java雪花ID
Reference: https://zhuanlan.zhihu.com/p/374667160
为什么使用雪花ID
在以前的项目中,最常见的两种主键类型是自增Id和UUID,在比较这两种ID之前首先要搞明白一个问题,就是为什么主键有序比无序查询效率要快,因为自增Id和UUID之间最大的不同点就在于有序性。
我们都知道,当我们定义了主键时,数据库会选择表的主键作为聚集索引(B+Tree),mysql 在底层是以数据页为单位来存储数据的。
也就是说如果主键为自增 id的话,mysql 在写满一个数据页的时候,直接申请另一个新数据页接着写就可以了。如果一个数据页存满了,mysql 就会去申请一个新的数据页来存储数据。如果主键是UUID,为了确保索引有序,mysql 就需要将每次插入的数据都放到合适的位置上。这就造成了页分裂,这个大量移动数据的过程是会严重影响插入效率的。
一句话总结就是,InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的。
但是为什么很多情况又不用自增id作为主键呢?
- 容易导致主键重复。比如导入旧数据时,线上又有新的数据新增,这时就有可能在导入时发生主键重复的异常。为了避免导入数据时出现主键重复的情况,要选择在应用停业后导入旧数据,导入完成后再启动应用。显然这样会造成不必要的麻烦。而UUID作为主键就不用担心这种情况。
- 不利于数据库的扩展。当采用自增id时,分库分表也会有主键重复的问题。UUID则不用担心这种问题。
那么问题就来了,自增id会担心主键重复,UUID不能保证有序性,有没有一种ID既是有序的,又是唯一的呢?
当然有,就是雪花ID。
什么是雪花ID
snowflake是Twitter开源的分布式ID生成算法,结果是64bit的Long类型的ID,有着全局唯一和有序递增的特点。
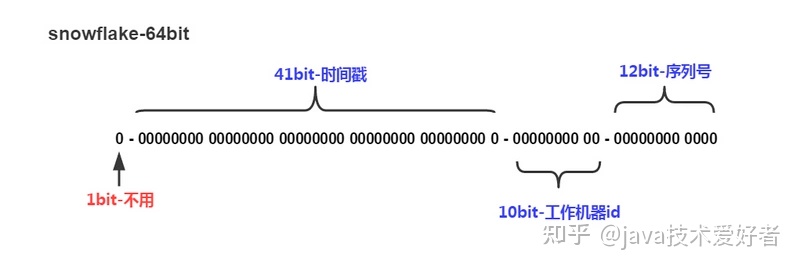
- 最高位是符号位,因为生成的 ID 总是正数,始终为0,不可用。
- 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
- 10位的机器标识,10位的长度最多支持部署1024个节点。
- 12位的计数序列号,序列号即一系列的自增ID,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
缺点也是有的,就是强依赖机器时钟,如果机器上时钟回拨,有可能会导致主键重复的问题。
1 import java.util.*; 2 3 public class SnowflakeIdWorker { 4 /** 5 * 开始时间:2020-01-01 00:00:00 6 */ 7 private final long beginTs = 1577808000000L; 8 9 private final long workerIdBits = 10; 10 11 /** 12 * 2^10 - 1 = 1023 13 */ 14 private final long maxWorkerId = -1L ^ (-1L << workerIdBits); 15 16 private final long sequenceBits = 12; 17 18 /** 19 * 2^12 - 1 = 4095 20 */ 21 private final long maxSequence = -1L ^ (-1L << sequenceBits); 22 23 /** 24 * 时间戳左移22位 25 */ 26 private final long timestampLeftOffset = workerIdBits + sequenceBits; 27 28 /** 29 * 业务ID左移12位 30 */ 31 private final long workerIdLeftOffset = sequenceBits; 32 33 /** 34 * 合并了机器ID和数据标示ID,统称业务ID,10位 35 */ 36 private long workerId; 37 38 /** 39 * 毫秒内序列,12位,2^12 = 4096个数字 40 */ 41 private long sequence = 0L; 42 43 /** 44 * 上一次生成的ID的时间戳,同一个worker中 45 */ 46 private long lastTimestamp = -1L; 47 48 public SnowflakeIdWorker(long workerId) { 49 if (workerId > maxWorkerId || workerId < 0) { 50 throw new IllegalArgumentException(String.format("WorkerId必须大于或等于0且小于或等于%d", maxWorkerId)); 51 } 52 53 this.workerId = workerId; 54 } 55 56 public synchronized long nextId() { 57 long ts = System.currentTimeMillis(); 58 if (ts < lastTimestamp) { 59 throw new RuntimeException(String.format("系统时钟回退了%d毫秒", (lastTimestamp - ts))); 60 } 61 62 // 同一时间内,则计算序列号 63 if (ts == lastTimestamp) { 64 // 序列号溢出 65 if (++sequence > maxSequence) { 66 ts = tilNextMillis(lastTimestamp); 67 sequence = 0L; 68 } 69 } else { 70 // 时间戳改变,重置序列号 71 sequence = 0L; 72 } 73 74 lastTimestamp = ts; 75 76 // 0 - 00000000 00000000 00000000 00000000 00000000 0 - 00000000 00 - 00000000 0000 77 // 左移后,低位补0,进行按位或运算相当于二进制拼接 78 // 本来高位还有个0<<63,0与任何数字按位或都是本身,所以写不写效果一样 79 return (ts - beginTs) << timestampLeftOffset | workerId << workerIdLeftOffset | sequence; 80 } 81 82 /** 83 * 阻塞到下一个毫秒 84 * 85 * @param lastTimestamp 86 * @return 87 */ 88 private long tilNextMillis(long lastTimestamp) { 89 long ts = System.currentTimeMillis(); 90 while (ts <= lastTimestamp) { 91 ts = System.currentTimeMillis(); 92 } 93 94 return ts; 95 } 96 97 public static void main(String[] args) { 98 SnowflakeIdWorker snowflakeIdWorker = new SnowflakeIdWorker(7); 99 for (int i = 0; i < 10; i++) { 100 long id = snowflakeIdWorker.nextId(); 101 System.out.println(id); 102 } 103 104 105 } 106 }
main方法,测试结果如下:
184309536616640512
184309536616640513
184309536616640514
184309536616640515
184309536616640516
184309536616640517
184309536616640518
184309536616640519
184309536616640520
184309536616640521总结
在大部分公司的开发项目中里,雪花ID是主流的ID生成策略,除了自己实现之外,目前市场上也有很多开源的实现,比如:
- 美团开源的Leaf
- 百度开源的UidGenerator
有兴趣的可以自行观摩一下,那么这篇文章就写到这里了,感谢大家的阅读。
觉得有用就点个赞吧,你的点赞是我创作的最大动力~
我是一个努力让大家记住的程序员。我们下期再见!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号