如何将Grafana的数据集合到自己前端项目的数据驾驶舱中
Grafana是可以提供API Keys给你可以让你直接使用从Grafana获取来的数据来搭配其他图形工具来实现数据监控图的。虽然它本身也可以显示数据,但是有时候数据很全面且分散在不同页面,而有些运维同学只需要某些重要的数据,不能一下子直观看清,所以某些重要常用的数据可以单独摘选出来,不常用的可以在打Grafana查看。
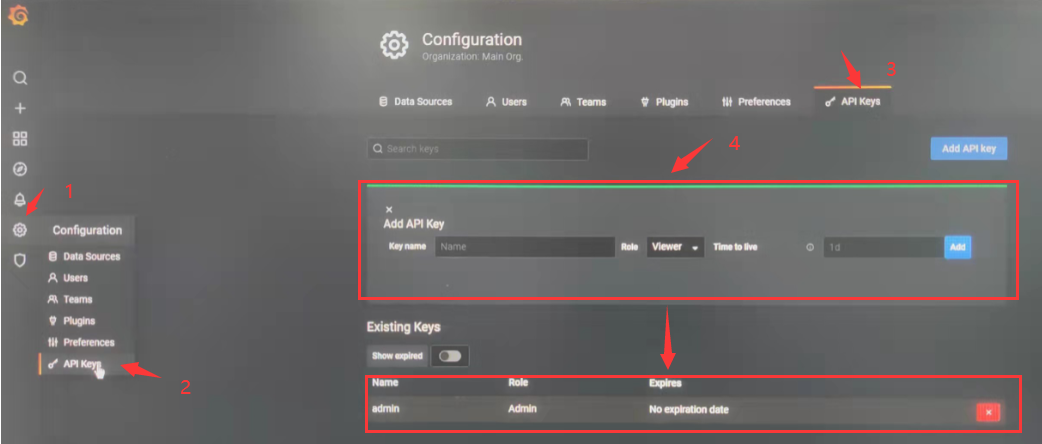
先在Grafana中打开设置->API Keys->填写Key name,角色权限根据需求,图中设置为admin,过期时间根据需求,图中设置不填默认无过期时间,然后就会弹出一个弹窗,先别急着关掉!!!
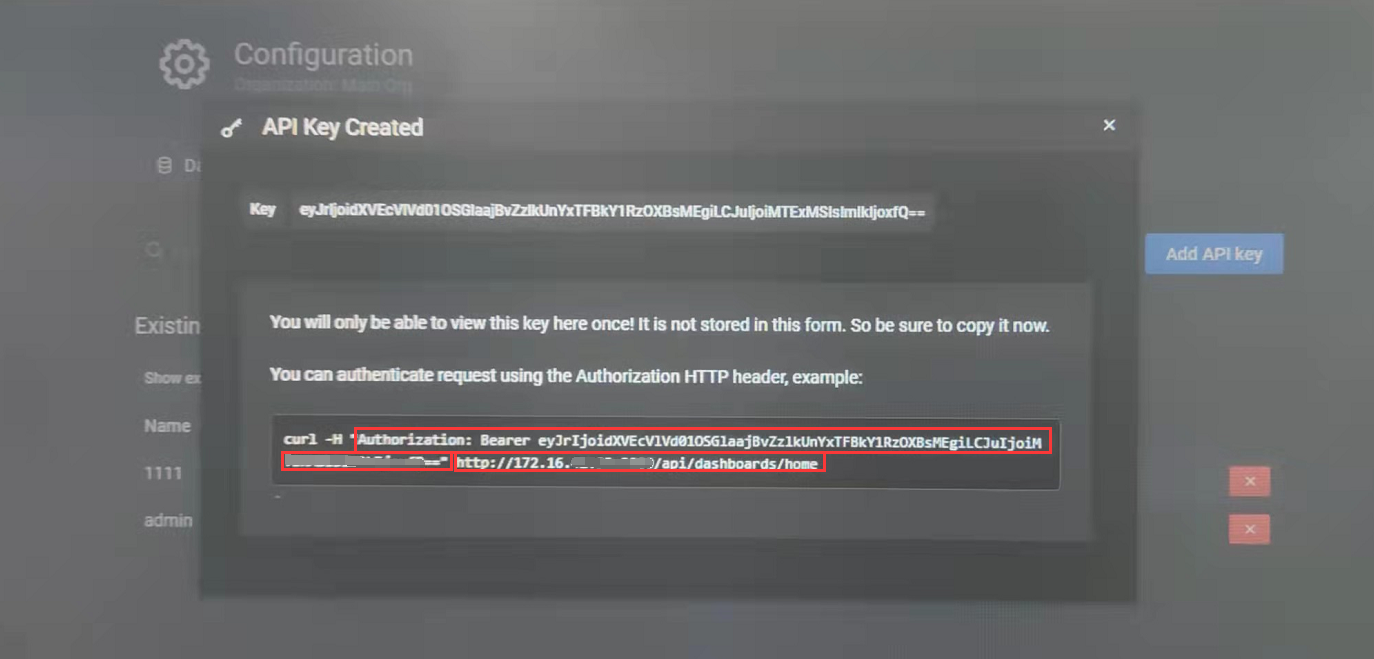
弹窗里会给你一段curl,这段话的意思就是向http地址发了一个头部带有Authorization(token)的请求。先把这段话保存下来,关闭弹窗之后没地方查看。这里面有两个有用的信息,一是http地址,二是token。http地址你可以设置为前端代理转发的后端地址,而token是你发起向Grafana后端发起请求的时候所需要的头部凭证,否则会授权失败,获取不到数据。
之后你就可以模拟Grafana前端的查询数据,向Grafana后端发起请求。需要注意的是Grafana基本搭配的是Elasticsearch数据源,请求体中携带的语句是查询语句,对Elasticsearch语句有点了解是最好的,不清楚也可以f12打开控制台network,然后点一个数据发请求看它原本的请求体里的Elasticsearch语句是怎么写的。这里还需要注意以下几点:
