
洛谷题单指南-字符串-P3375 【模板】KMP
原题链接:https://www.luogu.com.cn/problem/P3375
题意解读:给定两个字符串:原串s,模式串p,求p在s中出现的所有位置,并输出p的长度为1~p.size()的子串的最长相同真前、后缀的长度。
解题思路:
KMP模版题,分两问,第一问通过KMP核心算法实现,第二问输出模式串的Next数组内容,接下来一一解读。
1、字符串相关概念
子串:字符串中挑选一段连续的字符形成的字符串,挑选的字符连续。
子序列:字符串中从前到后挑选若干字符形成的字符串,挑选的字符不一定连续。
前缀/真前缀:字符串中从开头挑选一段子串,称为前缀,如果前缀不等同于原来的字符串,称为真前缀。
后缀/真后缀:字符串中选一段包括结尾的子串,称为后缀,如果后缀不等同于原来的字符串,称为真后缀。
2、暴力法字符串匹配
要查找字符串p在s中出现的位置,直观做法可以通过暴力枚举,采用双指针i遍历s,j遍历p,进行一一比对即可,代码如下:
for(int i = 0; i < s.size(); i++)
{
int j = 0;
while(s[i + j] == p[j]) j++;
if(j == p.size())
{
cout << i + 1 << endl; //出现的位置是字符串的下标再加1
}
}其核心思想是,从s的每一个位置开始,判断是否有子串和p的每一个字符都相等,如果中间有一个字符不相等,i往后移一位,j回到开头,重新比较。
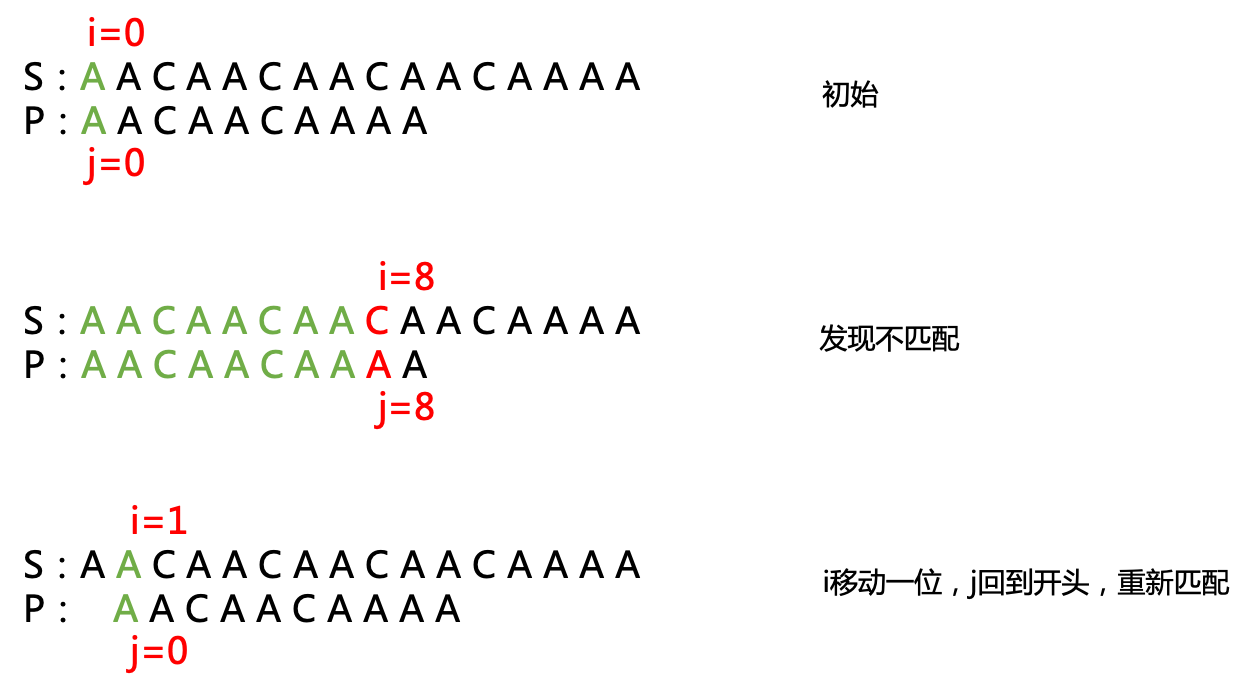
整个过程算法时间复杂度为s.size() * p.size()。
3、KMP算法思路
KMP算法主要是针对暴力算法的问题进行优化,当发现不匹配时,通过减少不必要的指针回退,从而提升双指针算法的效率。
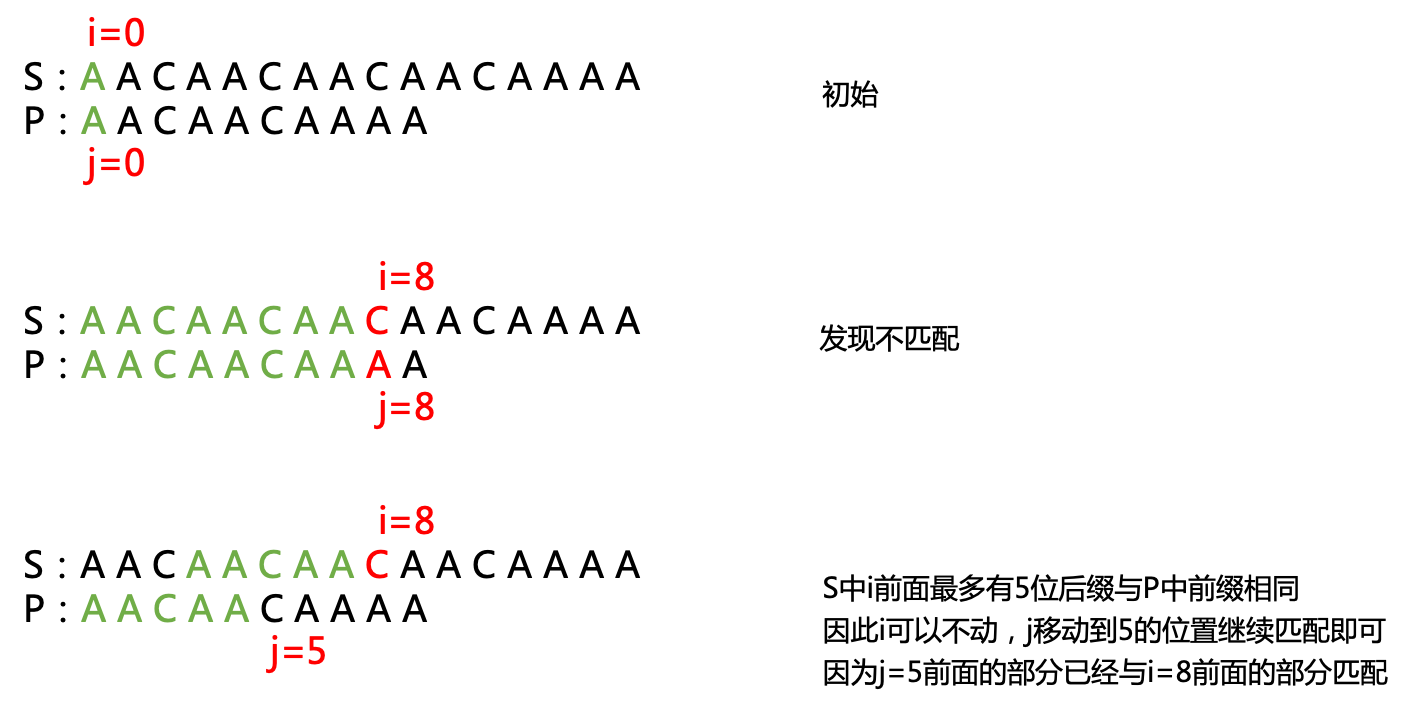
