[Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
本课主题
- CacheManager 运行原理图
- CacheManager 源码解析
CacheManager 运行原理图
[下图是CacheManager的运行原理图]
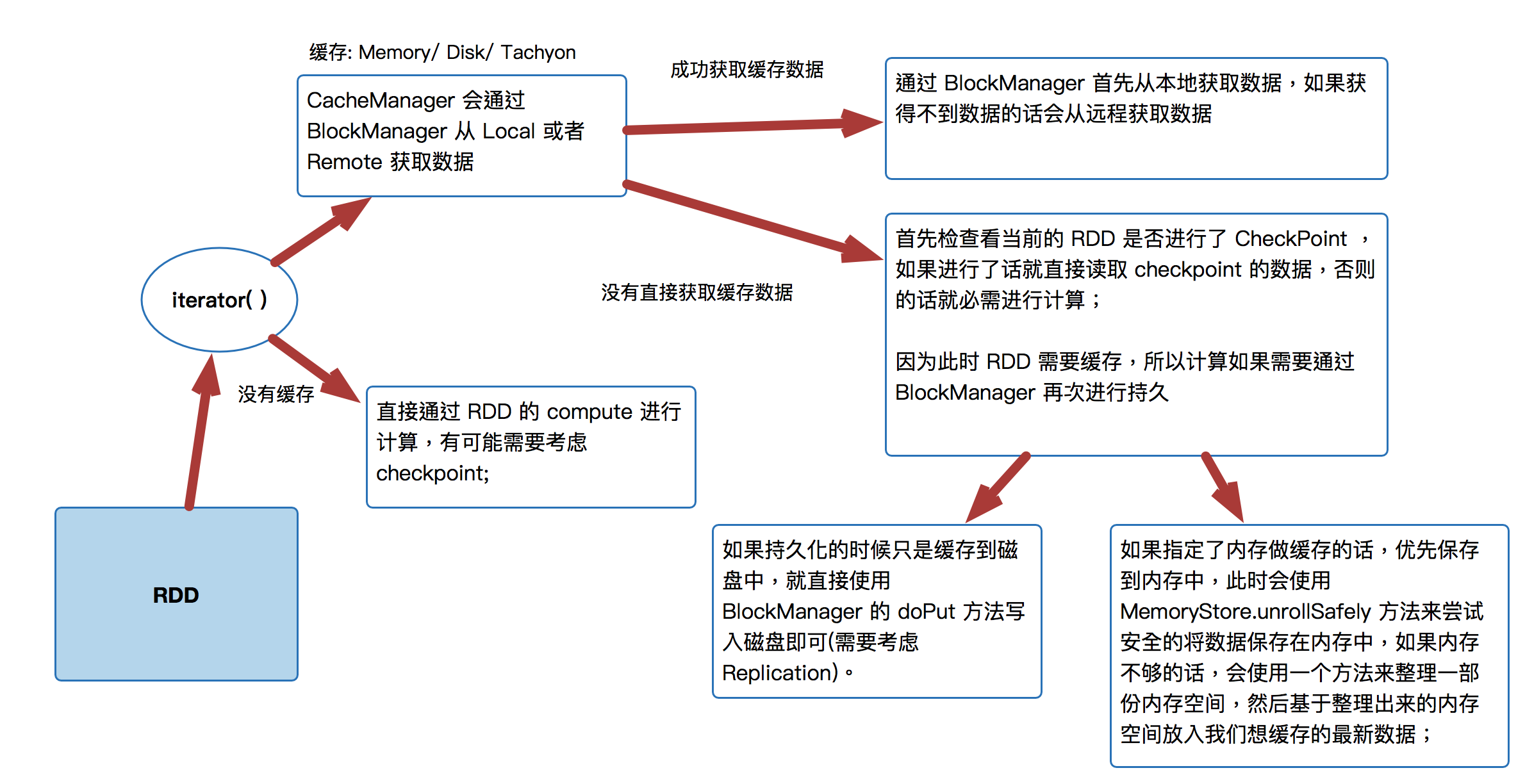
首先 RDD 是通过 iterator 来进行计算:
- CacheManager 会通过 BlockManager 从 Local 或者 Remote 获取数据直接通过 RDD 的 compute 进行计算,有可能需要考虑 checkpoint;
- 通过 BlockManager 首先从本地获取数据,如果获得不到数据的话会从远程获取数据
- 首先检查看当前的 RDD 是否进行了 CheckPoint ,如果进行了话就直接读取 checkpoint 的数据,否则的话就必需进行计算;因为此时 RDD 需要缓存,所以计算如果需要通过 BlockManager 再次进行持久
- 如果持久化的时候只是缓存到磁盘中,就直接使用 BlockManager 的 doPut 方法写入磁盘即可(需要考虑 Replication)。
- 如果指定了内存做缓存的话,优先保存到内存中,此时会使用MemoryStore.unrollSafely 方法来尝试安全的将数据保存在内存中,如果内存不够的话,会使用一个方法来整理一部份内存空间,然后基于整理出来的内存空间放入我们想缓存的最新数据;
- 直接通过 RDD 的 compute 进行计算,有可能需要考虑 checkpoint;
