小白安装集群,历时大半个月,吐血记录,中途差点放弃,坚持就是胜利吧。
目录
一、版本说明:
-
各软件版本:
- VM Virtual Box,官网下载新版,对配置系统无影响
- ubuntu18.04 server,没有安装桌面版,因为集群里面不需要,且桌面版需要占更多内存
- hadoop3.2.0
- jvm8
- mysql8.0
- hive3.1.2
- zookeeper3.6.1
- kafka2.5.0
- spark3.0.0
-
兼容性说明:
-
spark与scala版本需要兼容:点击查看官网说明
Note that, Spark 2.x is pre-built with Scala 2.11 except version 2.4.2, which is pre-built with Scala 2.12. Spark 3.0+ is pre-built with Scala 2.12 -
spark与hadoop也需要兼容:在下载页面时候可以看到,最好下载对应版本,不过影响可能也不太大
-
kafka与scala也需要兼容:点击查看官网说明
-
zookeeper版本越高越好
-
hive与hadoop有兼容性:点击查看官网说明
-
mysql与ubuntu系统兼容性:
- ubuntu17及之前的系统版本,兼容mysql5.7
- ubuntu18之后,只兼容Mysql8.0及以上版本
-
-
版本兼容性确认顺序:
-
先确定spark版本
-
根据spark,确定scala版本
-
根据scala,确定kafka版本
-
根据spark版本确定hadoop
-
根据hadoop来确定hive
-
二、ubuntu虚拟机安装:
-
VM Virtual Box下载安装
-
新建虚拟机:
-
点击新建
-
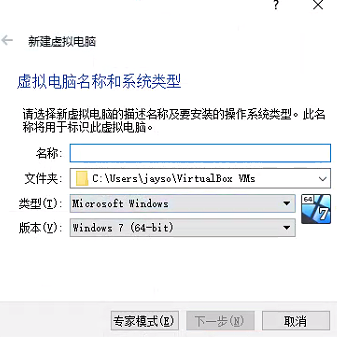
设置虚拟机名称、保存路径、选择系统类型和版本
-
下一步,根据自身需求设置内核和磁盘容量。注:磁盘容量建议设置大一点,因为是动态的,所以不会占用电脑空间,虚拟机系统实际用多少,才会动态分配多少。否则后面如果磁盘空间不够了,只有去做扩容操作,很麻烦(亲身经历,血的教训)
-
虚拟机创建好后,选择虚拟机,点击设置。
-
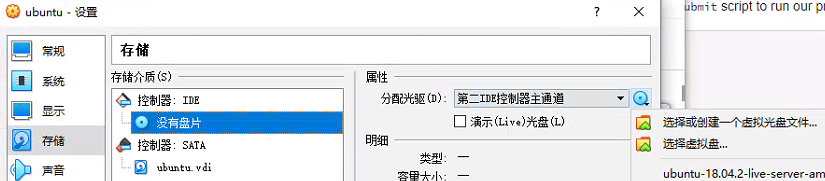
点击存储,然后点击没有盘片,然后分配光驱浏览下载的ubuntu系统iso文件
-
点击网络,连接方式选择桥接网卡,如下图所示:
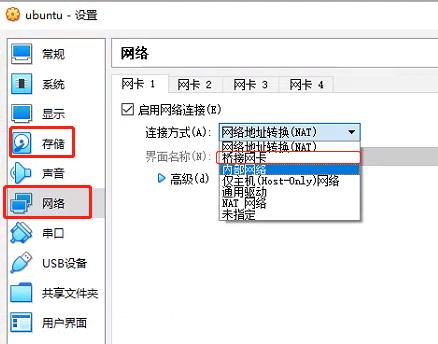
-
-
系统安装:
-
配置好虚拟机后,就开始启动虚拟机:点击启动即可。
-
在选择install ubuntu时候,选择有LVM后缀那个选项,如下图所示,后面对系统进行磁盘管理比较方便。
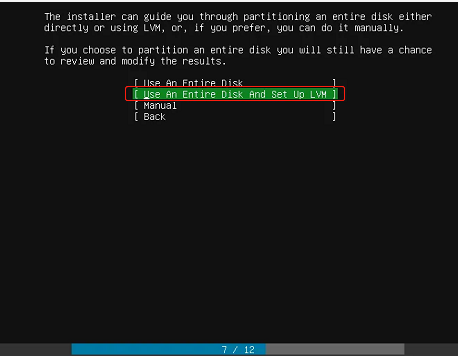
-
语言建议选择英语,其他几乎都是默认下一步,继续等。
-
主机名设置为spark1
-
用户名和密码自定义
-
-
网络配置:
-
查看主机名是否是spark1
- 查看命令:
sudo vim /etc/hostname :q退出:x退出并保存
- 查看命令:
-
查看ip地址,命令:
ip addr -
修改网络配置文件*.yaml:
- 打开文件:
sudo vim /etc/netplan/*.yaml - 将文件修改为如下格式:
