C++ STL编程轻松入门【转载】
"什么是STL?",假如你对STL还知之甚少,那么我想,你一定很想知道这个问题的答案,坦率地讲,要指望用短短数言将这个问题阐述清楚,也决非易事。因此,如果你在看完本节之后还是觉得似懂非懂,大可不必着急,在阅读了后续内容之后,相信你对STL的认识,将会愈加清晰、准确和完整。不过,上述这番话听起来是否有点像是在为自己糟糕的表达能力开脱罪责呢?:)
不知道你是否有过这样的经历。在你准备着手完成数据结构老师所布置的家庭作业时,或者在你为你所负责的某个软件项目中添加一项新功能时,你发现需要用到一个链表(List)或者是映射表(Map)之类的东西,但是手头并没有现成的代码。于是在你开始正式考虑程序功能之前,手工实现List或者Map是不可避免的。于是……,最终你顺利完成了任务。或许此时,作为一个具有较高素养的程序员的你还不肯罢休(或者是一个喜欢偷懒的优等生:),因为你会想到,如果以后还遇到这样的情况怎么办?没有必要再做一遍同样的事情吧!
如果说上述这种情形每天都在发生,或许有点夸张。但是,如果说整个软件领域里,数十年来确实都在为了一个目标而奋斗--可复用性(reusability),这看起来似乎并不夸张。从最早的面向过程的函数库,到面向对象的程序设计思想,到各种组件技术(如:COM、EJB),到设计模式(design pattern)等等。而STL也在做着类似的事情,同时在它背后蕴涵着一种新的程序设计思想--泛型化设计(generic programming)。
继续上面提到的那个例子,假如你把List或者map完好的保留了下来,正在暗自得意。且慢,如果下一回的List里放的不是浮点数而是整数呢?如果你所实现的Map在效率上总是令你不太满意并且有时还会出些bug呢?你该如何面对这些问题?使用STL是一个不错的选择,确实如此,STL可以漂亮地解决上面提到的这些问题,尽管你还可以寻求其他方法。
说了半天,到底STL是什么东西呢?
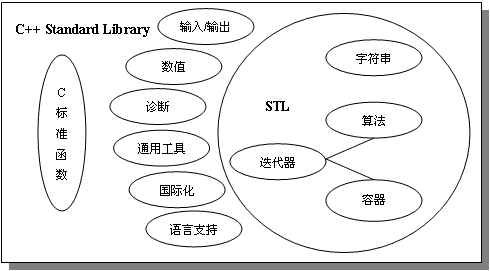
STL(Standard Template Library),即标准模板库,是一个具有工业强度的,高效的C++程序库。它被容纳于C++标准程序库(C++ Standard Library)中,是ANSI/ISO C++标准中最新的也是极具革命性的一部分。该库包含了诸多在计算机科学领域里所常用的基本数据结构和基本算法。为广大C++程序员们提供了一个可扩展的应用框架,高度体现了软件的可复用性。这种现象有些类似于Microsoft Visual C++中的MFC(Microsoft Foundation Class Library),或者是Borland C++ Builder中的VCL(Visual Component Library),对于此二者,大家一定不会陌生吧。
从逻辑层次来看,在STL中体现了泛型化程序设计的思想(generic programming),引入了诸多新的名词,比如像需求(requirements),概念(concept),模型(model),容器(container),算法(algorithmn),迭代子(iterator)等。与OOP(object-oriented programming)中的多态(polymorphism)一样,泛型也是一种软件的复用技术。
从实现层次看,整个STL是以一种类型参数化(type parameterized)的方式实现的,这种方式基于一个在早先C++标准中没有出现的语言特性--模板(template)。如果查阅任何一个版本的STL源代码,你就会发现,模板作为构成整个STL的基石是一件千真万确的事情。除此之外,还有许多C++的新特性为STL的实现提供了方便。
2 牛刀小试:且看一个简单例程
2.1 引子
如果你是一个纯粹的实用主义者,也许一开始就可以从这里开始看起,因为此处提供了一个示例程序,它可以带给你有关使用STL的最直接的感受。是的,与其纸上谈兵,不如单刀直入,实际操作一番。但是,需要提醒的是,假如你在兴致昂然地细细品味本章内容的时候,能够同时结合前面章节作为佐餐,那将是再好不过的。你会发现,前面所提到的有关STL的那些优点,在此处得到了确切的应证。本章的后半部分,将为你演示在一些主流C++编译器上,运行上述示例程序的具体操作方法,和需要注意的事项。
