
词项字段权重计算
今天学习的是第6章,关于词项权重方面的,重要性还是很大的。在电商搜索应用中,用到这的地方很多。比如我们搜索商品时,商品的属性很多,如“标题”,“描述”。我们要匹配的关键字只要满足这些属性之一就返回,这时候我们一般对不同属性不会一视同仁,比如“标题”中匹配的重要性就要比“描述”内容更大,更应该排在前面返回。
假设我们现在做一个在线电商的项目,商品有两个属性字段,分别是“标题(title)”和“描述(desc)”,还是跟之前一样我们可以写出如下的倒排表:
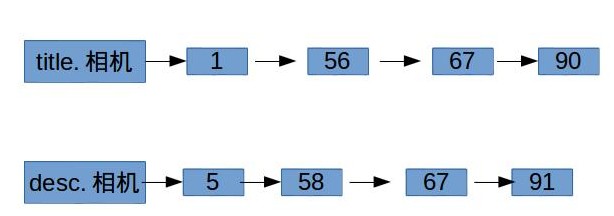
有了如上结构的倒排表,可以通过布尔函数来查询两个字段的组合查询,比如“标题中包含相机或者描述中包含单反”的所有商品。上述倒排表把每个字段属性当成一个独立的索引域,这样有个问题就是会导致倒排表的字典规模会比较大,特别是字段属性很多时。所有还有一种结构表示方法,如下:
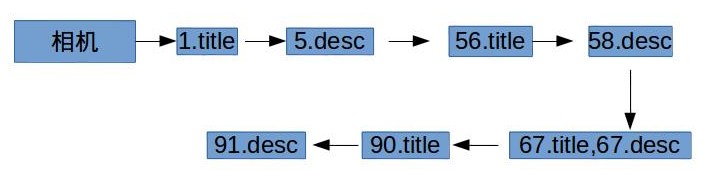
好处显而易见,字典规模不会随着属性字段增长而成倍增长,这在很多场景很有用的,比如字典放在内存中。还有一个优势,方便域加权计算(weightd zone scoring)排序。
域加权评分
域加权评分公式:\(\sum_{i=1}^{l}g_is_i\) ,其中 \(g_i\) 为权重,值在[0-1]之间,且满足\(\sum_{i=1}^{l}g_i=1\),\(s_i\)为查询和文档的匹配情况,如为0表示不匹配,1为匹配。当然这个计算公司可以随便定义,不只是限定要布尔函数计算。现在问题产生了,即我们怎样确定\(g_1,g_2,g_3\dots,g_l\)的值呢?这就引入机器学习的东西了,给定一定数量的样本,先人工判断预先设置一个固定的结果值,然后不断调整变量g,计算出不同的结果并和预期设置的结果相比,误差最小的值就是我们想要的。至于根据样本计算求值的过程,需要了解数学中的规划求解知识。
频率及权重计算
到现在为止,基本上所有根据词项搜索出满足要求文档集,它们都没有优先级的概念。而现实的需求不只是这样,想像下这个场景,在一个数码产品电商系统中,如果输入“苹果”,这样会把所有包含有“苹果”的商品都会搜索出来。但是我们更希望那些出现“苹果”次数多的商品排在更前面,原理很简单,出现的次数越多,说明相关性更高。词项t在文档d中出现的次数称为词项频率(term frequency),记为 \(tf_{t,d}\)。但是这里要引入一个概念叫做:逆文档频率。什么叫逆文档频率呢?先说下什么叫做文档频率。这里还是以具体场景举例,还是以上面的数码电商系统为例,比如“苹果”在1867个商品描述中出现过,则可以说“苹果”的文档频率是1867。而“手机”这个词在5693个商品描述中出现过,所以说“手机”的文档频率是5693。现在问题来了,如果用户输入“苹果手机”这个短语搜索,根据中文分词后再处理,会把所有包含“苹果”和“手机”关键词的商品都会搜索出来,而且“手机”关键字出现的次数肯定会比“苹果”多(原因是在数码电商手机分类中,基本每个商品描述都会有“手机”关键词),如果单按前面说的“词项频率”来计权排序,很有可能会把一些商品中出现“手机”次数很多的商品排在前面,但是这类商品中又没有包含“苹果”,这是违背用户的意愿的。为什么会出现这个问题呢?原因就是“手机”关键词基本会在每个商品描述中出现,它的意义倒显得不是很重要了。相反,“苹果”虽然只在少数商品中出现,但是每一次的出现,都应该计算更多的权值,因为它更能代表用户的搜索意愿。所以可以得出这个结论:一个词出现在文档的数量越多,它的权重越低。我们用 \(df_t\) 来标记文档频率。但是大家应该会发现,在实际场景中,“文档频率”的值是会很多大的,特别是海量数据系统中,这对于计算权重是很不方便和浪费(因为权重的目的是:体现两个值的相对大小,而单个值是没有意义的),所以可以通过对数函数来大副缩小这个值。我们如下方式来表达“逆文档频率”:
\begin{equation} idf_t=\log\frac{N}{df_t} \end{equation}
其中N是所有文档的数量。所以$idf_t$最大值不会超过$\log{N}$。现在我们计算一个词项在某个文档中出现时的权重计算公式:$tf-idf_t=tf_d*idf_t$。这个综合公式即考虑到了词项频率,也考虑了逆文档频率。向量空间模型
