目标检测初体验(三)破解滑动验证码
在我们日常登录或注册某个网站的时候,经常会出现滑动验证码,如下图:

本文将会讲述如何利用darknet来破解滑动验证码,我们只要找到图片中的缺口就可以了。
数据的采集和标注
笔者利用爬虫在某网站爬取了约300张带缺口的滑动验证码的图片,并对这些验证码图片进行标注,即标注缺口的位置。
我们使用的标注工具为labelImg,这是图像标注方面一个非常好用的GUI工具。网上已经有很多关于安装labelImg的教程,本文不再具体介绍。我们打开labelImg,如下图:
在labelImg中我们选择打开目录,选择标注图片所在的目录,并进行标注。标注的时候,先选择创建区块,标注滑动验证码中缺口所在的矩形框,并保存其类别(这里我们将类别设置为box),标注的例子如下:
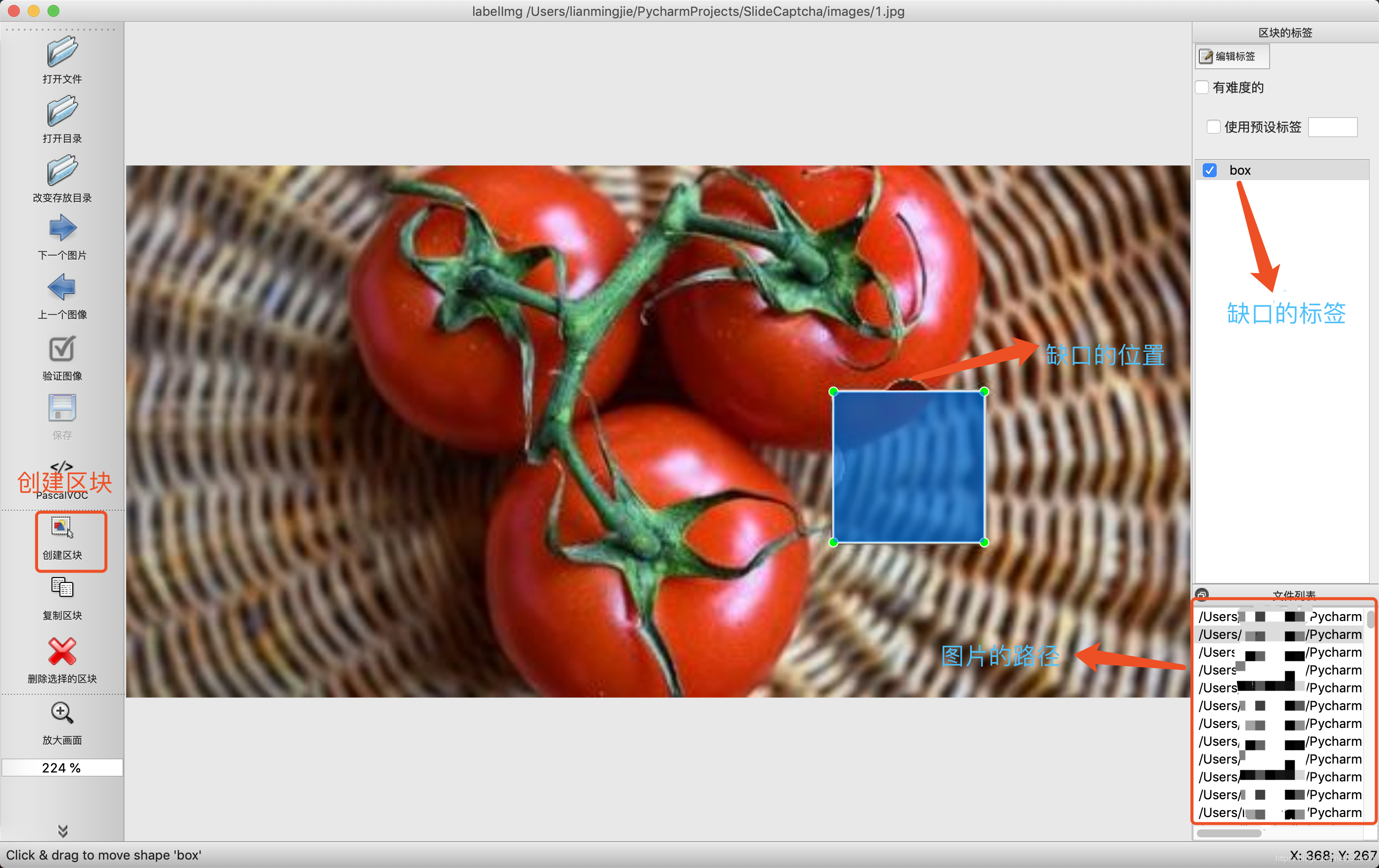
标注完当前图片后,点击保存,默认保存路径为标注图片所在文件夹,文件格式为xml,名字与图片名字一致,比如上图标注后生成的xml文件内容如下:
<annotation>
<folder>images</folder>
<filename>1.jpg</filename>
<path>/Users/jclian/PycharmProjects/SlideCaptcha/images/1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>480</width>
<height>240</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>box</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>319</xmin>
<ymin>102</ymin>
<xmax>387</xmax>
<ymax>170</ymax>
</bndbox>
</object>
</annotation>
上述的xml文件告诉我们很多信息,在size中我们可以知道标注图片的大小,在object中我们可以知道标注的矩形框的位置信息和类别名称。
在labelImg中点击下一张即可进行下一章图片的标注。我们需要花费不少时间来完成爬取的约300张图片的标注,不要怕麻烦。
数据处理
在这一步中,我们将把标注的图片进行数据处理,加工成darknet所支持的数据格式。
整个项目的结构如下:

我们的标注图片位于slide_train_images目录下,利用read_xml_2_label.py脚本,将标注的xml文档转化为darknet支持的txt形式,并记录训练图片的路径。脚本代码如下:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020/5/16 1:06 下午
import os
import xml.etree.ElementTree as ET
# change a single xml to txt
def single_xml_to_txt(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
# txt saved file path
if not os.path.exists("../slide_captcha_train_labels"):
