

Python爬虫之记录一次下载验证码的尝试
好久没有写过爬虫的文章了,今天在尝试着做验证码相关的研究时,遇到了验证码的收集问题。
一般,验证码的加载都有着比较复杂的算法和加密在里边,但是笔者今天碰到的验证码却比较幸运,有迹可循。在此,给出本爬虫的相关记录。
注意,文章和代码中均不会给出相关的真实网站的信息,避免不道德的行为。
首先,让我们来看一看该验证码的页面,如下:
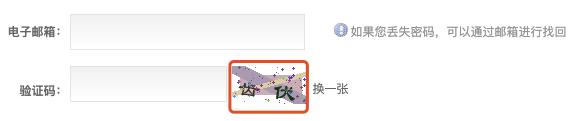
如果我们尝试着查看该验证码加载时的源代码,会发现源码如下:

我们可以发现,该验证码的加载机制其实并不复杂,只是在网址后面跟了一个时间戳,而这个时间戳,是由JavaScript中的方法产生的,函数内容为new Date().getTime()。
知道了验证码背后加载的原理,那么我们不难通过Python来实现验证码的下载。
可惜的是,上述JS函数产生的时间戳是13位数字,而Python的time.time()方法产生的时间戳为浮点数,小数点前10位,小数点后6位。那么,我们如果来产生符合上述JS函数产生的时间戳呢?
一个简单的想法是,我们让Python来调用JS。真的可以吗?幸运的是,前人已经提我们做好了这个工作,有个神奇的Python第三方模块,叫做PyExecJS。顾名思义,这个模块就是用来执行JS代码的。
该模块的源码中给出了一个例子,我们可以尝试下,代码如下:
# -*- coding: utf-8 -*-
import execjs
print(execjs.eval("'red yellow blue'.split(' ')"))
ctx = execjs.compile("""
function add(x, y) {
return x + y;
}
""")
print(ctx.call("add", 1, 2))
输出结果如下:
['red', 'yellow', 'blue']
3
OK,有了上面的例子,我们就知道如何使用该模块了,我们可以轻松地写出下面的代码来下载验证码了:
# -*- coding: utf-8 -*-
import execjs
import urllib.request
js_func = """
function get_milliseconds(){
return new Date().getTime();
}
"""
ctx = execjs.compile(js_func)
result = ctx.call("get_milliseconds")
print(len(str(result)))
# 注意,网址已经隐藏
url = "http://***/captcha/?%s" % result
urllib.request.urlretrieve(url, "1.png")
下载的验证码如下:
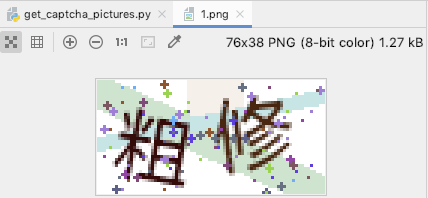
通过我们这次的尝试,发现如下:
- PyExecJS支持Python对JavaScript的操作,所以下次有机会,可以在Python中执行JS函数;
- 验证码的加载算法不宜简单,要注意加密。
本次分享到此结束,感谢大家的阅读~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2019-04-30 NLP入门(八)使用CRF++实现命名实体识别(NER)