CacheManager 源码解析
- CacheManager 管理的是缓存中的数据,缓存可以是基于内存的缓存,也可以是基于磁盘的缓存;
- CacheManager 需要通过 BlockManager 来操作数据;
- 每当 Task 运行的时候会调用 RDD 的 Compute 方法进行计算,而 Compute 方法会调用 iterator 方法;
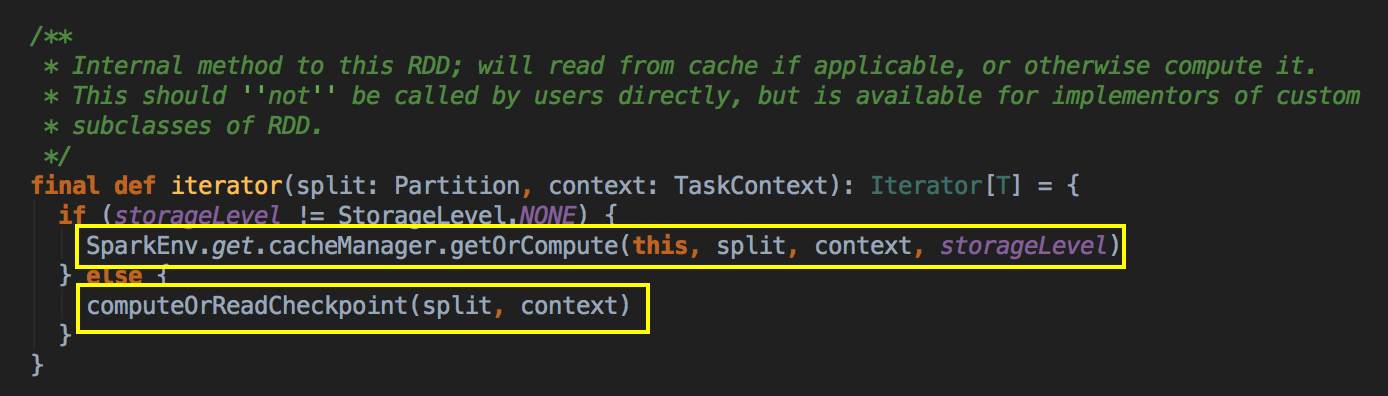
[下图是 MapPartitionRDD.scala 的 compute 方法]![]()
这个方法是 final 级别不能覆写但可以被子类去使用,可以看见 RDD 是优先使用内存的,这个方法很关键!!如果存储级别不等于 NONE 的情况下,程序会先找 CacheManager 获得数据,否则的话会看有没有进行 Checkpoint
[下图是 RDD.scala 的 iterator 方法]![]()
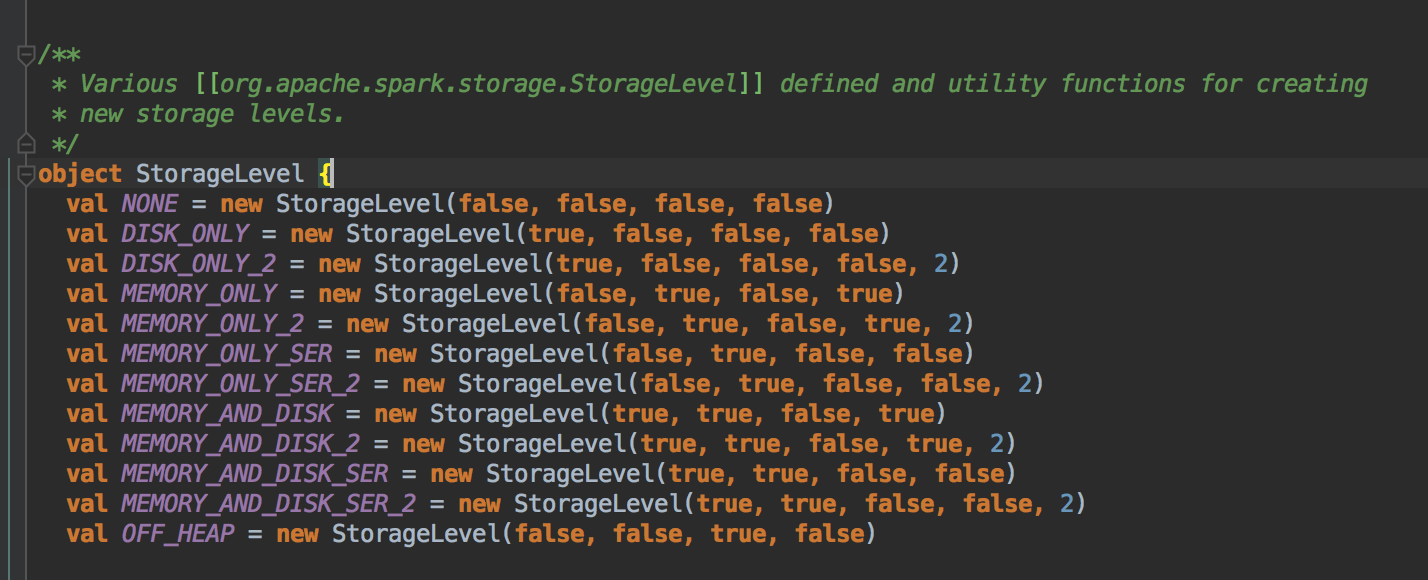
以下是 Spark 中的 StorageLevel
[下图是 StorageLevel.scala 的 StorageLevel 对象]![]()
- Cache 在工作的时候会最大化的保留数据,但是数据不一定绝对完整,因为当前的计算如果需要内存空间的话,那么内存中的数据必需让出空间,这是因为执行比缓存重要!此时如何在RDD 持久化的时候同时指定了可以把数据放左Disk 上,那么部份 Cache 的数据可以从内存转入磁盘,否则的话,数据就会丢失!
