


filebeat+redis+logstash+elasticsearch+kibana搭建日志分析系统
filebeat+redis+elk搭建日志分析系统
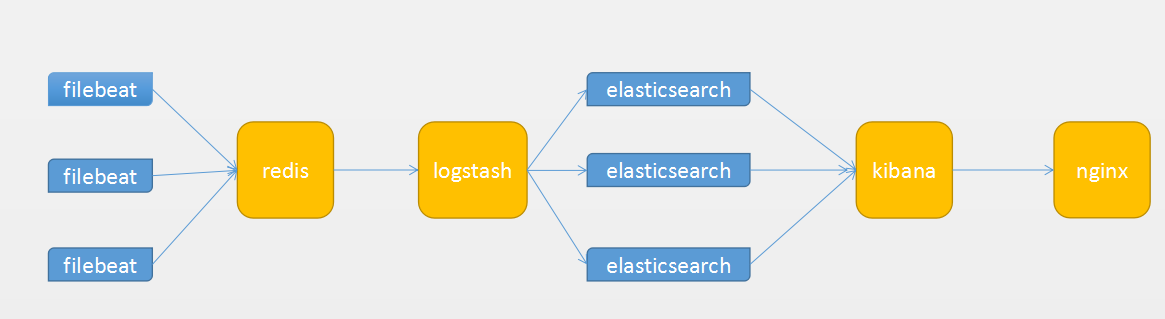
各个组件作用:
filebeat:具有日志收集功能,是下一代的Logstash收集器,但是filebeat更轻量,占用资源更少,适合客户端使用。
redis:Redis 服务器通常都是用作 NoSQL 数据库,不过 logstash 只是用来做消息队列。
logstash:主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
elasticsearch:Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
kibana:Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
https://www.elastic.co下载相应的安装包
1、filebeat安装配置:
vim /usr/local/ELK/filebeat-6.3.1-linux-x86_64/filebeat.yml
1 - type: log 2 3 # Change to true to enable this input configuration. 4 enabled: true 5 6 paths: 7 - '/data/nginx-logs/*access*' #定义日志路径 8 #json.keys_under_root: true #默认这个值是FALSE的,也就是我们的json日志解析后会被放在json键上。设为TRUE,所有的keys就会被放到根节点。 9 #json.overwrite_keys: true #是否要覆盖原有的key,这是关键配置,将keys_under_root设为TRUE后,再将overwrite_keys也设为TRUE,就能把filebeat默认的key值给覆盖了。 10 #fields_under_root: true #如果该选项设置为true,则新增fields成为顶级目录,而不是将其放在fields目录下,自定义的field会覆盖filebeat默认的field。 11 #exclude_lines: ['^DBG',"^$"] #排除以DBG开头和空行 12 tags: ["json_nginxaccess"] #列表中添加标签,用过过滤 13 document_type: json-nginxaccess #设定Elasticsearch输出时的document的type字段 可以用来给日志进行分类。Default: log 14 tail_files: true #Filebeat从文件尾开始监控文件新增内容,非从头开始 15 16 #fields: 17 # log_source: nginx 18 19 - type: log 20 enabled: true 21 paths: 22 - '/data/nginx-logs/*error*' 23 #json.keys_under_root: true 24 #json.overwrite_keys: true 25 tags: ["json_nginxerror"] 26 document_type: json-nginxerror 27 28 29 output.redis: 30 hosts: ["192.168.32.231"] #输出到redis的机器 31 port: 6379 #redis端口号 32 db: 2 #redis数据库的一个整数索引标识,redis不同于mysql有一个库的名字。redis总共0-15默认16个库。 33 timeout: 5 #连接超时时间 34 key: "default_list" #以default_list的keys传输到redis
启动filebeat
集群机器启动filebeat,通过key传到redis,logstash通过tags用来过滤
##redis安装启动步骤略
/usr/local/ELK/filebeat-6.3.1-linux-x86_64/filebeat &
2、elasticsearch集群的安装启动
修改配置文件 vim /usr/local/ELK/elasticsearch-6.3.0/config/elasticsearch.yml
