
NLP入门(八)使用CRF++实现命名实体识别(NER)
CRF与NER简介
CRF,英文全称为conditional random field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫(Markov)随机场。
较为简单的条件随机场是定义在线性链上的条件随机场,称为线性链条件随机场(linear chain conditional random field). 线性链条件随机场可以用于序列标注等问题,而本文需要解决的命名实体识别(NER)任务正好可通过序列标注方法解决。这时,在条件概率模型P(Y|X)中,Y是输出变量,表示标记序列(或状态序列),X是输入变量,表示需要标注的观测序列。学习时,利用训练数据 集通过极大似然估计或正则化的极大似然估计得到条件概率模型p(Y|X);预测时,对于给定的输入序列x,求出条件概率p(y|x)最大的输出序列y0.

命名实体识别(Named Entity Recognition,简称NER)是信息提取、问答系统、句法分析、机器翻译等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。常见的实现NER的算法如下:
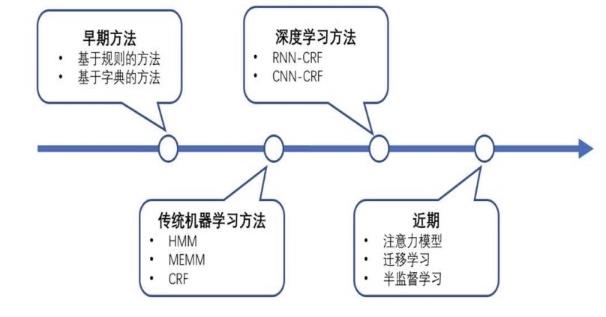
本文不准备详细介绍条件随机场的原理与实现算法,关于具体的原理与实现算法,可以参考《统计学习算法》一书。我们将借助已实现条件随机场的工具——CRF++来实现命名实体识别。关于用深度学习算法来实现命名实体识别, 可以参考文章:NLP入门(五)用深度学习实现命名实体识别(NER)。
CRF++
简介
CRF++是著名的条件随机场的开源工具,也是目前综合性能最佳的CRF工具,采用C++语言编写而成。其最重要的功能我认为是采用了特征模板。这样就可以自动生成一系列的特征函数,而不用我们自己生成特征函数,我们要做的就是寻找特征,比如词性等。关于CRF++的特性,可以参考网址:http://taku910.github.io/crfpp/ 。
安装
CRF++的安装可分为Windows环境和Linux环境下的安装。关于Linux环境下的安装,可以参考文章:CRFPP/CRF++编译安装与部署 。 在Windows中CRF++不需要安装,下载解压CRF++0.58文件即可以使用,下载网址为:https://blog.csdn.net/lilong117194/article/details/81160265 。
使用
1. 语料
以我们本次使用的命名实体识别的语料为例,作为CRF++训练的语料(前20行,每一句话以空格隔开。)如下:
played VBD O
on IN O
Monday NNP O
( ( O
home NN O
team NN O
in IN O
CAPS NNP O
) ) O
: : O
American NNP B-MISC
League NNP I-MISC
Cleveland NNP B-ORG
2 CD O
DETROIT NNP B-ORG
1 CD O
BALTIMORE VB B-ORG
需要注意字与标签之间的分隔符为制表符\t,否则会导致feature_index.cpp(86) [max_size == size] inconsistent column size错误。
2. 模板
模板是使用CRF++的关键,它能帮助我们自动生成一系列的特征函数,而不用我们自己生成特征函数,而特征函数正是CRF算法的核心概念之一。一个简单的模板文件如下:
# Unigram
U00:%x[-2,0]
U01:%x[0,1]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
# Bigram
B
在这里,我们需要好好理解下模板文件的规则。T**:%x[#,#]中的T表示模板类型,两个"#"分别表示相对的行偏移与列偏移。一共有两种模板:
- 第一种模板是Unigram template:第一个字符是U,用于描述unigram feature的模板。每一行%x[#,#]生成一个CRF中的点(state)函数: f(s, o), 其中s为t时刻的的标签(output),o为t时刻的上下文。假设
home NN O所在行为CURRENT TOKEN,
played VBD O
on IN O
Monday NNP O
( ( O
home NN O << CURRENT TOKEN
team NN O
in IN O
CAPS NNP O
) ) O
: : O
那么%x[#,#]的对应规则如下:
| template | expanded feature |
|---|---|
| %x[0,0] | home |
| %x[0,1] | NN |
| %x[-1,0] | ( |
| %x[-2,1] | NNP |
| %x[0,0]/%x[0,1] | home/NN |
| ABC%x[0,1]123 | ABCNN123 |
以“U01:%x[0,1]”为例,它在该语料中生成的示例函数如下:
func1 = if (output = O and feature="U01:NN") return 1 else return 0
func2 = if (output = O and feature="U01:N") return 1 else return 0
func3 = if (output = O and feature="U01:NNP") return 1 else return 0
....
