

NLP入门(十)使用LSTM进行文本情感分析
情感分析简介
文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类。它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
本文将介绍情感分析中的情感极性(倾向)分析。所谓情感极性分析,指的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
本文将详细介绍如何使用深度学习模型中的LSTM模型来实现文本的情感分析。
文本介绍及语料分析
我们以某电商网站中某个商品的评论作为语料(corpus.csv),该数据集的下载网址为:https://github.com/renjunxiang/Text-Classification/blob/master/TextClassification/data/data_single.csv ,该数据集一共有4310条评论数据,文本的情感分为两类:“正面”和“反面”,该数据集的前几行如下:
evaluation,label
用了一段时间,感觉还不错,可以,正面
电视非常好,已经是家里的第二台了。第一天下单,第二天就到本地了,可是物流的人说车坏了,一直催,客服也帮着催,到第三天下午5点才送过来。父母年纪大了,买个大电视画面清晰,趁着耳朵还好使,享受几年。,正面
电视比想象中的大好多,画面也很清晰,系统很智能,更多功能还在摸索中,正面
不错,正面
用了这么多天了,感觉还不错。夏普的牌子还是比较可靠。希望以后比较耐用,现在是考量质量的时候。,正面
物流速度很快,非常棒,今天就看了电视,非常清晰,非常流畅,一次非常完美的购物体验,正面
非常好,客服还特意打电话做回访,正面
物流小哥不错,辛苦了,东西还没用,正面
送货速度快,质量有保障,活动价格挺好的。希望用的久,不出问题。,正面
接着我们需要对语料做一个简单的分析:
- 数据集中的情感分布;
- 数据集中的评论句子长度分布。
使用以下Python脚本,我们可以统计出数据集中的情感分布以及评论句子长度分布。
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from itertools import accumulate
# 设置matplotlib绘图时的字体
my_font = font_manager.FontProperties(fname="/Library/Fonts/Songti.ttc")
# 统计句子长度及长度出现的频数
df = pd.read_csv('./corpus.csv')
print(df.groupby('label')['label'].count())
df['length'] = df['evaluation'].apply(lambda x: len(x))
len_df = df.groupby('length').count()
sent_length = len_df.index.tolist()
sent_freq = len_df['evaluation'].tolist()
# 绘制句子长度及出现频数统计图
plt.bar(sent_length, sent_freq)
plt.title("句子长度及出现频数统计图", fontproperties=my_font)
plt.xlabel("句子长度", fontproperties=my_font)
plt.ylabel("句子长度出现的频数", fontproperties=my_font)
plt.savefig("./句子长度及出现频数统计图.png")
plt.close()
# 绘制句子长度累积分布函数(CDF)
sent_pentage_list = [(count/sum(sent_freq)) for count in accumulate(sent_freq)]
# 绘制CDF
plt.plot(sent_length, sent_pentage_list)
# 寻找分位点为quantile的句子长度
quantile = 0.91
#print(list(sent_pentage_list))
for length, per in zip(sent_length, sent_pentage_list):
if round(per, 2) == quantile:
index = length
break
print("\n分位点为%s的句子长度:%d." % (quantile, index))
# 绘制句子长度累积分布函数图
plt.plot(sent_length, sent_pentage_list)
plt.hlines(quantile, 0, index, colors="c", linestyles="dashed")
plt.vlines(index, 0, quantile, colors="c", linestyles="dashed")
plt.text(0, quantile, str(quantile))
plt.text(index, 0, str(index))
plt.title("句子长度累积分布函数图", fontproperties=my_font)
plt.xlabel("句子长度", fontproperties=my_font)
plt.ylabel("句子长度累积频率", fontproperties=my_font)
plt.savefig("./句子长度累积分布函数图.png")
plt.close()
输出的结果如下:
label
正面 1908
负面 2375
Name: label, dtype: int64
分位点为0.91的句子长度:183.