假设现在 Cache 了一百万个数据分片,但是我下一个步骤计算的时候,我需要内存,思考题:你觉得是我现在需要的内存重要呢,还是你曾经 Cache 占用的空间重要呢?亳无疑问,肯定是现在计算重要。所以 Cache 占用的空间需要从内存中除掉,如果你程序的 StorageLevel 是 MEMEORY_AND_DISK 的话,这时候在内存可能是 Drop 到磁盘上,如果你程序的 StorageLevel 是 MEMEORY_ONLY 的话,那就会出去数据丢失的情况。
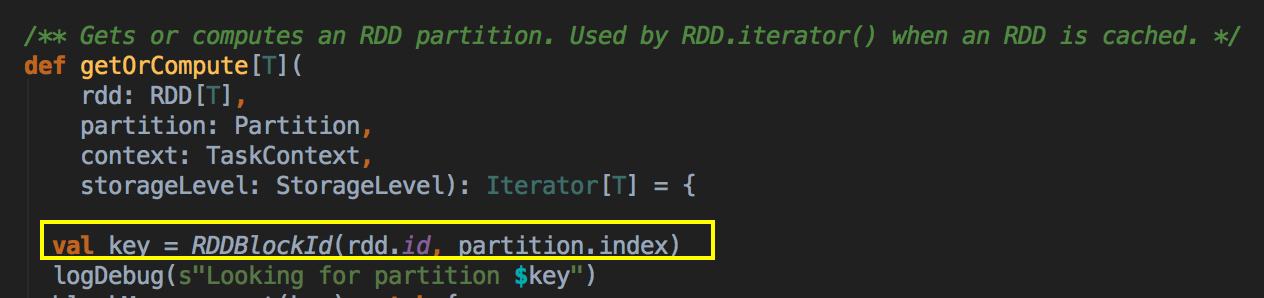
你进行Cache时,BlockManager 会帮你进行管理,我们可以通过 Key 到 BlockManager 中找出曾经缓存的数据。
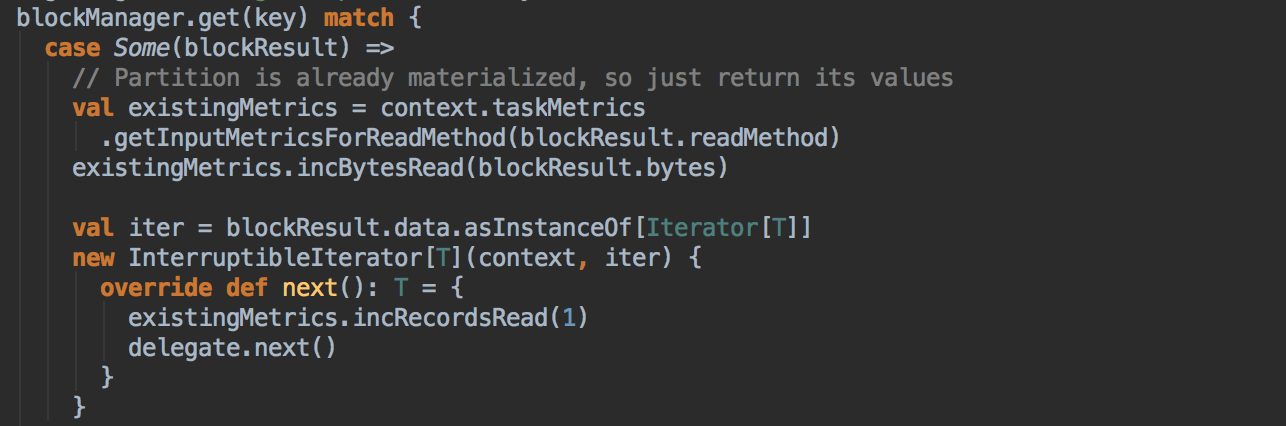
[下图是 CacheManager.scala 的 getOrCompute 方法]![]()
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]![]()
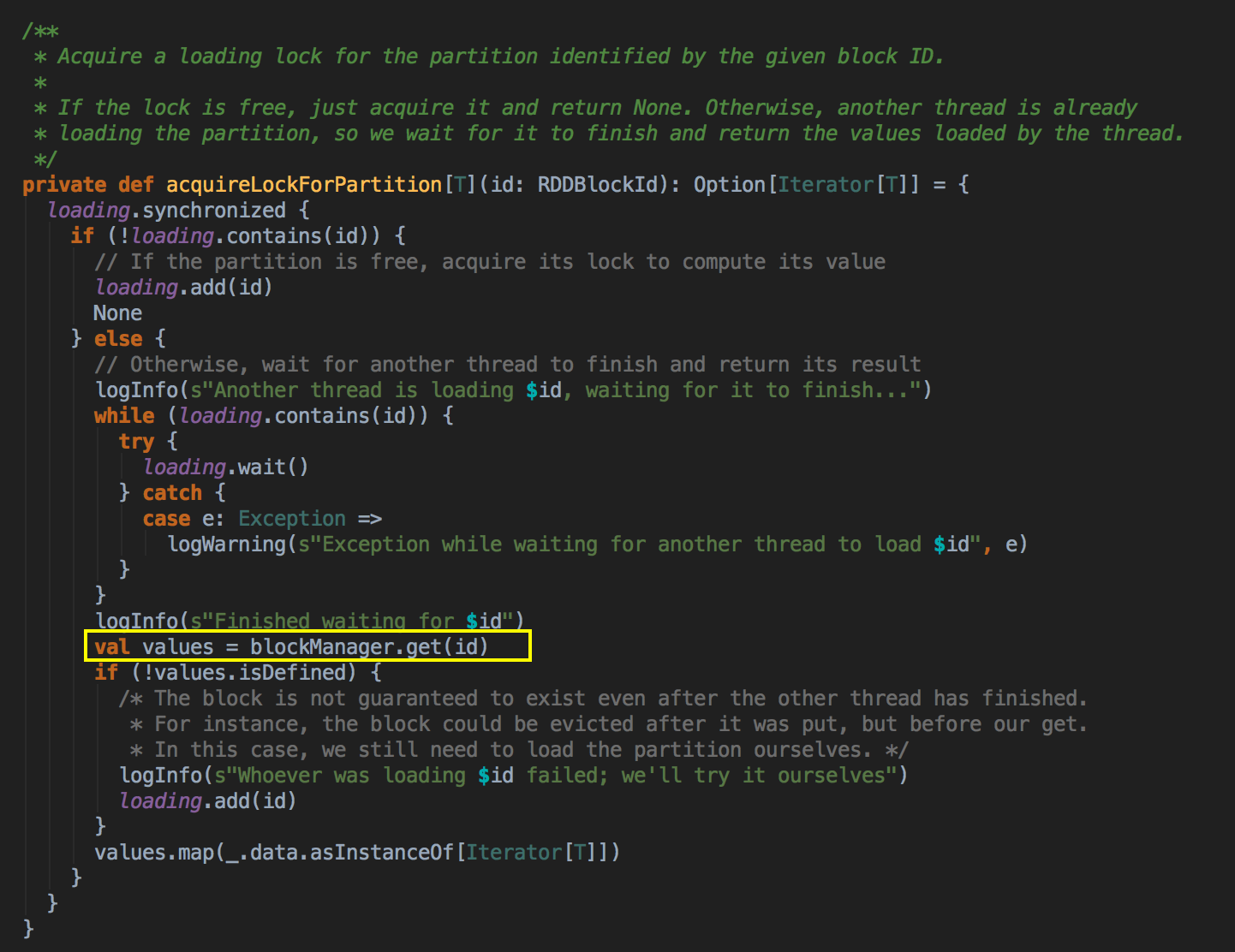
如果有 BlockManager.get() 方法没有返回任何数据,就调用 acquireLockForPartition 方法,因为会有可能多条线程在操作数据,Spark 有一个东西叫慢任务StraggleTask 推迟,StraggleTask 推迟的时候一般都会运行两个任务在两台机器上,你可能在你当前机器上没有发现这个内容,同时有远程也没有发现这个内容,只不过在你返回的那一刻,别人已经算完啦!