2.2 例程实作
非常遗憾,我不得不舍弃"Hello World"这个经典的范例,尽管它不只一次的被各种介绍计算机语言的教科书所引用,几乎成为了一个默认的“标准”。其原因在于它太过简单了,以至于不具备代表性,无法展现STL的巨大魅力。我选用了一个稍稍复杂一点的例子,它的大致功能是:从标准输入设备(一般是键盘)读入一些整型数据,然后对它们进行排序,最终将结果输出到标准输出设备(一般是显示器屏幕)。这是一种典型的处理方式,程序本身具备了一个系统所应该具有的几乎所有的基本特征:输入 + 处理 + 输出。你将会看到三个不同版本的程序。第一个是没有使用STL的普通C++程序,你将会看到完成这样看似简单的事情,需要花多大的力气,而且还未必没有一点问题(真是吃力不讨好)。第二个程序的主体部分使用了STL特性,此时在第一个程序中所遇到的问题就基本可以解决了。同时,你会发现采用了STL之后,程序变得简洁明快,清晰易读。第三个程序则将STL的功能发挥到了及至,你可以看到程序里几乎每一行代码都是和STL相关的。这样的机会并不总是随处可见的,它展现了STL中的几乎所有的基本组成部分,尽管这看起来似乎有点过分了。
有几点是需要说明的:
这个例程的目的,在于向你演示如何在C++程序中使用STL,同时希望通过实践,证明STL所带给你的确确实实的好处。程序中用到的一些STL基本组件,比如:vector(一种容器)、sort(一种排序算法),你只需要有一个大致的概念就可以了,这并不影响阅读代码和理解程序的含义。
很多人对GUI(图形用户界面)的运行方式很感兴趣,这也难怪,漂亮的界面总是会令人赏心悦目的。但是很可惜,在这里没有加入这些功能。这很容易解释,对于所提供的这个简单示例程序而言,加入GUI特性,是有点本末倒置的。这将会使程序的代码量骤然间急剧膨胀,而真正可以说明问题的核心部分确被淹没在诸多无关紧要的代码中间(你需要花去极大的精力来处理键盘或者鼠标的消息响应这些繁琐而又较为规范的事情)。即使你有像Borland C++ Builder这样的基于IDE(集成化开发环境)的工具,界面的处理变得较为简单了(框架代码是自动生成的)。请注意,我们这里所谈及的是属于C++标准的一部分(STL的第一个字母说明了这一点),它不涉及具体的某个开发工具,它是几乎在任何C++编译器上都能编译通过的代码。毕竟,在Microsoft Visual C++和Borland C++ Builder里,有关GUI的处理代码是不一样的。如果你想了解这些GUI的细节,这里恐怕没有你希望得到的答案,你可以寻找其它相关书籍。
2.2.1 第一版:史前时代--转木取火
在STL还没有降生的"黑暗时代",C++程序员要完成前面所提到的那些功能,需要做很多事情(不过这比起C程序来,似乎好一点),程序大致是如下这个样子的:
// name:example2_1.cpp
// alias:Rubish
#include <stdlib.h>
#include <iostream.h>
int compare(const void *arg1, const void *arg2);
void main(void)
{
const int max_size = 10; // 数组允许元素的最大个数
int num[max_size]; // 整型数组
// 从标准输入设备读入整数,同时累计输入个数,
// 直到输入的是非整型数据为止
int n;
for (n = 0; cin >> num[n]; n ++);
// C标准库中的快速排序(quick-sort)函数
qsort(num, n, sizeof(int), compare);
// 将排序结果输出到标准输出设备
for (int i = 0; i < n; i ++)
cout << num[i] << "\n";
}
// 比较两个数的大小,