network: ethernets: enp0s3: dhcp4: false addresses: [192.168.31.235/24] gateway4: 192.168.31.2 nameservers: addresses: [114.114.114.114,8.8.8.8] version: 2-
文件说明:
- dhcp4,修改为false
- addresses,ip地址(后续修改克隆机器ip也是修改这里的第四位数)。前3位数与window主机本地()网关前三位保持一致(注意,主机网关和ip的前三位不一定相同),第四位自定义但不要重复,24一般是默认
- gateway4,与windows主机本地网关保持一致
- nameservers/addresses,DSN,与window虚拟机(virtualBox适配器,如果用的VMware虚拟机就是VMware对应适配器)的ipv4保持一致,配置以后可以ping通外网域名。
- 其他默认
-
配置好后,输入
sudo netplan apply,网络设置才会生效,切记! -
设置windows虚拟机dsn:
-
打开网络适配器,选择虚拟机
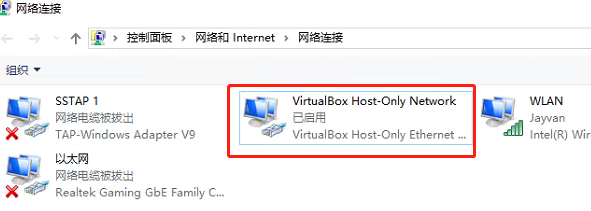
-
配置ipv4,设置自动获取IP,DSN设置与上面的nameservers/addresses一样,如下图所示:
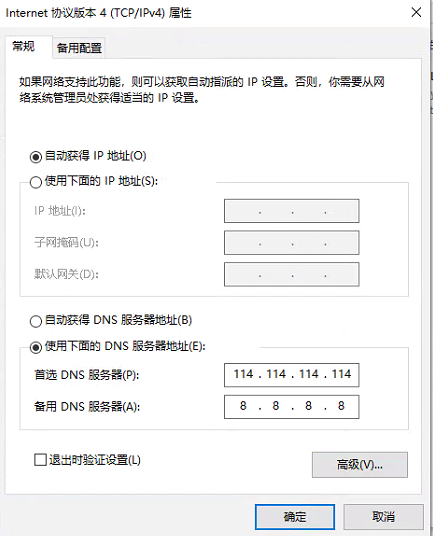
-
- 打开文件:
-
安装ssh服务:
- 安装命令:
sudo apt-get install openssh-server - 查看ssh是否正常启动:
sudo ps -e |grep ssh - 其他操作(非必需)
- ssh服务重启:
sudo service ssh restart - 有的系统需要修改sshd_config文件:
- 有的系统不修改此文件无法远程root连接,我的这个版本不存在此情况
- 修改命令:
sudo vim /etc/ssh/sshd_config
- ssh服务重启:
- 安装命令:
-
防火墙关闭
- 注:防火墙必须要关闭,不然无法进行ssh连接,集群节点之间也就无法正常通信
- 命令:
sudo ufw disable - 同时,如果想实现虚拟机与windows之间ssh通信,windows的防火墙也需要关闭。
-
安装java
-
查看java是否安装:
java -version -
java版本:
- 较新的版本是java11,若要安装执行命令:
sudo apt install default-jre - 我选择的是java8,因为此版本是得到广泛支持的。安装命令:
sudo apt install openjdk-8-jdk
- 较新的版本是java11,若要安装执行命令:
-
安装好后,执行
java -version,如果输出java版本,则说明安装成功 -
配置环境变量:
-
通过上述方式安装的java,目录是在:
/usr/lib/jvm/java-*-openjdk-amd64 -
所以环境变量配置时候添加下面内容即可:
# 注意:最后一行中的是冒号,冒号,冒号,不是分号 export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export PATH=$PATH:$JAVA_HOME/bin:JRE_HOME/bin
-
-
-