- 第二种模板是Bigram template:第一个字符是B,每一行%x[#,#]生成一个CRFs中的边(Edge)函数:f(s', s, o), 其中s'为t–1时刻的标签。也就是说,Bigram类型与Unigram大致相同,只是还要考虑到t–1时刻的标签。如果只写一个B的话,默认生成f(s', s),这意味着前一个output token和current token将组合成bigram features。
3. 训练
CRF++的训练命令一般格式如下:
crf_learn -f 3 -c 4.0 template train.data model -t
其中,template为模板文件,train.data为训练语料,-t表示可以得到一个model文件和一个model.txt文件,其他可选参数说明如下:
-f, –freq=INT使用属性的出现次数不少于INT(默认为1)
-m, –maxiter=INT设置INT为LBFGS的最大迭代次数 (默认10k)
-c, –cost=FLOAT 设置FLOAT为代价参数,过大会过度拟合 (默认1.0)
-e, –eta=FLOAT设置终止标准FLOAT(默认0.0001)
-C, –convert将文本模式转为二进制模式
-t, –textmodel为调试建立文本模型文件
-a, –algorithm=(CRF|MIRA) 选择训练算法,默认为CRF-L2
-p, –thread=INT线程数(默认1),利用多个CPU减少训练时间
-H, –shrinking-size=INT 设置INT为最适宜的跌代变量次数 (默认20)
-v, –version显示版本号并退出
-h, –help显示帮助并退出
在训练过程中,会输出一些信息,其意义如下:
iter:迭代次数。当迭代次数达到maxiter时,迭代终止
terr:标记错误率
serr:句子错误率
obj:当前对象的值。当这个值收敛到一个确定值的时候,训练完成
diff:与上一个对象值之间的相对差。当此值低于eta时,训练完成
4. 预测
在训练完模型后,我们可以使用训练好的模型对新数据进行预测,预测命令格式如下:
crf_test -m model NER_predict.data > predict.txt
-m model表示使用我们刚刚训练好的model模型,预测的数据文件为NER_predict.data, > predict.txt表示将预测后的数据写入到predict.txt中。
NER实现实例
接下来,我们将利用CRF++来实现英文命名实体识别功能。
本项目实现NER的语料库如下(文件名为train.txt,一共42000行,这里只展示前15行,可以在文章最后的Github地址下载该语料库):
played on Monday ( home team in CAPS ) :
VBD IN NNP ( NN NN IN NNP ) :
O O O O O O O O O O
American League
NNP NNP
B-MISC I-MISC
Cleveland 2 DETROIT 1
NNP CD NNP CD
B-ORG O B-ORG O
BALTIMORE 12 Oakland 11 ( 10 innings )
VB CD NNP CD ( CD NN )
B-ORG O B-ORG O O O O O
TORONTO 5 Minnesota 3
TO CD NNP CD
B-ORG O B-ORG O
......
