Python之将Python字符串生成PDF
笔者在今天的工作中,遇到了一个需求,那就是如何将Python字符串生成PDF。比如,需要把Python字符串‘这是测试文件’生成为PDF, 该PDF中含有文字‘这是测试文件’。
经过一番检索,笔者决定采用wkhtmltopdf这个软件,它可以将HTML转化为PDF。wkhtmltopdf的访问网址为:https://wkhtmltopdf.org/downloads.html ,读者可根据自己的系统下载对应的文件并安装。安装好wkhtmltopdf,我们再安装这个软件的Python第三方模块——pdfkit,安装方式如下:
pip install pdfkit
我们再讨论如下问题:
- 如何将Python字符串生成PDF;
- 如何生成PDF中的表格;
- 解决PDF生成速度慢的问题。
如何将Python字符串生成PDF
该问题的解决思路还是利用将Python字符串嵌入到HTML代码中解决,注意换行需要用<br>标签,示例代码如下:
import pdfkit
# PDF中包含的文字
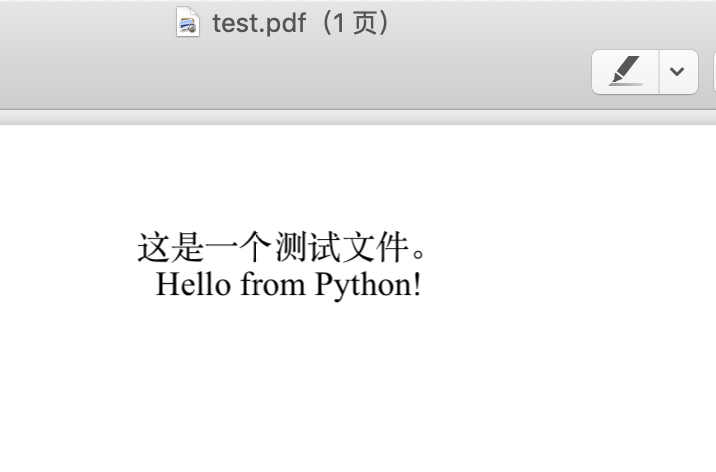
content = '这是一个测试文件。' + '<br>' + 'Hello from Python!'
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center"><p>%s</p></div></body></html>'%content
# 转换为PDF
pdfkit.from_string(html, './test.pdf')
输出的结果如下:
Loading pages (1/6)
Counting pages (2/6)
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
生成的test.pdf如下:
如何生成PDF中的表格
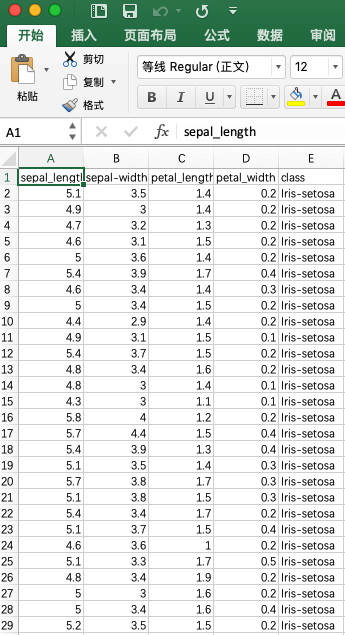
接下来我们考虑如何将csv文件转换为PDF中的表格,思路还是利用HTML代码。示例的iris.csv文件(部分)如下:
将csv文件转换为PDF中的表格的Python代码如下:
import pdfkit
# 读取csv文件
with open('iris.csv', 'r') as f:
lines = [_.strip() for _ in f.readlines()]
# 转化为html中的表格样式
td_width = 100
content = '<table width="%s" border="1" cellspacing="0px" style="border-collapse:collapse">' % (td_width*len(lines[0].split(',')))
for i in range(len(lines)):
tr = '<tr>'+''.join(['<td width="%d">%s</td>'%(td_width, _) for _ in lines[i].split(',')])+'</tr>'
content += tr
content += '</table>'
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './iris.pdf')
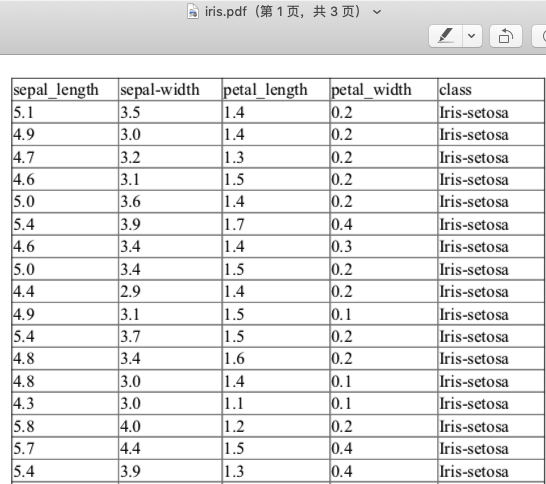
生成的PDF文件为iris.pdf,部分内容如下:
解决PDF生成速度慢的问题
用pdfkit生成PDF文件虽然方便,但有一个比较大的缺点,那就是生成PDF的速度比较慢,这里我们可以做个简单的测试,比如生成100份PDF文件,里面的文字为“这是第*份测试文件!”。Python代码如下:
import pdfkit
import time
start_time = time.time()
for i in range(100):
content = '这是第%d份测试文件!'%(i+1)
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './test/%s.pdf'%(i+1))
end_time = time.time()
print('一共耗时:%s 秒.' %(end_time-start_time))
在这个程序中,生成100份PDF文件一共耗时约192秒。输出结果如下:
......
Loading pages (1/6)
Counting pages (2/6)
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
一共耗时:191.9226369857788 秒.
如果想要加快生成的速度,我们可以使用多线程来实现,主要使用concurrent.futures模块,完整的Python代码如下:
import pdfkit
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
start_time = time.time()
# 函数: 生成PDF
def convert_2_pdf(i):
content = '这是第%d份测试文件!'%(i+1)
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './test/%s.pdf'%(i+1))
# 利用多线程生成PDF
executor = ThreadPoolExecutor(max_workers=10) # 可以自己调整max_workers,即线程的个数
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(convert_2_pdf, i) for i in range(100)]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
end_time = time.time()
print('一共耗时:%s 秒.' %(end_time-start_time))
在这个程序中,生成100份PDF文件一共耗时约41秒,明显快了很多~
注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号