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]![]()
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]![]()
最后还是通过 BlockManager.get 来获得数据
[下图是 CacheManager.scala 的 acquireLockForPartition 方法]![]()
- 具体 CacheManager 在获得缓存数据的时候会通过 BlockManager 来抓到数据,优先在本地找数据或者的话就远程抓取数据。
[下图是 BlockManager.scala 的 get 方法]![]()
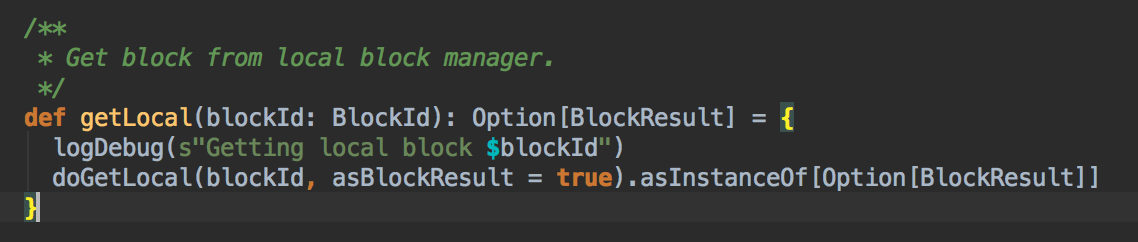