os.system("mkdir ../slide_captcha_train_labels")
txt_file = "../slide_captcha_train_labels/%s" % xml_file.split("/")[-1].replace(".xml", ".txt")
with open(txt_file, 'w') as txt_file:
for member in root.findall('object'):
picture_width = int(root.find('size')[0].text)
picture_height = int(root.find('size')[1].text)
class_name = member[0].text
# 类名对应的index
class_num = class_names.index(class_name)
box_x_min = int(member[4][0].text) # 左上角横坐标
print(xml_file, "box_x_min", box_x_min)
box_y_min = int(member[4][1].text) # 左上角纵坐标
box_x_max = int(member[4][2].text) # 右下角横坐标
box_y_max = int(member[4][3].text) # 右下角纵坐标
# 转成相对位置和宽高
x_center = (box_x_min + box_x_max) / (2 * picture_width)
y_center = (box_y_min + box_y_max) / (2 * picture_height)
width = (box_x_max - box_x_min) / picture_width
height = (box_y_max - box_y_min) / picture_height
print(class_num, x_center, y_center, width, height)
txt_file.write(str(class_num) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(width) + ' ' + str(height) + '\n')
# 转换文件夹下的所有xml文件为txt
def dir_xml_to_txt(dir_path):
for file in os.listdir(dir_path):
if file.endswith(".xml"):
xml_file = os.path.join(dir_path, file)
single_xml_to_txt(xml_file)
with open("../slide_captcha_train.txt", "a", encoding="utf-8") as h:
if file.endswith(".jpg"):
h.write(os.path.join(dir_path, file).replace("../", "")+"\n")
if __name__ == '__main__':
# class name
class_names = ['box']