// 如果*(int *)arg1比*(int *)arg2小,则返回-1
// 如果*(int *)arg1比*(int *)arg2大,则返回1
// 如果*(int *)arg1等于*(int *)arg2,则返回0
int compare(const void *arg1, const void *arg2)
{
return (*(int *)arg1 < *(int *)arg2) ? -1 :
(*(int *)arg1 > *(int *)arg2) ? 1 : 0;
}
这是一个和STL没有丝毫关系的传统风格的C++程序。因为程序的注释已经很详尽了,所以不需要我再做更多的解释。总的说来,这个程序看起来并不十分复杂(本来就没有太多功能)。只是,那个compare函数,看起来有点费劲。指向它的函数指针被作为最后一个实参传入qsort函数,qsort是C程序库stdlib.h中的一个函数。以下是qsort的函数原型:
void qsort(void *base, size_t num, size_t width, int (__cdecl *compare )(const void *elem1, const void *elem2 ) );
看起来有点令人作呕,尤其是最后一个参数。大概的意思是,第一个参数指明了要排序的数组(比如:程序中的num),第二个参数给出了数组的大小(qsort没有足够的智力预知你传给它的数组的实际大小),第三个参数给出了数组中每个元素以字节为单位的大小。最后那个长长的家伙,给出了排序时比较元素的方式(还是因为qsort的智商问题)。
以下是某次运行的结果:
输入:0 9 2 1 5
输出:0 1 2 5 9
有一个问题,这个程序并不像看起来那么健壮(Robust)。如果我们输入的数字个数超过max_size所规定的上限,就会出现数组越界问题。如果你在Visual C++的IDE环境下以控制台方式运行这个程序时,会弹出非法内存访问的错误对话框。
这个问题很严重,严重到足以使你开始重新审视这个程序的代码。为了弥补程序中的这一缺陷。我们不得不考虑采用如下三种方案中的一种:
采用大容量的静态数组分配。
限定输入的数据个数。
采用动态内存分配。
第一种方案比较简单,你所做的只是将max_size改大一点,比如:1000或者10000。但是,严格讲这并不能最终解决问题,隐患仍然存在。假如有人足够耐心,还是可以使你的这个经过纠正后的程序崩溃的。此外,分配一个大数组,通常是在浪费空间,因为大多数情况下,数组中的一部分空间并没有被利用。
再来看看第二种方案,通过在第一个for循环中加入一个限定条件,可以使问题得到解决。比如:for (int n = 0; cin >> num[n] && n < max_size; n ++); 但是这个方案同样不甚理想,尽管不会使程序崩溃,但失去了灵活性,你无法输入更多的数。
看来只有选择第三种方案了。是的,你可以利用指针,以及动态内存分配妥善的解决上述问题,并且使程序具有良好的灵活性。这需要用到new,delete操作符,或者古老的malloc(),realloc()和free()函数。但是为此,你将牺牲程序的简洁性,使程序代码陡增,代码的处理逻辑也不再像原先看起来那么清晰了。一个compare函数或许就已经令你不耐烦了,更何况要实现这些复杂的处理机制呢?很难保证你不会在处理这个问题的时候出错,很多程序的bug往往就是这样产生的。同时,你还应该感谢stdlib.h,它为你提供了qsort函数,否则,你还需要自己实现排序算法。如果你用的是冒泡法排序,那效率就不会很理想。……,问题真是越来越让人头疼了!
关于第一个程序的讨论就到此为止,如果你对第三种方案感兴趣的话,可以尝试着自己编写一个程序,作为思考题。这里就不准备再浪费笔墨去实现这样一个让人不甚愉快的程序了。
我们应该庆幸自己所生活的年代。工业时代,科技的发展所带来的巨大便利已经影响到了我们生活中的每个细节。如果你还在以原始人类的方式生活着,那我真该怀疑你是否属于某个生活在非洲或者南美丛林里的原始部落中的一员了,难道是玛雅文明又重现了?