简单介绍下该语料库的结构:该语料库一共42000行,每三行为一组,其中,第一行为英语句子,第二行为句子中每个单词的词性,第三行为NER系统的标注,共分4个标注类别:PER(人名),LOC(位置),ORG(组织)以及MISC,其中B表示开始,I表示中间,O表示单字词,不计入NER,sO表示特殊单字词。
首先我们将该语料分为训练集和测试集,比例为9:1,实现的Python代码如下:
# -*- coding: utf-8 -*-
# NER预料train.txt所在的路径
dir = "/Users/Shared/CRF_4_NER/CRF_TEST"
with open("%s/train.txt" % dir, "r") as f:
sents = [line.strip() for line in f.readlines()]
# 训练集与测试集的比例为9:1
RATIO = 0.9
train_num = int((len(sents)//3)*RATIO)
# 将文件分为训练集与测试集
with open("%s/NER_train.data" % dir, "w") as g:
for i in range(train_num):
words = sents[3*i].split('\t')
postags = sents[3*i+1].split('\t')
tags = sents[3*i+2].split('\t')
for word, postag, tag in zip(words, postags, tags):
g.write(word+' '+postag+' '+tag+'\n')
g.write('\n')
with open("%s/NER_test.data" % dir, "w") as h:
for i in range(train_num+1, len(sents)//3):
words = sents[3*i].split('\t')
postags = sents[3*i+1].split('\t')
tags = sents[3*i+2].split('\t')
for word, postag, tag in zip(words, postags, tags):
h.write(word+' '+postag+' '+tag+'\n')
h.write('\n')
print('OK!')
运行此程序,得到NER_train.data, 此为训练集数据,NER_test.data,此为测试集数据。NER_train.data的前20行数据如下(以\t分隔开来):
played VBD O
on IN O
Monday NNP O
( ( O
home NN O
team NN O
in IN O
CAPS NNP O
) ) O
: : O
American NNP B-MISC
League NNP I-MISC
Cleveland NNP B-ORG
2 CD O
DETROIT NNP B-ORG
1 CD O
BALTIMORE VB B-ORG
我们使用的模板文件template内容如下:
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-1,0]/%x[0,0]
U06:%x[0,0]/%x[1,0]
U10:%x[-2,1]
U11:%x[-1,1]
U12:%x[0,1]
U13:%x[1,1]
U14:%x[2,1]
U15:%x[-2,1]/%x[-1,1]
U16:%x[-1,1]/%x[0,1]
U17:%x[0,1]/%x[1,1]
U18:%x[1,1]/%x[2,1]
U20:%x[-2,1]/%x[-1,1]/%x[0,1]
U21:%x[-1,1]/%x[0,1]/%x[1,1]
U22:%x[0,1]/%x[1,1]/%x[2,1]
# Bigram
B
接着训练该数据,命令如下:
crf_learn -c 3.0 template NER_train.data model -t
运行时的输出信息如下:

在笔者的电脑上一共迭代了193次,运行时间为490.32秒,标记错误率为0.00004,句子错误率为0.00056。
接着,我们需要在测试集上对该模型的预测表现做评估。预测命令如下:
crf_test -m model NER_test.data > result.txt
使用Python脚本统计预测的准确率,代码如下:
# -*- coding: utf-8 -*-
dir = "/Users/Shared/CRF_4_NER/CRF_TEST"
with open("%s/result.txt" % dir, "r") as f:
sents = [line.strip() for line in f.readlines() if line.strip()]
total = len(sents)
print(total)
count = 0
for sent in sents:
words = sent.split()
# print(words)
if words[-1] == words[-2]:
count += 1
print("Accuracy: %.4f" %(count/total))
# 0.9706
输出的结果如下:
21487
Accuracy: 0.9706
由此可见,在测试集上的准确率高达0.9706,效果相当好。
最后,我们对新数据进行命名实体识别,看看模型在新数据上的识别效果。实现的Python代码如下:
# -*- coding: utf-8 -*-
import os
import nltk
dir = "/Users/Shared/CRF_4_NER/CRF_TEST"
sentence = "Venezuelan opposition leader and self-proclaimed interim president Juan Guaidó said Thursday he will return to his country by Monday, and that a dialogue with President Nicolas Maduro won't be possible without discussing elections."
#sentence = "Real Madrid's season on the brink after 3-0 Barcelona defeat"
# sentence = "British artist David Hockney is known as a voracious smoker, but the habit got him into a scrape in Amsterdam on Wednesday."
# sentence = "India is waiting for the release of an pilot who has been in Pakistani custody since he was shot down over Kashmir on Wednesday, a goodwill gesture which could defuse the gravest crisis in the disputed border region in years."