可以看到,正反面两类情感的比例差不多。句子长度及出现频数统计图如下:
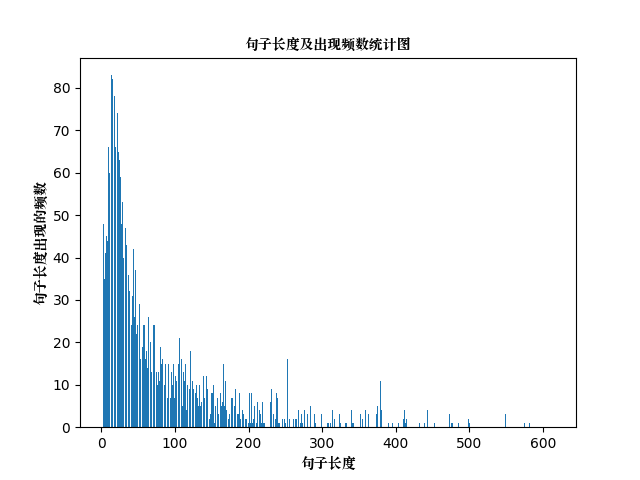
句子长度累积分布函数图如下:
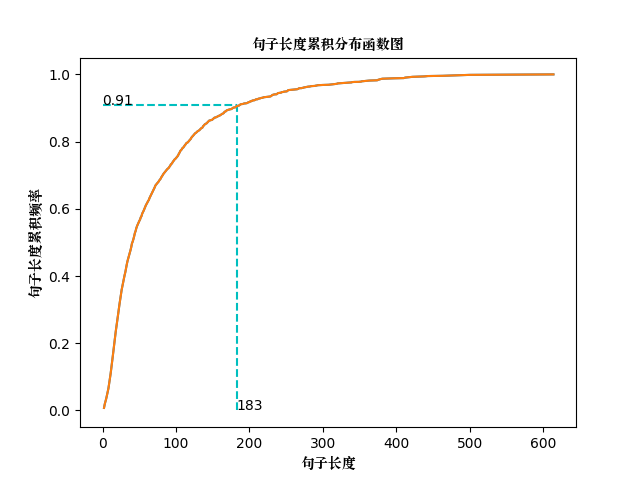
可以看到,大多数样本的句子长度集中在1-200之间,句子长度累计频率取0.91分位点,则长度为183左右。
使用LSTM模型
接着我们使用深度学习中的LSTM模型来对上述数据集做情感分析,笔者实现的模型框架如下:
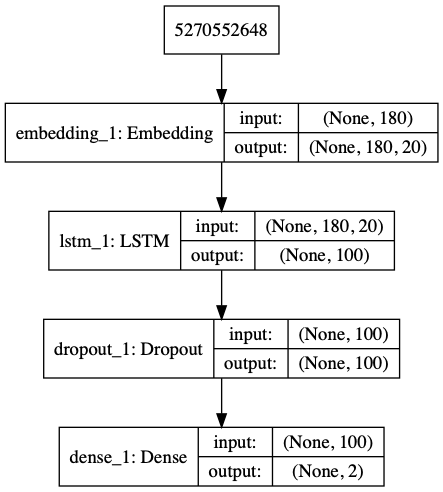
完整的Python代码如下:
# -*- coding: utf-8 -*-
import pickle
import numpy as np
import pandas as pd
from keras.utils import np_utils, plot_model
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.layers import LSTM, Dense, Embedding, Dropout
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 导入数据
# 文件的数据中,特征为evaluation, 类别为label.
def load_data(filepath, input_shape=20):
df = pd.read_csv(filepath)
# 标签及词汇表
labels, vocabulary = list(df['label'].unique()), list(df['evaluation'].unique())
# 构造字符级别的特征
string = ''
for word in vocabulary:
string += word
vocabulary = set(string)
# 字典列表
word_dictionary = {word: i+1 for i, word in enumerate(vocabulary)}
with open('word_dict.pk', 'wb') as f:
pickle.dump(word_dictionary, f)
inverse_word_dictionary = {i+1: word for i, word in enumerate(vocabulary)}
label_dictionary = {label: i for i, label in enumerate(labels)}
with open('label_dict.pk', 'wb') as f:
pickle.dump(label_dictionary, f)
output_dictionary = {i: labels for i, labels in enumerate(labels)}
vocab_size = len(word_dictionary.keys()) # 词汇表大小
label_size = len(label_dictionary.keys()) # 标签类别数量
# 序列填充,按input_shape填充,长度不足的按0补充
x = [[word_dictionary[word] for word in sent] for sent in df['evaluation']]
x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)
y = [[label_dictionary[sent]] for sent in df['label']]
y = [np_utils.to_categorical(label, num_classes=label_size) for label in y]
y = np.array([list(_[0]) for _ in y])