STL便是这个时代的产物,正如其他科技成果一样,C++程序员也应该努力使自己适应并充分利用这个"高科技成果"。让我们重新审视第一版的那个破烂不堪的程序。试着使用一下STL,看看效果如何。
// name:example2_2.cpp
// alias:The first STL program
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void main(void)
{
vector<int> num; // STL中的vector容器
int element;
// 从标准输入设备读入整数,
// 直到输入的是非整型数据为止
while (cin >> element)
num.push_back(element);
// STL中的排序算法
sort(num.begin(), num.end());
// 将排序结果输出到标准输出设备
for (int i = 0; i < num.size(); i ++)
cout << num[i] << "\n";
}
这个程序的主要部分改用了STL的部件,看起来要比第一个程序简洁一点,你已经找不到那个讨厌的compare函数了。它真的能很好的运行吗?你可以试试,因为程序的运行结果和前面的大致差不多,所以在此略去。我可以向你保证,这个程序是足够健壮的。不过,可能你还没有完全看明白程序的代码,所以我需要为你解释一下。毕竟,这个戏法变得太快了,较之第一个程序,一眨眼的功夫,那些老的C++程序员所熟悉的代码都不见了,取而代之的是一些新鲜玩意儿。
程序的前三行是包含的头文件,它们提供了程序所要用到的所有C++特性(包括输入输出处理,STL中的容器和算法)。不必在意那个.h,并不是我的疏忽,程序保证可以编译通过,只要你的C++编译器支持标准C++规范的相关部分。你只需要把它们看作是一些普通的C++头文件就可以了。事实上,也正是如此,如果你对这个变化细节感兴趣的化,可以留意一下你身旁的佐餐。
同样可以忽略第四行的存在。加入那个声明只是为了表明程序引用到了std这个标准名字空间(namespace),因为STL中的那些玩意儿全都包含在那里面。只有通过这行声明,编译器才能允许你使用那些有趣的特性。
程序中用到了vector,它是STL中的一个标准容器,可以用来存放一些元素。你可以把vector理解为int [?],一个整型的数组。之所以大小未知是因为,vector是一个可以动态调整大小的容器,当容器已满时,如果再放入元素则vector会悄悄扩大自己的容量。push_back是vector容器的一个类属成员函数,用来在容器尾端插入一个元素。main函数中第一个while循环做的事情就是不断向vector容器尾端插入整型数据,同时自动维护容器空间的大小。
sort是STL中的标准算法,用来对容器中的元素进行排序。它需要两个参数用来决定容器中哪个范围内的元素可以用来排序。这里用到了vector的另两个类属成员函数。begin()用以指向vector的首端,而end()则指向vector的末端。这里有两个问题,begin()和end()的返回值是什么?这涉及到STL的另一个重要部件--迭代器(Iterator),不过这里并不需要对它做详细了解。你只需要把它当作是一个指针就可以了,一个指向整型数据的指针。相应的sort函数声明也可以看作是void sort(int* first, int* last),尽管这实际上很不精确。另一个问题是和end()函数有关,尽管前面说它的返回值指向vector的末端,但这种说法不能算正确。事实上,它的返回值所指向的是vector中最末端元素的后面一个位置,即所谓pass-the-end value。这听起来有点费解,不过不必在意,这里只是稍带一提。总的来说,sort函数所做的事情是对那个准整型数组中的元素进行排序,一如第一个程序中的那个qsort,不过比起qsort来,sort似乎要简单了许多。
程序的最后是输出部分,在这里vector完全可以以假乱真了,它所提供的对元素的访问方式简直和普通的C++内建数组一模一样。那个size函数用来返回vector中的元素个数,就相当于第一个程序中的变量n。这两行代码直观的不用我再多解释了。
我想我的耐心讲解应该可以使你大致看懂上面的程序了,事实上STL的运用使程序的逻辑更加清晰,使代码更易于阅读。试问,有谁会不明白begin、end、size这样的字眼所表达的含义呢(除非他不懂英语)?试着运行一下,看看效果。再试着多输入几个数,看看是否会发生数组越界现象。实践证明,程序运行良好。是的,由于vector容器自行维护了自身的大小,C++程序员就不用操心动态内存分配了,指针的错误使用毕竟会带来很多麻烦,同时程序也会变得冗长无比。这正是前面第三种方案的缺点所在。
再仔细审视一下你的第一个STL版的C++程序,回顾一下第一章所提到的那些有关STL的优点:易于使用,具有工业强度……,再比较一下第一版的程序,我想你应该有所体会了吧!