# sentence = "Instead, President Donald Trump's second meeting with North Korean despot Kim Jong Un ended in a most uncharacteristic fashion for a showman commander in chief: fizzle."
# sentence = "And in a press conference at the Civic Leadership Academy in Queens, de Blasio said the program is already working."
#sentence = "The United States is a founding member of the United Nations, World Bank, International Monetary Fund."
default_wt = nltk.word_tokenize # 分词
words = default_wt(sentence)
print(words)
postags = nltk.pos_tag(words)
print(postags)
with open("%s/NER_predict.data" % dir, 'w', encoding='utf-8') as f:
for item in postags:
f.write(item[0]+' '+item[1]+' O\n')
print("write successfully!")
os.chdir(dir)
os.system("crf_test -m model NER_predict.data > predict.txt")
print("get predict file!")
# 读取预测文件redict.txt
with open("%s/predict.txt" % dir, 'r', encoding='utf-8') as f:
sents = [line.strip() for line in f.readlines() if line.strip()]
word = []
predict = []
for sent in sents:
words = sent.split()
word.append(words[0])
predict.append(words[-1])
# print(word)
# print(predict)
# 去掉NER标注为O的元素
ner_reg_list = []
for word, tag in zip(word, predict):
if tag != 'O':
ner_reg_list.append((word, tag))
# 输出模型的NER识别结果
print("NER识别结果:")
if ner_reg_list:
for i, item in enumerate(ner_reg_list):
if item[1].startswith('B'):
end = i+1
while end <= len(ner_reg_list)-1 and ner_reg_list[end][1].startswith('I'):
end += 1
ner_type = item[1].split('-')[1]
ner_type_dict = {'PER': 'PERSON: ',
'LOC': 'LOCATION: ',
'ORG': 'ORGANIZATION: ',
'MISC': 'MISC: '
}
print(ner_type_dict[ner_type], ' '.join([item[0] for item in ner_reg_list[i:end]]))
识别的结果如下:
MISC: Venezuelan
PERSON: Juan Guaidó
PERSON: Nicolas Maduro
识别有个地方不准确, Venezuelan应该是LOC,而不是MISC. 我们再接着测试其它的新数据:
输入语句1:
Real Madrid's season on the brink after 3-0 Barcelona defeat
识别效果1:
ORGANIZATION: Real Madrid
LOCATION: Barcelona
输入语句2:
British artist David Hockney is known as a voracious smoker, but the habit got him into a scrape in Amsterdam on Wednesday.
识别效果2:
MISC: British
PERSON: David Hockney
LOCATION: Amsterdam
输入语句3:
India is waiting for the release of an pilot who has been in Pakistani custody since he was shot down over Kashmir on Wednesday, a goodwill gesture which could defuse the gravest crisis in the disputed border region in years.
识别效果3:
LOCATION: India
LOCATION: Pakistani
LOCATION: Kashmir
输入语句4:
Instead, President Donald Trump's second meeting with North Korean despot Kim Jong Un ended in a most uncharacteristic fashion for a showman commander in chief: fizzle.
识别效果4:
PERSON: Donald Trump
PERSON: Kim Jong Un
输入语句5:
And in a press conference at the Civic Leadership Academy in Queens, de Blasio said the program is already working.
识别效果5:
ORGANIZATION: Civic Leadership Academy
LOCATION: Queens
PERSON: de Blasio
输入语句6:
The United States is a founding member of the United Nations, World Bank, International Monetary Fund.
识别效果6:
LOCATION: United States
ORGANIZATION: United Nations
PERSON: World Bank
ORGANIZATION: International Monetary Fund
在这些例子中,有让我们惊喜之处:识别出了人物Donald Trump, Kim Jong Un. 但也有些不足指出,如将World Bank识别为人物,而不是组织机构。总的来说,识别效果还是让人满意的。
总结
最近由于工作繁忙,无暇顾及博客。但转念一想,技术输出也是比较重要的,需要长期坚持下去~
本项目的Github地址为:https://github.com/percent4/CRF_4_NER 。
五一将至,祝大家假期愉快~