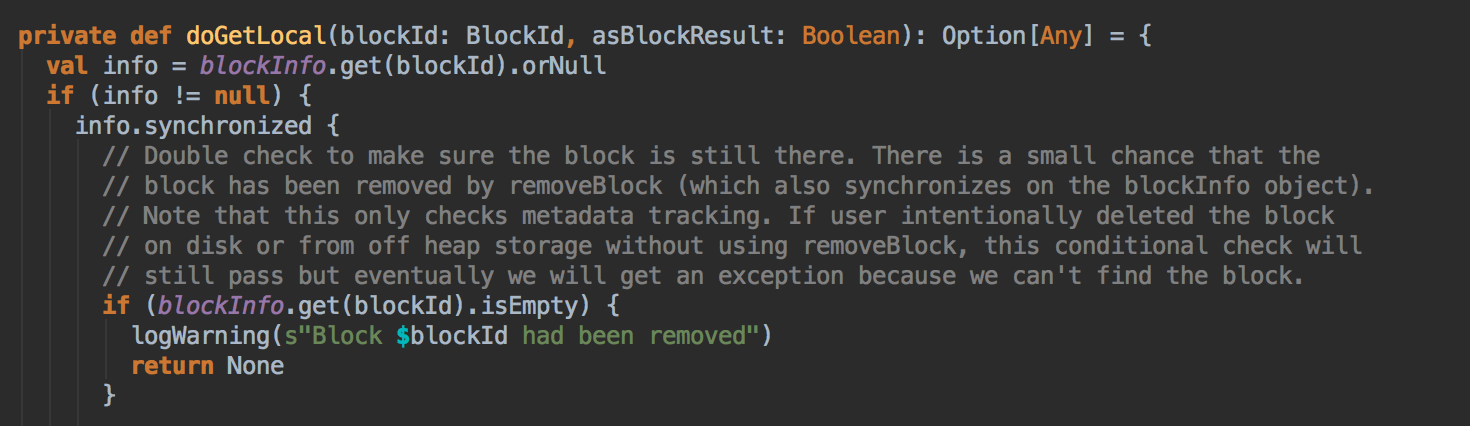
BlockManger.getLocal 然后转过来调用 doGetLocal 方法,在 doGetLocal 的实现中看到缓存其实不竟竟在内存中,可以在内存、磁盘、也可以在 OffHeap (Tachyon) 中
[下图是 BlockManager.scala 的 getLocal 方法]![]()
- 在第5步调用了 getLocal 方法后转过调用了 doGetLocal
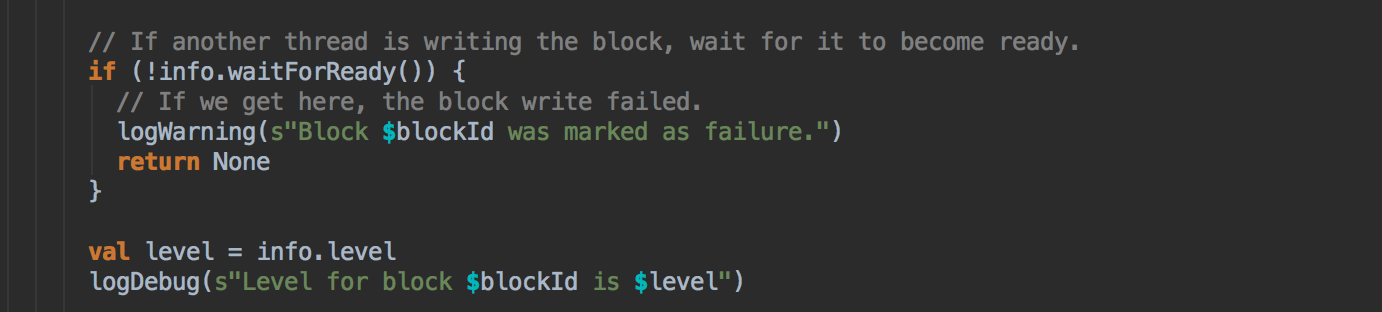
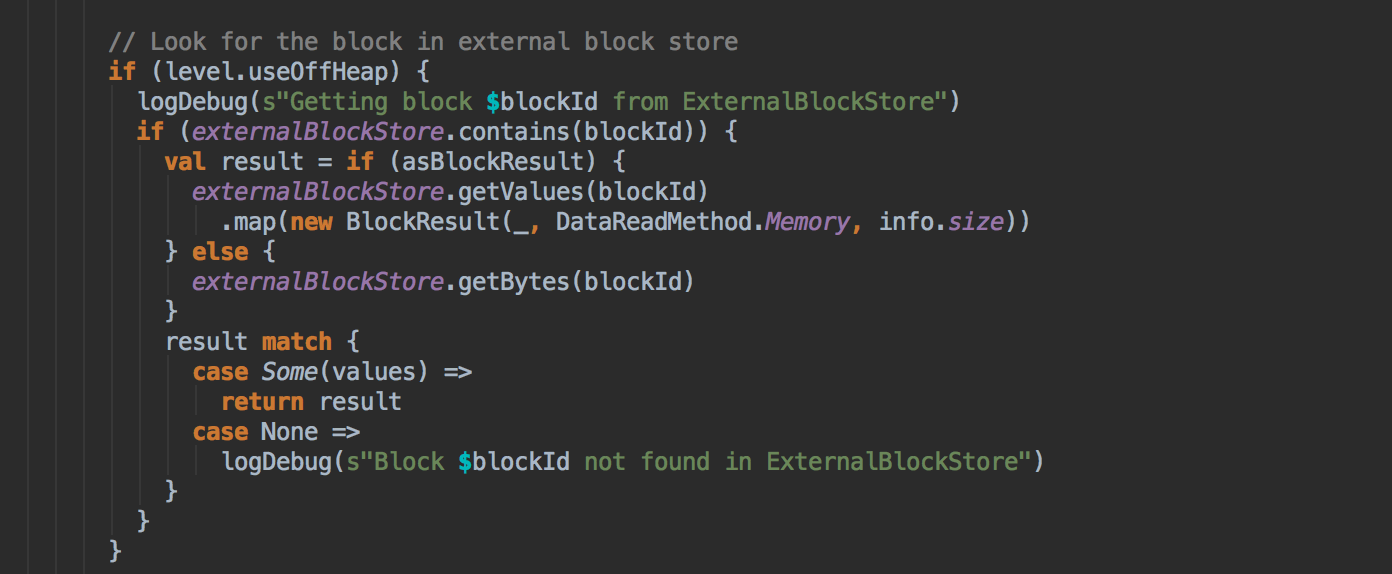
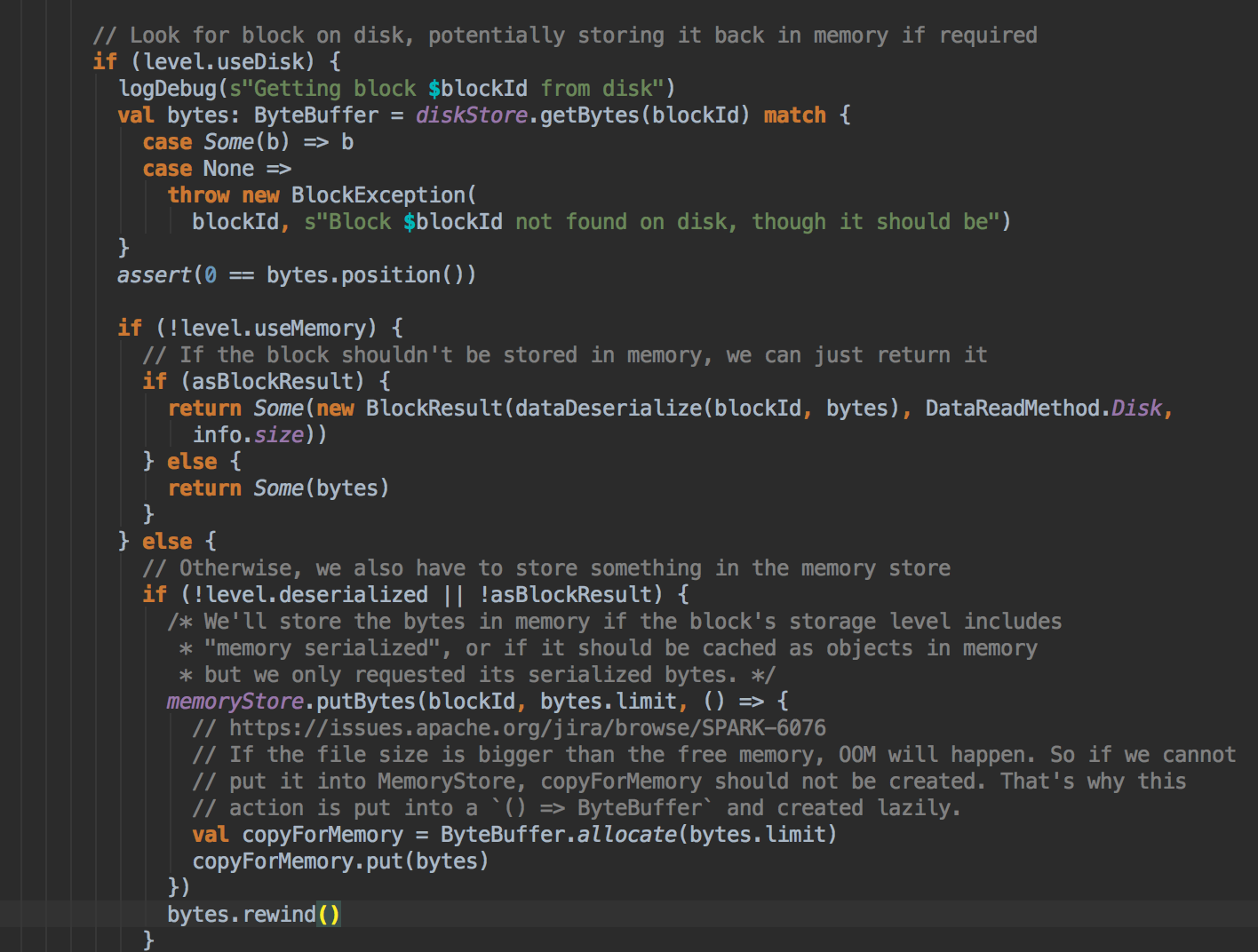