整个过程的核心就是当发现不匹配时,i不动,j移动到合适的位置继续匹配,由于此时p中j前面的内容都已经和s中i前面的内容匹配,
因此针对这一段已经匹配的内容s[0]~s[7]或者p[0] ~ p[7],如果能计算出其最长相同的真前、后缀长度,那么就可以将j移动到合适的位置。
如图中所示,此时最长相同真前后缀长度为5,因此可以将j移动到下标5的位置,继续和i=8进行匹配。
这样一来,整个过程时间复杂度可以认为是s.size() + p.size()。
疑惑点:匹配失败时,是否可能模式串的下次匹配位置不一定非得从p中j前面已经匹配的后缀开始,有没有可能从前后缀的中间某段开始?答案是不可能,如果前后缀中间有一个相同的匹配段,那么这个段也一定属于后缀的一部分,因此模式串的下次最大有效匹配位置一定是看后缀的。
4、Next数组
上面已经介绍,当发现不匹配的位置s[i] != p[j]时,j应该回退到p[0]~p[j-1]子串的最长相同真前后缀长度的位置,
那么,可以定义Next[j]表示从p[0]~p[j]子串的最长相同真前后缀长度
KMP的核心代码过程为:
int slen = s.size();
int plen = p.size();
for(int i = 0, j = 0; i < slen; i++)
{
while(j && s[i] != p[j]) j = Next[j - 1]; //如果不匹配,j跳转到Next[j-1]
if(s[i] == p[j]) j++; //如果匹配,j++,继续比较
if(j == plen)
找到一个完整的匹配;
}Next数组初始化
由于Next数组的计算只与p相关,因此可以提前对其进行初始化,我们仍然从暴力思路开始
P:A A C A A C A A A A
| Next数组 | 子串 | 最长相同真前后缀长度 |
| Next[0] | P[0] ~ P[0]:A | 0 |
| Next[1] | P[0] ~ P[1]:A A | 1 |