1.查询语句中有包含“\”等符号需要考虑是否能够会被转义的问题,因为字符串中的“\”本身就代表转义,对于有意义的“\n”会解释为换行符,对于“\uXXXX”会解释为Unicode对应的字符,对于没有意义的“\0101”则会省略“\”解释为0101。所以为了解决这个问题,得用“\\”来替代“\”,这样原本字符串就会消耗掉一层“\”,变成正常的查询语句。
2.批量请求查询语句如果非常长,建议先用一个数组分段保存起来,然后用换行符(\n)拼接起来,否则一长串直接敲击回车键换行vscode会报错。
let bulkRequestBodyArray=[ "语句1", "语句2", "语句3", "语句4", ]; let params=bulkRequestBodyArray.join("\n"); params=params+'\n'; // 批量请求查询语句必须以“\n”终止 //下面这种方法也行 let bulkRequestBodyArray=[ "语句1\n", "语句2\n", "语句3\n", "语句4\n", ]; let params=bulkRequestBodyArray.join("");
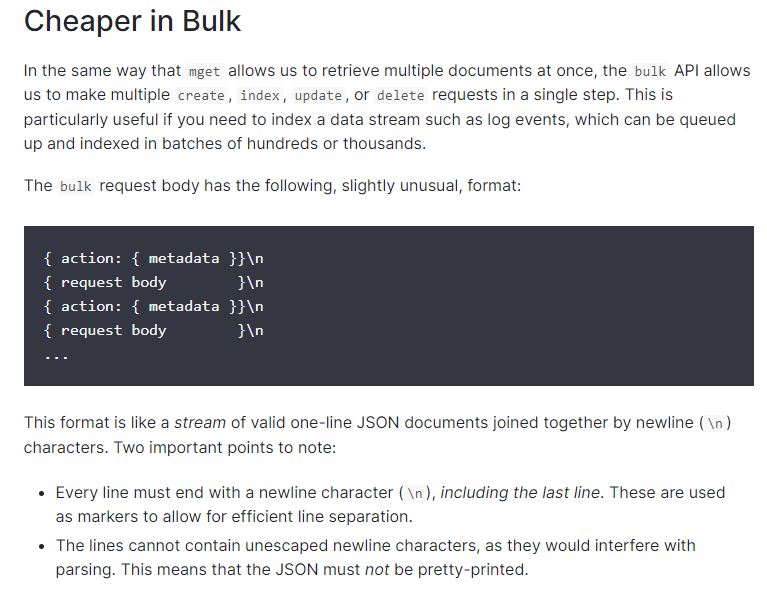
Elasticsearch官网对批量请求语句写法的要求
3.查询语句中有携带grafana的时间戳的,可以拼接自己所需要的时间。
4.每个请求都需要携带token请求头,建议将之前获取的token配置为默认的请求头参数,此处以axios为例:axios.defaults.headers.common['Authorization'] ='Bearer XXXXXXXXXXXXX';
获取到数据,就可以搭配vcharts或Echarts来构建自己需要的监控图了。
__EOF__