[下图是 BlockManager.scala 的 doGetLocal 方法]![]()
![]()
![]()
![]()
![]()
![]()
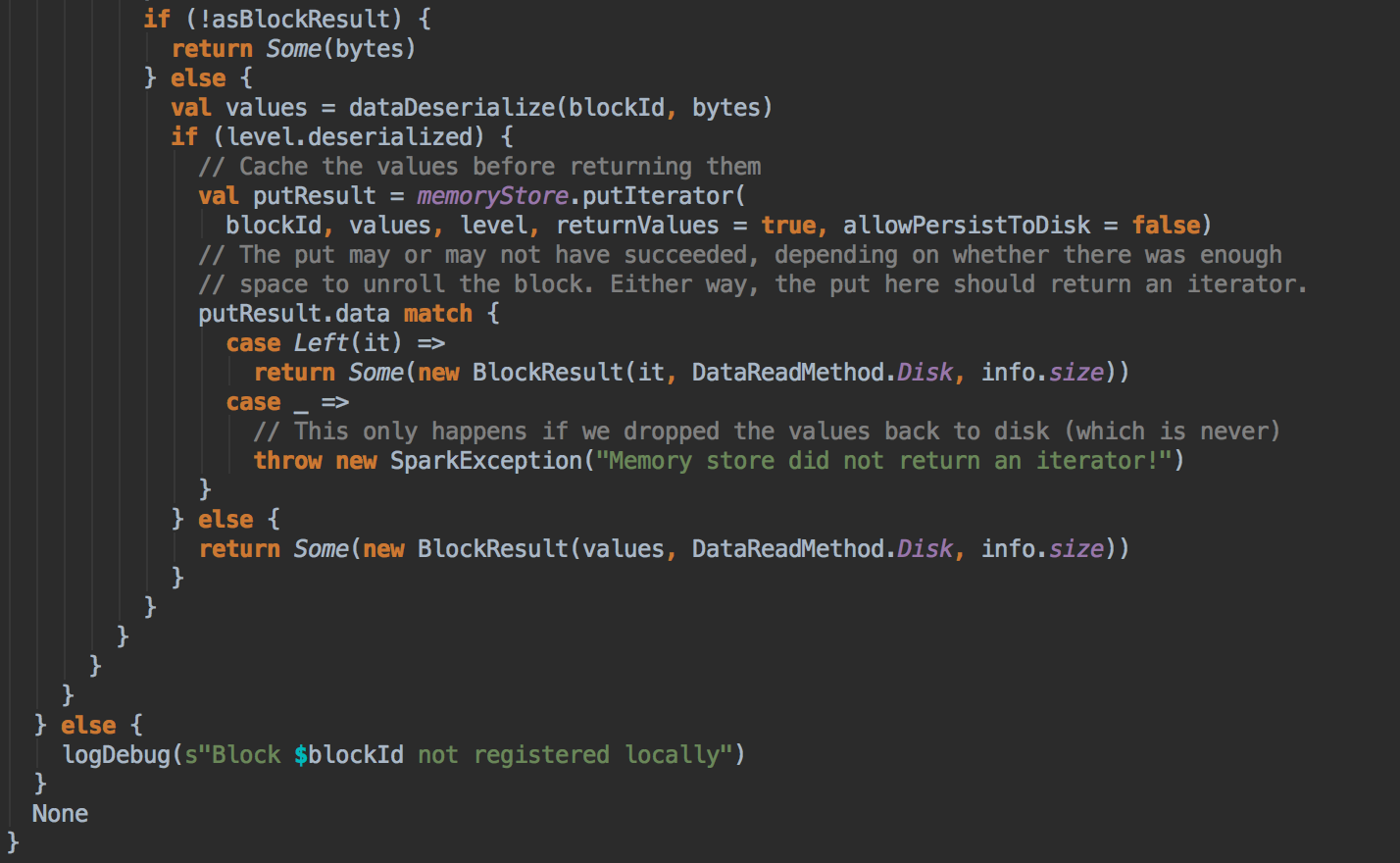
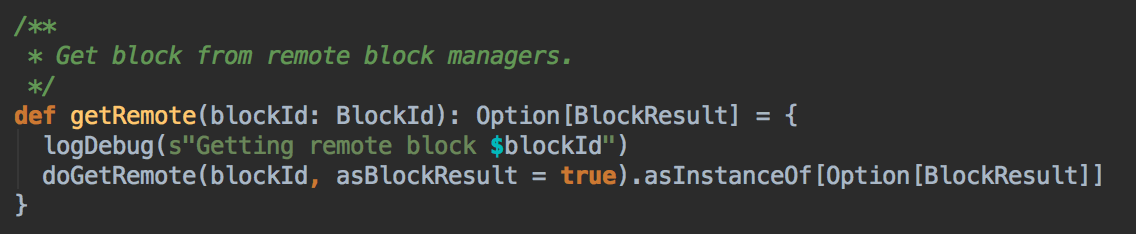
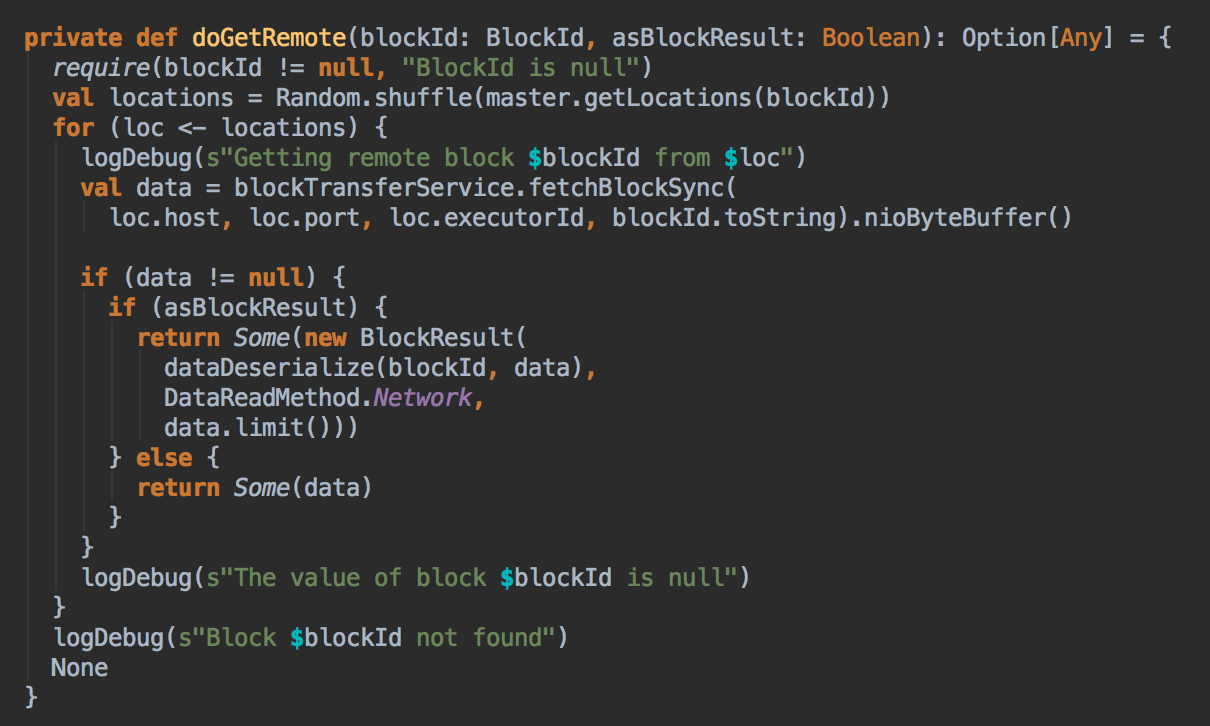
- 在第5步中如果本地没有缓存的话就调用 getRemote 方法从远程抓取数据
[下图是 BlockManager.scala 的 getRemote 方法]![]()
![]()
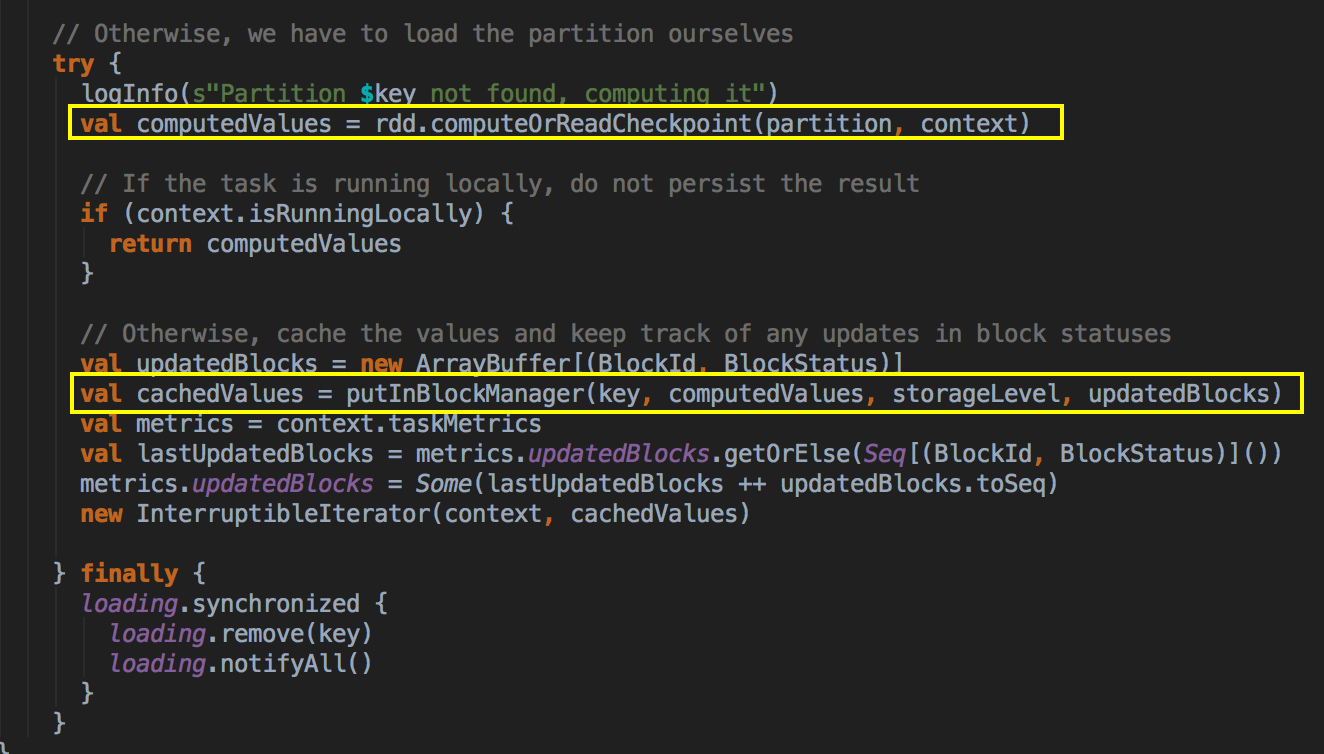
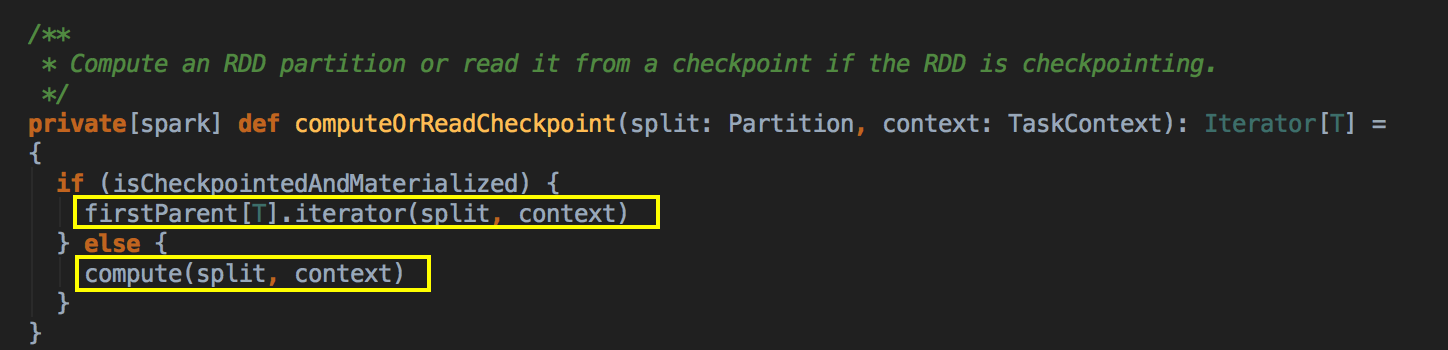