1 cluster.name: cc-cluster #集群名称(自定义) 2 node.name: cc-1 #节点名称(自定义) 3 node.master: true #是否有资格成为master主节点,如只做存储则为false 4 node.data: true #是否做存储节点,当这两个都为false时,该节点作为client 5 path.data: /usr/local/ELK/elasticsearch-6.3.0/data #数据存储目录 6 path.logs: /usr/local/ELK/elasticsearch-6.3.0/logs #日志存储目录 7 network.host: 192.168.32.231 #监听本地ip 8 http.port: 9200 #http监听端口 9 #transport.tcp.port: 9300 #tcp通讯端口 10 #transport.tcp.compres: true 11 gateway.recover_after_nodes: 2 #一个集群中的N个节点启动后,才允许进行恢复处理 12 #gateway.recover_after_time: 5 #设置初始化恢复过程的超时时间,超时时间从上一个配置中配置的N个节点启动后算起 13 gateway.expected_nodes: 1 # 设置这个集群中期望有多少个节点.一旦这N个节点启动(并且recover_after_nodes也符合),立即开始恢复过程(不等待recover_after_time超时) 14 bootstrap.memory_lock: true #锁定内存,阻止操作系统管理内存,可以有效的防止内存数据被交换到磁盘空间,交换过程中磁盘会抖动,会对性能产生较大的影响。因为ES是基于JAVA开发的可以能过垃圾回收器来单独管理内存,所以关闭操作系统级别的内存管理可以提升性能 15 bootstrap.system_call_filter: false #关闭操作系统内核验证 16 17 discovery.zen.ping.unicast.hosts: ["192.168.32.231","192.168.32.230","192.168.32.232"] #集群初始化连接列表,节点启动后,首先通过连接初始化列表里的地址去发现集群。 18 discovery.zen.minimum_master_nodes: 2 #为了防止集群脑裂,目前的策略是当且仅当节点有超过半数的master候选者存活时(当前两台master),集群才会进行master选举
master节点
主要功能是维护元数据,管理集群各个节点的状态,数据的导入和查询都不会走master节点,所以master节点的压力相对较小,因此master节点的内存分配也可以相对少些;但是master节点是最重要的,如果master节点挂了或者发生脑裂了,你的元数据就会发生混乱,那样你集群里的全部数据可能会发生丢失,所以一定要保证master节点的稳定性。
data node
是负责数据的查询和导入的,它的压力会比较大,它需要分配多点的内存,选择服务器的时候最好选择配置较高的机器(大内存,双路CPU,SSD... 土豪~);data node要是坏了,可能会丢失一小份数据。
client node
是作为任务分发用的,它里面也会存元数据,但是它不会对元数据做任何修改。client node存在的好处是可以分担下data node的一部分压力;为什么client node能分担data node的一部分压力?因为es的查询是两层汇聚的结果,第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node接收到data node发来的结果后再做第二次的汇聚,然后把最终的查询结果返回给用户;所以我们看到,client node帮忙把第二层的汇聚工作处理了,自然分担了data node的压力。
这里,我们可以举个例子,当你有个大数据查询的任务(比如上亿条查询任务量)丢给了es集群,要是没有client node,那么压力直接全丢给了data node,如果data node机器配置不足以接受这么大的查询,那么就很有可能挂掉,一旦挂掉,data node就要重新recover,重新reblance,这是一个异常恢复的过程,这个过程的结果就是导致es集群服务停止... 但是如果你有client node,任务会先丢给client node,client node要是处理不来,顶多就是client node停止了,不会影响到data node,es集群也不会走异常恢复。
对于es 集群为何要设计这三种角色的节点,也是从分层逻辑去考虑的,只有把相关功能和角色划分清楚了,每种node各尽其责,才能发挥出分布式集群的效果。
根据业务需求配置master、client、node。启动elasticsearch
/usr/local/ELK/elasticsearch-6.3.0/bin/elasticsearch -d
查看集群状态
curl http://192.168.32.231:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.32.231 20 88 2 0.61 0.43 0.37 mdi * cc-1 # *为主节点
192.168.32.230 29 62 0 0.00 0.00 0.00 mdi - cc-2