事态的发展有时候总会趋向极端,这在那些唯美主义者当中犹是如此。首先声明,我并不是一个唯美主义者,提供第二版程序的改进版,完全是为了让你更深刻的感受到STL的魅力所在。在看完第三版之后,你会强烈感受到这一点。或许你也会变成一个唯美主义者了,至少在STL方面。这应该不是我的错,因为决定权在你手里。下面我们来看看这个绝版的C++程序。
// name:example2_3.cpp
// alias:aesthetic version
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
void main(void)
{
typedef vector<int> int_vector;
typedef istream_iterator<int> istream_itr;
typedef ostream_iterator<int> ostream_itr;
typedef back_insert_iterator< int_vector > back_ins_itr;
// STL中的vector容器
int_vector num;
// 从标准输入设备读入整数,
// 直到输入的是非整型数据为止
copy(istream_itr(cin), istream_itr(), back_ins_itr(num));
// STL中的排序算法
sort(num.begin(), num.end());
// 将排序结果输出到标准输出设备
copy(num.begin(), num.end(), ostream_itr(cout, "\n"));
}
在这个程序里几乎每行代码都是和STL有关的(除了main和那对花括号,当然还有注释),并且它包含了STL中几乎所有的各大部件(容器container,迭代器iterator, 算法algorithm, 适配器adaptor),唯一的遗憾是少了函数对象(functor)的身影。
还记得开头提到的一个典型系统所具有的基本特征吗?--输入+处理+输出。所有这些功能,在上面的程序里,仅仅是通过三行语句来实现的,其中每一行语句对应一种操作。对于数据的操作被高度的抽象化了,而算法和容器之间的组合,就像搭积木一样轻松自如,系统的耦合度被降到了极低点。这就是闪耀着泛型之光的STL的伟大力量。如此简洁,如此巧妙,如此神奇!就像魔术一般,以至于再一次让你摸不着头脑。怎么实现的?为什么在看第二版程序的时候如此清晰的你,又坠入了五里雾中(窃喜)。
请留意此处的标题(唯美主义的杰作),在实际环境中,你未必要做到这样完美。毕竟美好愿望的破灭,在生活中时常会发生。过于理想化,并不是一件好事,至少我是这么认为的。正如前面提到的,这个程序只是为了展示STL的独特魅力,你不得不为它的出色表现所折服,也许只有深谙STL之道的人才会想出这样的玩意儿来。如果你只是一般性的使用STL,做到第二版这样的程度也就可以了。
实在是因为这个程序太过"简单",以至于我无法肯定,在你还没有完全掌握STL之前,通过我的讲解,是否能够领会这区区三行代码,我将尽我的最大努力。
前面提到的迭代器可以对容器内的任意元素进行定位和访问。在STL里,这种特性被加以推广了。一个cin代表了来自输入设备的一段数据流,从概念上讲它对数据流的访问功能类似于一般意义上的迭代器,但是C++中的cin在很多地方操作起来并不像是一个迭代器,原因就在于其接口和迭代器的接口不一致(比如:不能对cin进行++运算,也不能对之进行取值运算--即*运算)。为了解决这个矛盾,就需要引入适配器的概念。istream_iterator便是一个适配器,它将cin进行包装,使之看起来像是一个普通的迭代器,这样我们就可以将之作为实参传给一些算法了(比如这里的copy算法)。因为算法只认得迭代器,而不会接受cin。对于上面程序中的第一个copy函数而言,其第一个参数展开后的形式是:istream_iterator(cin),其第二个参数展开后的形式是:istream_iterator()(如果你对typedef的语法不清楚,可以参考有关的c++语言书籍)。其效果是产生两个迭代器的临时对象,前一个指向整型输入数据流的开始,后一个则指向"pass-the-end value"。这个函数的作用就是将整型输入数据流从头至尾逐一"拷贝"到vector这个准整型数组里,第一个迭代器从开始位置每次累进,最后到达第二个迭代器所指向的位置。或许你要问,如果那个copy函数的行为真如我所说的那样,为什么不写成如下这个样子呢?