- 如果 CacheManager 没有通过 BlockManager 获得缓存内容的话,其实会通过 RDD 的 computeOrReadCheckpoint 方法来获得数据。
[下图是 RDD.scala 的 computeOrReadChcekpoint 方法]![]()
上述首先检查看当前的 RDD 是否进行了 Checkpoint ,如果进行了话就直接读取 checkpoint 的数据,否则的话就必需进行计算; Checkpoint 本身很重要;计算之后通过 putInBlockManager 会把数据按照 StorageLevel 重新缓存起来。
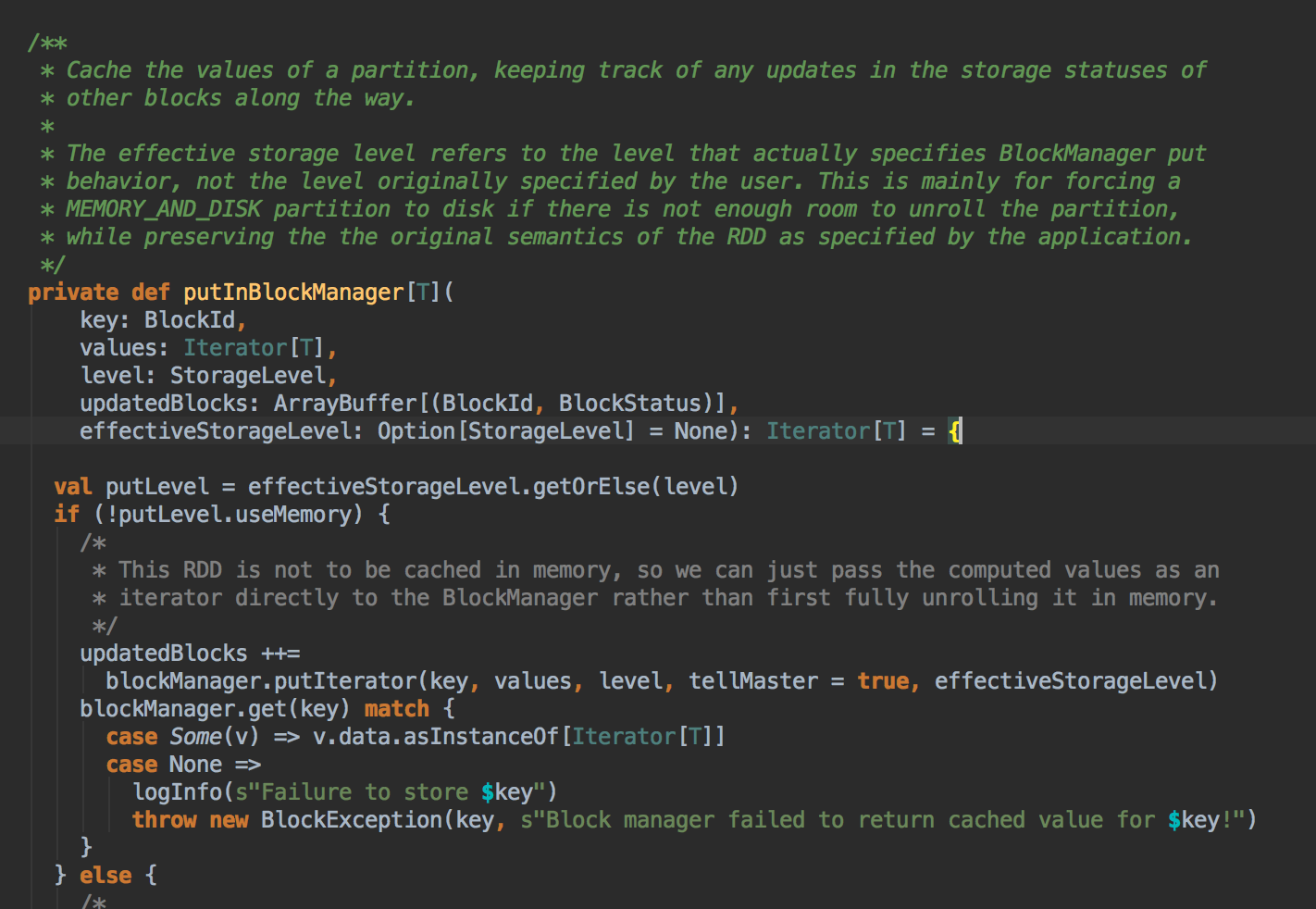
