想来源于谷歌的 PageRank算法。TextRank算法通常会把输入文本分割成若干基本单元并建立图模型, 利用基本单元间关系组成的邻接矩阵进行随机游走,对文本基本单元进行排序。

上文提到,自动文摘模型希望通过复制机制将输入文本中的重要词复制到输出中,但由于使用注意力权重作为复制概率,并不能显式地识别出哪些词是重要的词。我们需要找到一个合适的方式显式地为输入文本中的词的重要性进行打分,进而指导模型的复制机制,改善复制的效果。TextRank算法利用邻接矩阵计算输入文本中每个词的重要性得分。
我们注意到,Transformer模型的自注意力机制提供了输入文本中的词两两之间的权重,该权重矩阵可以作为TextRank算法的邻接矩阵。基于这个邻接矩阵,通过随机游走,我们可以得到输入文本中的词的重要性得分 ,进而指导复制概率,公式如下:

3 实验结果
我们提出的模型在文本摘要数据集CNN/DailyMail和Gigaword上取得了比对比模型更好的性能。
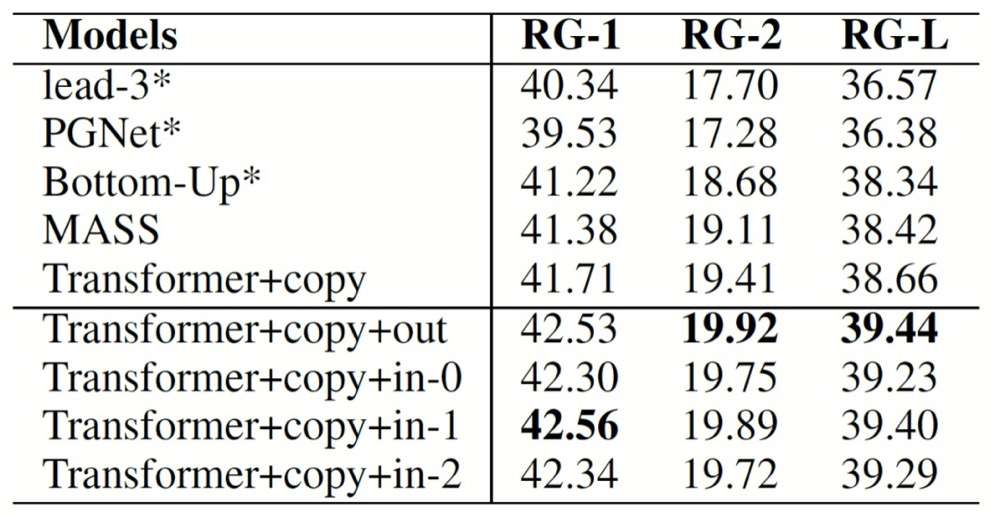
CNN/DailyMail数据集实验结果对比

Gigaword数据集实验结果对比
在之前的论文解读专栏文章中,我们为大家详细介绍了京东商城是如何在现有基础上进行更进一步的技术探究与创新,从而有效提升电商的营销转化率的。
详情可点击【阅读】查看更多相关内容
京 东 AI 研 究 院
京东AI研究院专注于持续性的算法创新,多数研究将由京东实际的业务场景需求为驱动。
研究院的聚焦领域为:计算机视觉、自然语言理解、对话、语音、语义、机器学习等实验室,已逐步在北京、南京、成都、硅谷等全球各地设立职场。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号