copy(istream_iterator<int>(cin), istream_iterator<int>(), num.begin());
你确实可以这么做,但是有一个小小的麻烦。还记得第一版程序里的那个数组越界问题吗?如果你这么写的话,就会遇到类似的麻烦。原因在于copy函数在"拷贝"数据的时候,如果输入的数据个数超过了vector容器的范围时,数据将会拷贝到容器的外面。此时,容器不会自动增长容量,因为这只是简单地拷贝,并不是从末端插入。为了解决这个问题,另一个适配器back_insert_iterator登场了,它的作用就是引导copy算法每次在容器末端插入一个数据。程序中的那个back_ins_itr(num)展开后就是:back_insert_iterator<int_vector>(num),其效果是生成一个这样的迭待器对象。
终于将讲完了三分之一(真不容易!),好在第二句和前一版程序没有差别,这里就略过了。至于第三句,ostream_itr(cout, "\n")展开后的形式是:ostream_iterator(cout, "\n"),其效果是产生一个处理输出数据流的迭待器对象,其位置指向数据流的起始处,并且以"\n"作为分割符。第二个copy函数将会从头至尾将vector中的内容"拷贝"到输出设备,第一个参数所代表的迭代器将会从开始位置每次累进,最后到达第二个参数所代表的迭代器所指向的位置。
这就是全部的内容。
历史的车轮总是滚滚向前的,工业时代的文明较之史前时代,当然是先进并且发达的。回顾那两个时代的C++程序,你会真切的感受到这种差别。简洁易用,具有工业强度,较好的可移植性,高效率,加之第三个令人目眩的绝版程序所体现出来的高度抽象性,高度灵活性和组件化特性,使你对STL背后所蕴含的泛型化思想都有了些微的感受。
真幸运,你可以横跨两个时代,有机会目睹这种"文明"的差异。同时,这也应该使你越加坚定信念,使自己顺应时代的潮流。
事态的发展有时候总会趋向极端,这在那些唯美主义者当中犹是如此。首先声明,我并不是一个唯美主义者,提供第二版程序的改进版,完全是为了让你更深刻的感受到STL的魅力所在。在看完第三版之后,你会强烈感受到这一点。或许你也会变成一个唯美主义者了,至少在STL方面。这应该不是我的错,因为决定权在你手里。下面我们来看看这个绝版的C++程序。
// name:example2_3.cpp
// alias:aesthetic version
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
void main(void)
{
typedef vector<int> int_vector;
typedef istream_iterator<int> istream_itr;
typedef ostream_iterator<int> ostream_itr;
typedef back_insert_iterator< int_vector > back_ins_itr;
// STL中的vector容器
int_vector num;
// 从标准输入设备读入整数,
// 直到输入的是非整型数据为止
copy(istream_itr(cin), istream_itr(), back_ins_itr(num));
// STL中的排序算法
sort(num.begin(), num.end());
// 将排序结果输出到标准输出设备
copy(num.begin(), num.end(), ostream_itr(cout, "\n"));
}
在这个程序里几乎每行代码都是和STL有关的(除了main和那对花括号,当然还有注释),并且它包含了STL中几乎所有的各大部件(容器container,迭代器iterator, 算法algorithm, 适配器adaptor),唯一的遗憾是少了函数对象(functor)的身影。
还记得开头提到的一个典型系统所具有的基本特征吗?--输入+处理+输出。所有这些功能,在上面的程序里,仅仅是通过三行语句来实现的,其中每一行语句对应一种操作。对于数据的操作被高度的抽象化了,而算法和容器之间的组合,就像搭积木一样轻松自如,系统的耦合度被降到了极低点。这就是闪耀着泛型之光的STL的伟大力量。如此简洁,如此巧妙,如此神奇!就像魔术一般,以至于再一次让你摸不着头脑。怎么实现的?为什么在看第二版程序的时候如此清晰的你,又坠入了五里雾中(窃喜)。