[下图是 CacheManager.scala 的 putInBlockManager 方法]![]()
![]()
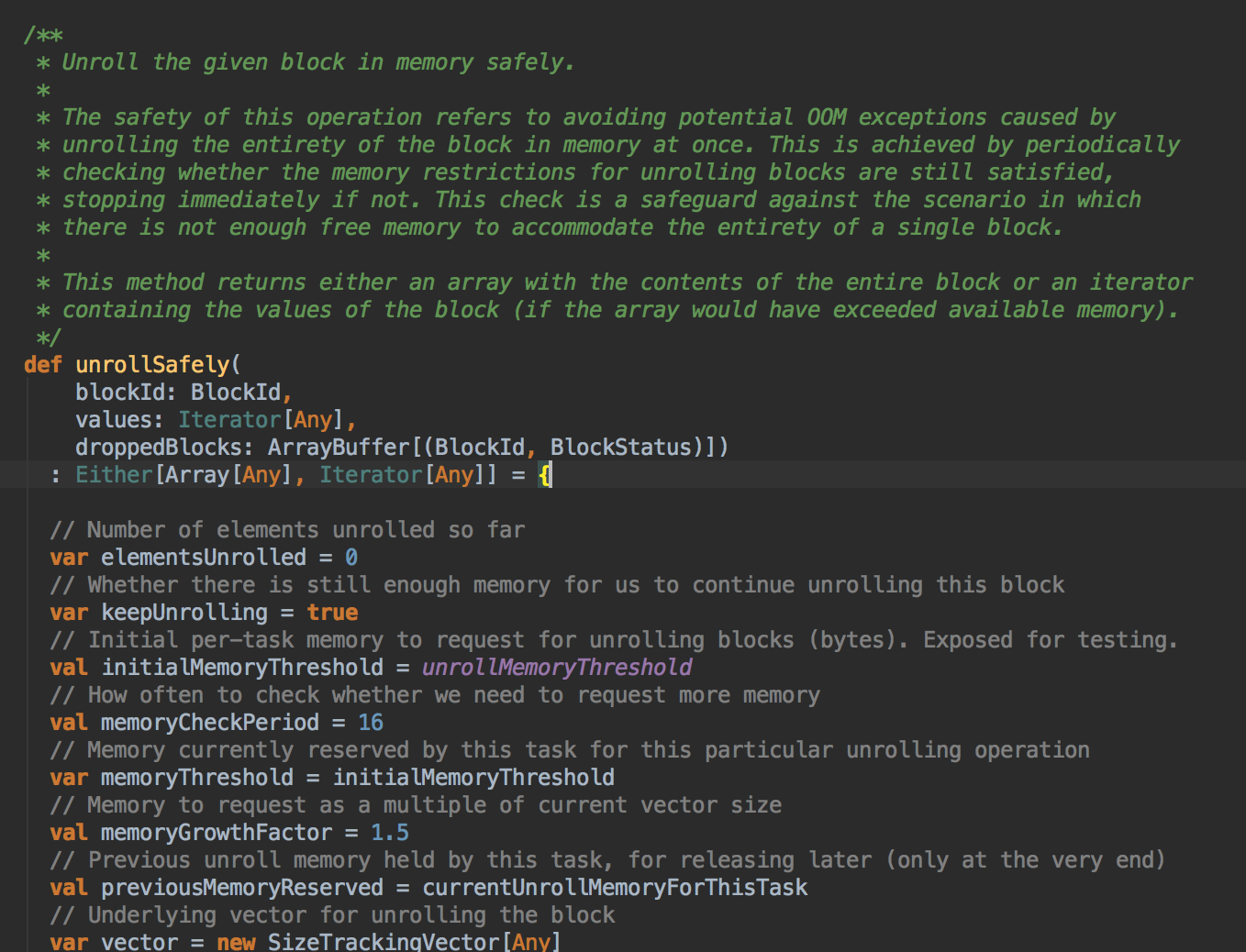
- 你如果把数据缓存在内存中,你需要注意的是内存空间够不够,此时会调用 memoryStore 中的 unrollSafety 方法,里面有一个循环在内存中放数据。
[下图是 MemoryStore.scala 中的 unrollSafely 方法]![]()





參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
Spark源码图片取自于 Spark 1.6.0版本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号