| Next[2] | P[0] ~ P[2]:A A C | 0 |
| Next[3] | P[0] ~ P[3]:A A C A | 1 |
| Next[4] | P[0] ~ P[4]:A A C A A | 2 |
| Next[5] | P[0] ~ P[5]:A A C A A C | 3 |
| Next[6] | P[0] ~ P[6]:A A C A A C A | 4 |
| Next[7] | P[0] ~ P[7]:A A C A A C A A | 5 |
| Next[8] | P[0] ~ P[8]:A A C A A C A A A | 2 |
| Next[9] | P[0] ~ P[9]:A A C A A C A A A A | 2 |
模式串p共有p.size()个从0开始的子串,对于每个子串,要计算最大相同真前后缀长度,可以从长度1开始枚举,比较前后缀是否相同,整体时间复杂度是n^2的。
Next数组的递推求法:
递推原理:
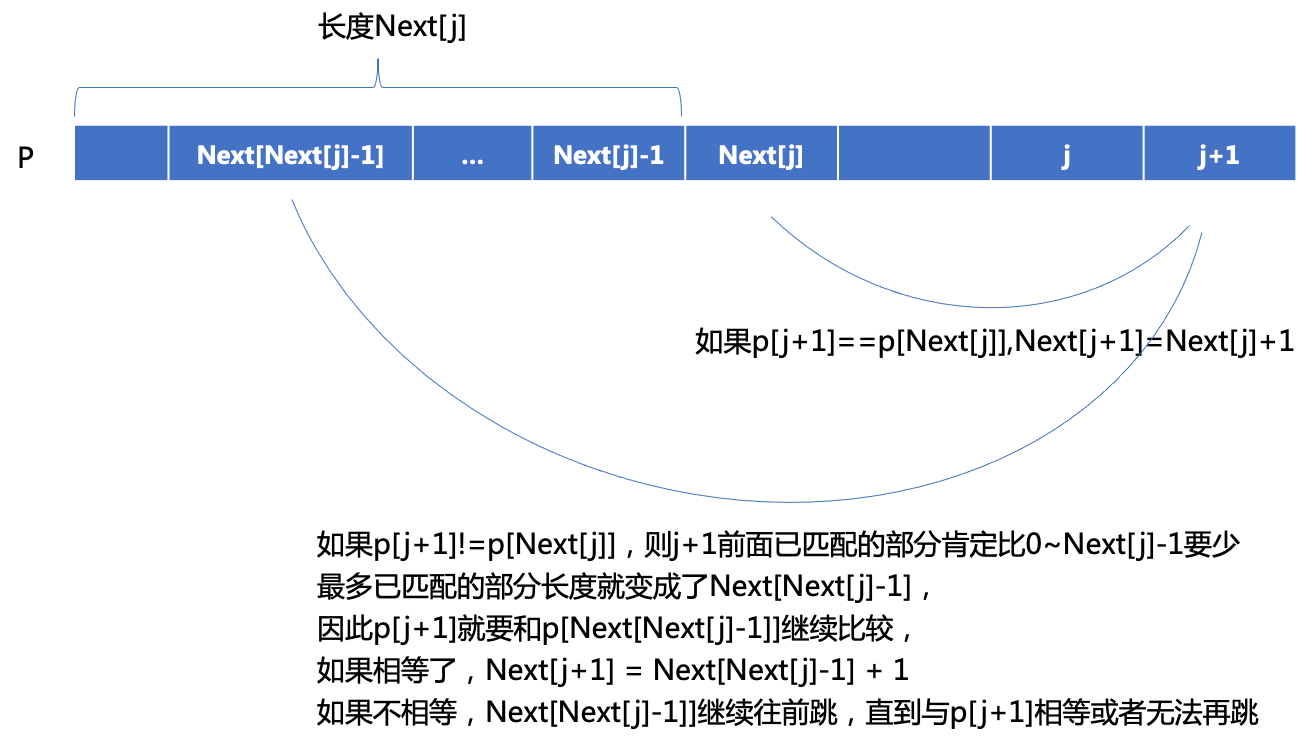
如果Next[j]已经求出,要求Next[j+1]
显然,从前缀0~Next[j]-1与后缀j-Next[j]+1~j是匹配的,下一个要比较的是j+1和Next[j],
那么当p[j+1]==p[Next[j]]时,显然Next[j+1] = Next[j]+1,最长相同前后缀长度加1,
当p[j+1]!=p[Next[j]]时,j+1应该跟Next[Next[j]-1]进行比较,如下图描述:
递推实现:
初始时,Next[0] = 0,因为一个字符的子串没有真前后缀,所以最长相同真前后缀长度是0。
采用双指针i = 1,j = 0均遍历p,
i代表要计算的p的子串最长真后缀结尾位置,即要计算Next[i],由于Next[0]已经初始化,所以i从1开始,
j代表要计算的p的子串最长真前缀结尾位置,
遍历i,
如果p[i] != p[j],j同样也要跳到Next[j-1]继续和p[i]比较,直到相等或者j==0。
如果p[i] == p[j],则j++,Next[i] = j,
计算Next的核心代码为:
for(int i = 1, j = 0; i < plen; i++)
{
while(j && p[i] != p[j]) j = Next[j - 1];
if(p[i] == p[j]) j++;
Next[i] = j;
}100分代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 1000005;
string s, p;
int Next[N];
int main()
{
cin >> s >> p;
int slen = s.size();
int plen = p.size();
//计算Next数组
for(int i = 1, j = 0; i < plen; i++)
{
while(j && p[i] != p[j]) j = Next[j - 1];
if(p[i] == p[j]) j++;
Next[i] = j;
}
//执行kmp算法
for(int i = 0, j = 0; i < slen; i++)
{
while(j && s[i] != p[j]) j = Next[j - 1];
if(s[i] == p[j]) j++;
if(j == plen)
{
cout << i - plen + 1 + 1 << endl; //出现的位置是字符串的下标再加1
j = Next[j - 1];
}
}
//输出Next数组
for(int i = 0; i < p.size(); i++) cout << Next[i] << " ";
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?