return x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary
# 创建深度学习模型, Embedding + LSTM + Softmax.
def create_LSTM(n_units, input_shape, output_dim, filepath):
x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary = load_data(filepath)
model = Sequential()
model.add(Embedding(input_dim=vocab_size + 1, output_dim=output_dim,
input_length=input_shape, mask_zero=True))
model.add(LSTM(n_units, input_shape=(x.shape[0], x.shape[1])))
model.add(Dropout(0.2))
model.add(Dense(label_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
plot_model(model, to_file='./model_lstm.png', show_shapes=True)
model.summary()
return model
# 模型训练
def model_train(input_shape, filepath, model_save_path):
# 将数据集分为训练集和测试集,占比为9:1
# input_shape = 100
x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary = load_data(filepath, input_shape)
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size = 0.1, random_state = 42)
# 模型输入参数,需要自己根据需要调整
n_units = 100
batch_size = 32
epochs = 5
output_dim = 20
# 模型训练
lstm_model = create_LSTM(n_units, input_shape, output_dim, filepath)
lstm_model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=1)
# 模型保存
lstm_model.save(model_save_path)
N = test_x.shape[0] # 测试的条数
predict = []
label = []
for start, end in zip(range(0, N, 1), range(1, N+1, 1)):
sentence = [inverse_word_dictionary[i] for i in test_x[start] if i != 0]
y_predict = lstm_model.predict(test_x[start:end])
label_predict = output_dictionary[np.argmax(y_predict[0])]
label_true = output_dictionary[np.argmax(test_y[start:end])]
print(''.join(sentence), label_true, label_predict) # 输出预测结果
predict.append(label_predict)
label.append(label_true)
acc = accuracy_score(predict, label) # 预测准确率
print('模型在测试集上的准确率为: %s.' % acc)
if __name__ == '__main__':
filepath = './corpus.csv'
input_shape = 180
model_save_path = './corpus_model.h5'
model_train(input_shape, filepath, model_save_path)
对上述模型,共训练5次,训练集和测试集比例为9:1,输出的结果为:
......
Epoch 5/5
......
3424/3854 [=========================>....] - ETA: 2s - loss: 0.1280 - acc: 0.9565
3456/3854 [=========================>....] - ETA: 1s - loss: 0.1274 - acc: 0.9569
3488/3854 [==========================>...] - ETA: 1s - loss: 0.1274 - acc: 0.9570
3520/3854 [==========================>...] - ETA: 1s - loss: 0.1287 - acc: 0.9568
3552/3854 [==========================>...] - ETA: 1s - loss: 0.1290 - acc: 0.9564
3584/3854 [==========================>...] - ETA: 1s - loss: 0.1284 - acc: 0.9568
3616/3854 [===========================>..] - ETA: 1s - loss: 0.1284 - acc: 0.9569
3648/3854 [===========================>..] - ETA: 0s - loss: 0.1278 - acc: 0.9572
3680/3854 [===========================>..] - ETA: 0s - loss: 0.1271 - acc: 0.9576
3712/3854 [===========================>..] - ETA: 0s - loss: 0.1268 - acc: 0.9580
3744/3854 [============================>.] - ETA: 0s - loss: 0.1279 - acc: 0.9575
3776/3854 [============================>.] - ETA: 0s - loss: 0.1272 - acc: 0.9579
3808/3854 [============================>.] - ETA: 0s - loss: 0.1279 - acc: 0.9580
3840/3854 [============================>.] - ETA: 0s - loss: 0.1281 - acc: 0.9581
3854/3854 [==============================] - 18s 5ms/step - loss: 0.1298 - acc: 0.9577
......