我们在网络上看博客或者新闻时,经常在旁边给出一些与此文章相似的文章推荐,计算两个文档的相似度经常要用到向量空间模型来计算。文档是由有限的词项组成的,我们说两篇文档看起来一样,从第一感受上来说就是它们基本上包含了相同的词项,并且各个词项出现的频率差不多。所以每们把每一篇文档看成一个向量值,各个分量值由组成文档的各个词项在文档中所占的分量比例。这样,两篇文档的相似度就转化成了两个向量值的夹角大小。正如下图,在2维平面空间上,两个向量的差距就是看它们的夹角大小:
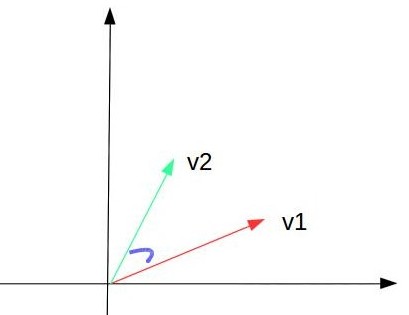
我们用向量的内积运算结果作为相似度值。为了使结果只关注本身的相似度值,做规一划处理。每个向量通过向量长度做规一化处理后再计算内积。
\begin{equation} sim(d_1,d_2)=\frac{\overrightarrow{V}(d_1).\overrightarrow{V}(d_2)}{|\overrightarrow{V}(d_1)||\overrightarrow{V}(d_1)|} \end{equation}
我们根据一个查询短语查找相关联的所有文档,并按相似度从大到小返回,可以按这样的计算思路来:把查询短语也看到一篇文档,分别和所有的文档进行相似度计算,按从大到小的值排序返回。快速评分,排序
这里用一段伪代码来描述下如何计算给定一个查询q,计算并找出排在前M位的文档。下面我们简化了查询q中每个词项的权重,存在的词项都是相同的权重且设置为1,其实这是不影响总体排序的,因为排序是用相对比较而不是绝对值。
def calScore(q):
# 初始文档的评分为0,文档长度为N
scores = [0 for i in range(N)]
for t in q:
# 遍历查询q中所有的词项
for d in post_list(t):
# 遍历词项t的倒排记录表,累加词项和文档的权重
scores[d] += wf_td
# 获取权重最高的前M个数据
return top M of scores
分析上面的算法,很明显的感觉就是,这样的计算量太大了。如果查询有m个词项,这m个词项的倒排表长度分别是\(l_1,l_2,l_3,\dots l_m\),则整个计算量是\(\sum_{i=1}^{m} l_i\)。特别是如果查询词项中某个或某几个词项的倒排表长度很长时,计算量显得会很大。所以我们要用到一些技巧手法去优化下。
索引去除
最容易想到的优化点,就是我们可不可以考虑针对原始查询做一些取舍,只关注查询中那些idf值比较高的那些词,即文档频率高的那些词。举个例子,我们在3C电商搜索中,根据“苹果手机”检索出排名最高的前20个商品。根据以往做法,根据分词后的“苹果”和“手机”两个词分别找到相应的倒排表,并依次扫描计算出最终的所有关联的商品,并根据计算的权重值按从高到低排序,并取出前20个商品。但是细想下,针对3C商城来说,一个商品中包含“苹果”已经足够说明用户的意愿。而“手机”基本会出现在所有手机商品描述中,它的idf值是很低的,想当于那些“的,地,是”之类的停用词。所以可以把这些idf值低的词直接去掉,而这些词的倒排表是很长的,所以可以节省很大部分的计算量。
胜者表(champion list)
上面的索引去除方法是从查询进行优化裁剪。胜者表是从倒排表进行处理优化。我们针对每个查询词项,只取其倒排表中排名靠前的r个文档。这个r值的设置根据场景不同而异。而排名的依据可以用tf(词项频率)。
簇剪枝方法(cluster pruning)
顾名思义,这个方法就是把所有文档随机(随机是重点,要保证抽取的均匀分布性)抽取\(\sqrt{N}\)(N是文档总数量)个出来,把它们分成\(\sqrt{N}\)堆,记为leader结点。然后把其它剩余的文档分别划到这\(\sqrt{N}\)堆中去。划分的标准是该文档和哪堆的相似度最高就划到哪里,即分别计算出余弦相似度比较最大的值。这样当根据查询短语检索文档时,只要找出和这些事先分堆的\(\sqrt{N}\)个leader结点最相似的一个,然后分别和该leader结点所在的堆中的其它做计算比较。其实该算法的重点是概率数学知识了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号