192.168.32.232 35 52 1 0.04 0.06 0.05 mdi - cc-3
可能遇到的问题:
问题1:max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
max number of threads [1024] for user [lishang] likely too low, increase to at least [2048]
解决:shell>sudo vi /etc/security/limits.conf* hard nofile 65536
* soft nofile 65536
elk soft memlock unlimited
elk hard memlock unlimited
问题2:max number of threads [1024] for user [lish] likely too low, increase to at least [2048]
解决:shell>sudo vi /etc/security/limits.d/90-nproc.conf
* hard nproc 20480
问题3:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
解决:shell>sudo vi /etc/sysctl.conf shell>sudo sysctl -p
3、logstash配置启动
vim /usr/local/ELK/logstash-6.3.0/conf/filebeat_redis.conf
nginx日志为json格式
log_format json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"service":"nginxTest",'
'"trace":"$upstream_http_ctx_transaction_id",'
'"log":"log",'
'"clientip":"$remote_addr",'
'"remote_user":"$remote_user",'
'"request":"$request",'
'"http_user_agent":"$http_user_agent",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"url":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"status":"$status"}';
1 input { 2 redis { 3 data_type => "list" #支持三种 data_type(实际上是redis_type),不同的数据类型会导致实际采用不同的 Redis 命令操作:1、list => BLPOP 2、channel => SUBSCRIBE 3、pattern_channel => PSUBSCRIBE 4 key => "default_list" #filebeat定义的key 5 host => "192.168.32.231" 6 port => 6379 7 db => 2 8 threads => 1 9 #codec => json 10 #type => "json-nginxaccess" 11 } 12 } 13 14 15 filter { 16 json { 17 source => "message" 18 remove_field => ["beat"] 19 #remove_field => ["beat","message"] 20 } 21 22 geoip { 23 source => "clientip" 24 } 25 26 geoip { 27 source => "clientip" 28 target => "geoip" 29 #database => "/root/GeoLite2-City_20170704/GeoLite2-City.mmdb" 30 add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ] 31 add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ] 32 } 33 34 grok { 35 match => ["message","%{TIMESTAMP_ISO8601:isotime}"] 36 } 37 date { 38 locale => "en" 39 match => ["isotime","ISO8601"] 40 #match => ["isotime","dd/MMM/yyyy:HH:mm:ss Z"] 41 target => "@timestamp" 42 } 43 44 mutate { 45 convert => [ "[geoip][coordinates]", "float"] 