给父母买的,特意用了一段时间再来评价,电视非常好,没有坏点和损坏,界面也很简洁,便于操作,稍微不足就是开机会比普通电视慢一些,这应该是智能电视的通病吧,如果可以希望微鲸大大可以更新系统优化下开机时间~电视真的很棒,性价比爆棚,值得大家考虑购买。 客服很细心,快递小哥很耐心的等我通电验货,态度非常好。 负面 正面
长须鲸和海狮回答都很及时,虽然物流不够快但是服务不错电视不错,对比了乐视小米和微鲸论性价比还是微鲸好点 负面 负面
所以看不到4k效果,但是应该可以。 自带音响,中规中矩吧,好像没有别人说的好。而且,到现在没连接上我的漫步者,这个非常不满意,因为看到网上说好像普通3.5mm的连不上或者连上了声音小。希望厂家接下来开发的电视有改进。不知道我要不要换个音响。其他的用用再说。 放在地上的是跟我混了两年的tcl,天气受潮,修了一次,下岗了。 最后,我也觉得底座不算太稳,凑合着用。 负面 负面
电视机一般,低端机不要求那么高咯。 负面 负面
很好,两点下单上午就到了,服务很好。 正面 正面
帮朋友买的,好好好好好好好好 正面 正面
......
模型在测试集上的准确率为: 0.9020979020979021.
可以看到,该模型在训练集上的准确率为95%以上,在测试集上的准确率为90%以上,效果还是相当不错的。
模型预测
接着,我们利用刚刚训练好的模型,对新的数据进行测试。笔者随机改造上述样本的评论,然后预测其情感倾向。情感预测的Python代码如下:
# -*- coding: utf-8 -*-
# Import the necessary modules
import pickle
import numpy as np
from keras.models import load_model
from keras.preprocessing.sequence import pad_sequences
# 导入字典
with open('word_dict.pk', 'rb') as f:
word_dictionary = pickle.load(f)
with open('label_dict.pk', 'rb') as f:
output_dictionary = pickle.load(f)
try:
# 数据预处理
input_shape = 180
sent = "电视刚安装好,说实话,画质不怎么样,很差!"
x = [[word_dictionary[word] for word in sent]]
x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)
# 载入模型
model_save_path = './sentiment_analysis.h5'
lstm_model = load_model(model_save_path)
# 模型预测
y_predict = lstm_model.predict(x)
label_dict = {v:k for k,v in output_dictionary.items()}
print('输入语句: %s' % sent)
print('情感预测结果: %s' % label_dict[np.argmax(y_predict)])
except KeyError as err:
print("您输入的句子有汉字不在词汇表中,请重新输入!")
print("不在词汇表中的单词为:%s." % err)
输出结果如下:
输入语句: 电视刚安装好,说实话,画质不怎么样,很差!
情感预测结果: 负面
让我们再尝试着测试一些其他的评论:
输入语句: 物超所值,真心不错
情感预测结果: 正面
输入语句: 很大很好,方便安装!
情感预测结果: 正面
输入语句: 卡,慢,死机,闪退。
情感预测结果: 负面
输入语句: 这种货色就这样吧,别期待怎样。
情感预测结果: 负面
输入语句: 啥服务态度码,出了事情一个推一个,送货安装还收我50
情感预测结果: 负面
输入语句: 京东服务很好!但我买的这款电视两天后就出现这样的问题,很后悔买了这样的电视
情感预测结果: 负面
输入语句: 产品质量不错,就是这位客服的态度十分恶劣,对相关服务不予解释说明,缺乏耐心,
情感预测结果: 负面
输入语句: 很满意,电视非常好。护眼模式,很好,也很清晰。
情感预测结果: 负面
总结
当然,该模型并不是对一切该商品的评论都会有好的效果,还是应该针对特定的语料去训练,去预测。
本文主要介绍了LSTM模型在文本情感分析方面的应用,该项目已上传Github,地址为: https://github.com/percent4/Sentiment_Analysis 。
注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架