# path of XML files
dir_path = '../slide_captcha_train_images'
dir_xml_to_txt(dir_path)
生成的slide_captcha_train_labels下的0.txt文件的内容如下:
0 0.7604166666666666 0.44583333333333336 0.14166666666666666 0.2833333333333333
其中0为类别编号,这里只有一类,因此所有的类别编号均为0。后面的数字为标注的矩形框的x中心点,y中心点,宽度,高度与图片的宽度、高度的比值。同时,生成的slide_captcha_train.txt(记录训练图片的路径)的前几行如下:
slide_captcha_train_images/63.jpg
slide_captcha_train_images/189.jpg
slide_captcha_train_images/77.jpg
slide_captcha_train_images/162.jpg
slide_captcha_train_images/176.jpg
slide_captcha_train_images/88.jpg
slide_captcha.names存储本次识别的类别名称,即box;slide_captcha.data储存训练和验证数据信息,如下:
classes= 1
train = train.txt
valid = val.txt
names = slide_captcha.names
backup = backup
其中val.txt为空,模型训练过程中生成的模型文件保存在backup文件夹中。
模型训练
关于模型训练方面的具体步骤,可以参考文章 目标检测初体验(二)自制人脸检测功能 。
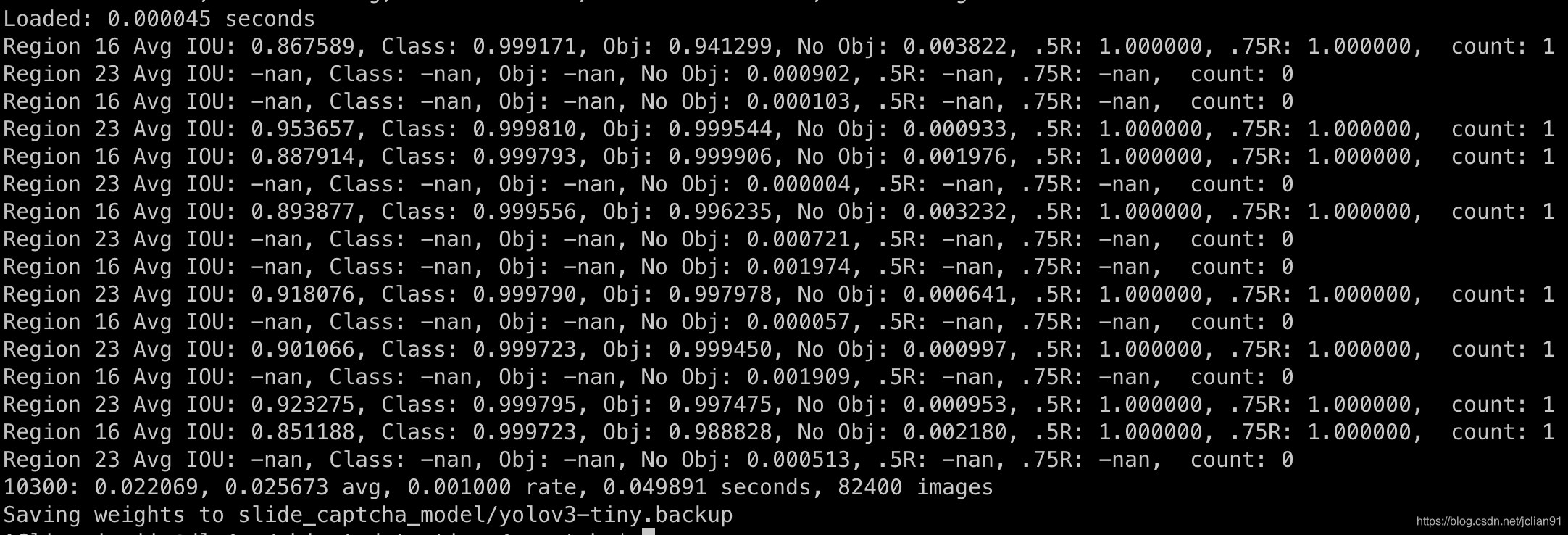
笔者在GPU上利用以下脚本进行模型训练:
./darknet detector train slide_captcha.data cfg/yolov3-tiny.cfg ./weights/darknet53.conv.74 --gpus 1,2,8,9
训练结果如下:
模型预测
我们利用已经训练好的模型对新的滑动验证码图片进行验证,使用以下命令:
./darknet detector test slide_captcha.data cfg/yolov3-tiny.cfg slide_captcha_model/yolov3-tiny.backup test_images/1.jpg -thresh 0.5 --gpus 1,2,8,9
下面给出在几张新的滑动验证码图片上的识别结果:



总结
darknet在目标检测方面的效果确实很不错,如果我们肯用心去想,也许还会有很多有趣的应用,笔者后面将会讲解点选验证码的识别和车牌识别等方面的内容。
CV在很多方面确实比NLP成熟很多,不管是模型,还是效果,还是应用。
本文中笔者用到的数据集稍后会公开至Github项目。同时,笔者也深感国内在共享数据集这方面确实做得不够好,很多文章会有这方面的内容,但却不会公开数据,这无疑是令人失望。
感谢大家的阅读,欢迎持续关注~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号