请留意此处的标题(唯美主义的杰作),在实际环境中,你未必要做到这样完美。毕竟美好愿望的破灭,在生活中时常会发生。过于理想化,并不是一件好事,至少我是这么认为的。正如前面提到的,这个程序只是为了展示STL的独特魅力,你不得不为它的出色表现所折服,也许只有深谙STL之道的人才会想出这样的玩意儿来。如果你只是一般性的使用STL,做到第二版这样的程度也就可以了。
实在是因为这个程序太过"简单",以至于我无法肯定,在你还没有完全掌握STL之前,通过我的讲解,是否能够领会这区区三行代码,我将尽我的最大努力。
前面提到的迭代器可以对容器内的任意元素进行定位和访问。在STL里,这种特性被加以推广了。一个cin代表了来自输入设备的一段数据流,从概念上讲它对数据流的访问功能类似于一般意义上的迭代器,但是C++中的cin在很多地方操作起来并不像是一个迭代器,原因就在于其接口和迭代器的接口不一致(比如:不能对cin进行++运算,也不能对之进行取值运算--即*运算)。为了解决这个矛盾,就需要引入适配器的概念。istream_iterator便是一个适配器,它将cin进行包装,使之看起来像是一个普通的迭代器,这样我们就可以将之作为实参传给一些算法了(比如这里的copy算法)。因为算法只认得迭代器,而不会接受cin。对于上面程序中的第一个copy函数而言,其第一个参数展开后的形式是:istream_iterator(cin),其第二个参数展开后的形式是:istream_iterator()(如果你对typedef的语法不清楚,可以参考有关的c++语言书籍)。其效果是产生两个迭代器的临时对象,前一个指向整型输入数据流的开始,后一个则指向"pass-the-end value"。这个函数的作用就是将整型输入数据流从头至尾逐一"拷贝"到vector这个准整型数组里,第一个迭代器从开始位置每次累进,最后到达第二个迭代器所指向的位置。或许你要问,如果那个copy函数的行为真如我所说的那样,为什么不写成如下这个样子呢?
copy(istream_iterator<int>(cin), istream_iterator<int>(), num.begin());
你确实可以这么做,但是有一个小小的麻烦。还记得第一版程序里的那个数组越界问题吗?如果你这么写的话,就会遇到类似的麻烦。原因在于copy函数在"拷贝"数据的时候,如果输入的数据个数超过了vector容器的范围时,数据将会拷贝到容器的外面。此时,容器不会自动增长容量,因为这只是简单地拷贝,并不是从末端插入。为了解决这个问题,另一个适配器back_insert_iterator登场了,它的作用就是引导copy算法每次在容器末端插入一个数据。程序中的那个back_ins_itr(num)展开后就是:back_insert_iterator<int_vector>(num),其效果是生成一个这样的迭待器对象。
终于将讲完了三分之一(真不容易!),好在第二句和前一版程序没有差别,这里就略过了。至于第三句,ostream_itr(cout, "\n")展开后的形式是:ostream_iterator(cout, "\n"),其效果是产生一个处理输出数据流的迭待器对象,其位置指向数据流的起始处,并且以"\n"作为分割符。第二个copy函数将会从头至尾将vector中的内容"拷贝"到输出设备,第一个参数所代表的迭代器将会从开始位置每次累进,最后到达第二个参数所代表的迭代器所指向的位置。
这就是全部的内容。
历史的车轮总是滚滚向前的,工业时代的文明较之史前时代,当然是先进并且发达的。回顾那两个时代的C++程序,你会真切的感受到这种差别。简洁易用,具有工业强度,较好的可移植性,高效率,加之第三个令人目眩的绝版程序所体现出来的高度抽象性,高度灵活性和组件化特性,使你对STL背后所蕴含的泛型化思想都有了些微的感受。
真幸运,你可以横跨两个时代,有机会目睹这种"文明"的差异。同时,这也应该使你越加坚定信念,使自己顺应时代的潮流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号