46 remove_field => ["message"] 47 #remove_field => ["@timestamp"] 48 } 49 } 50 51 output { 52 if "json_nginxaccess" in [tags] { 53 elasticsearch { 54 #hosts => ["127.0.0.1:9200"] 55 hosts => ["192.168.32.230:9200","192.168.32.231:9200","192.168.32.232:9200"] 56 #index => "logstash-%{type}-%{+YYYY.MM.dd}" 57 index => "logstash-json-nginxaccess-%{+YYYY.MM.dd}" 58 document_type => "%{[@metadata][type]}" 59 #flush_size => 2000 60 #idle_flush_time => 10 61 sniffing => true 62 template_overwrite => true 63 } 64 } 65 66 if "json_nginxerror" in [tags] { 67 elasticsearch { 68 #hosts => ["127.0.0.1:9200"] 69 hosts => ["192.168.32.230:9200","192.168.32.231:9200","192.168.32.232:9200"] 70 #index => "logstash-%{type}-%{+YYYY.MM.dd}" 71 index => "logstash-json-nginxerror-%{+YYYY.MM.dd}" 72 document_type => "%{type}" 73 #flush_size => 2000 74 #idle_flush_time => 10 75 sniffing => true 76 template_overwrite => true 77 } 78 } 79 stdout { 80 codec => "rubydebug" 81 } 82 }
/usr/local/ELK/logstash-6.3.0/bin/logstash -f /usr/local/ELK/logstash-6.3.0/conf/filebeat_redis.conf -t 测试配置文件启动是否正常
nohup /usr/local/ELK/logstash-6.3.0/bin/logstash -f /usr/local/ELK/logstash-6.3.0/conf/filebeat_redis.conf 2>&1 & 启动logstash
启动之后,查看elasticsearch索引是否生成
curl http://192.168.32.231:9200/_cat/indices?v
4、配置kibana
server.port: 5601
server.host: "192.168.32.231"
elasticsearch.url: "http://192.168.32.231:9200"
通过浏览器访问 192.168.32.231:5601
添加索引
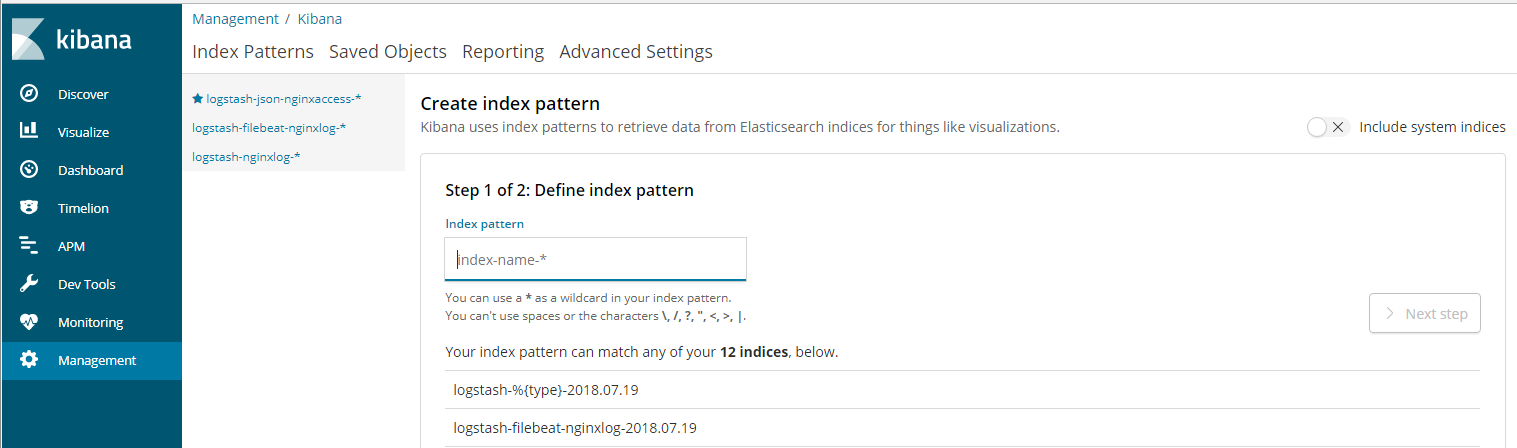
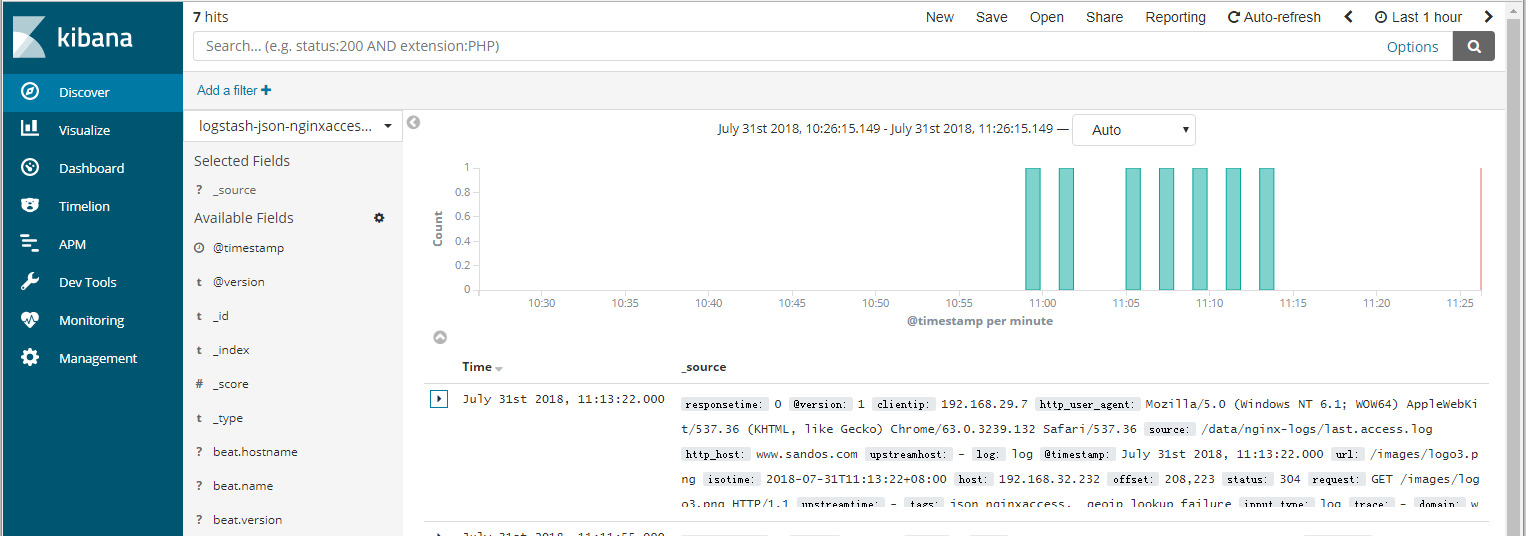
查看索引
5、nginx反向代理配置
因为免费的 ELK 没有任何安全机制,所以这里使用了 Nginx 作反向代理,避免用户直接访问 Kibana 服务器。加上配置 Nginx 实现简单的用户认证,一定程度上提高安全性。另外,Nginx 本身具有负载均衡的作用,能够提高系统访问性能。
1 upstream kibana_server { 2 server 127.0.0.1:5601 weight=1 max_fails=3 fail_timeout=60; 3 } 4 5 server { 6 listen 80; 7 server_name www.cc.com; 8 auth_basic "Restricted Access"; # 验证 9 auth_basic_user_file /etc/nginx/htpasswd.users; # 验证文件 10 location / { 11 proxy_pass http://kibana_server; 12 proxy_http_version 1.1; 13 proxy_set_header Upgrade $http_upgrade; 14 proxy_set_header Connection 'upgrade'; 15 proxy_set_header Host $host; 16 proxy_cache_bypass $http_upgrade; 17 } 18 }