配置节点映射:
-
打开文件:
sudo vim /etc/hosts -
添加节点ip与主机名的映射:
192.168.31.44 localhost 192.168.31.236 spark3 192.168.31.235 spark2 192.168.31.234 spark1 -
配置好后,后续节点之间通信就可以使用映射的主机名,而不用输入ip地址了,当然ip地址也依然可以用。
-
-
三、克隆系统,生成多个机器:
-
上面系统配置好后,关机
-
在VM Virtual Box中,选择好上面配置的系统,右键,复制,设置好名称和路径后,选择如下选项:
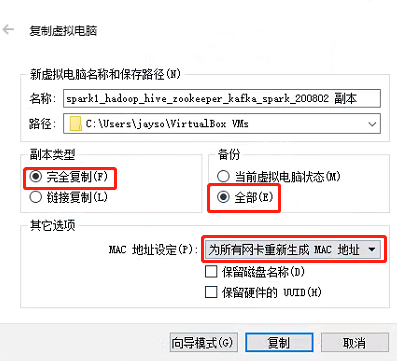
-
因为配置集群最好是3台机器,所以复制2台出来,分别命名为spark2, spark3
-
分别启动克隆的两台机器,进行如下配置:
- 配置主机名
- 命令:
sudo vi /etc/hostname - 两台主机名分别设置为spark2, spark3
- 命令:
- 修改ip地址
- 命令:
sudo vim /etc/netplan/*.yaml - 修改第一个addresses的第四个数字,最好是上一台的ip加1
- 其他默认
- 修改后使之生效,命令:
sudo netplan apply - 查看ip:
ip addr
- 命令:
- 配置主机名
-
配置3台机器之间ssh免密登录
-
分别在3台机器上执行命令:
ssh-keygen -t rsa,默认敲几次回车,生成密钥文件 -
执行上述命令后,会在当前用户家目录下生成
.ssh文件夹,密钥文件就存在此处 -
配置自己免密登录:
- 命令:
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys - 执行过后,使用
ssh user_name@host_name就可以直接免密登录本机- 上述命令中,user_name就是用户名,如果连接的其他机器用户名与本机相同,
user_name@就可以省略,只需输入所需连接的ip或者映射的主机名(映射需提前配置) - host_name,是配置的主机名,也可以是ip地址
- 比如此处可以使用:
ssh spark1直接登录本机
- 上述命令中,user_name就是用户名,如果连接的其他机器用户名与本机相同,
- 三台机器都要配置
- 命令:
-
配置机器两两之间的免密登录:
-
命令:
ssh-copy-id user_name@host_name -
实现的作用是:可以免密登录对方账号
-
比如,如果我目前登录的是spark1,然后再spark1上面使用
ssh-copy-id user_name@spark2,输入spark2密码后,就可以通过ssh spark2直接登录spark2了,以后都不用输入密码 -
通过上面的方式,对3台机器 两两之间配置免密登录
-
通过互相登录来检验
-
-
四、hadoop安装
-
hadoop必须在3台机器上安装
- 可以先配置好一台,然后通过
scp -r hadoop spark2:~的方式复制到spark2、spark3等其他机器 - 然后,再将hadoop文件夹移动到
/usr/local下面 - 同时还需复制环境变量.bashrc到spark2等机器上,并使用
source .bashrc命令来使环境变量生效
- 可以先配置好一台,然后通过
-
安装WinSCP
- 安装hadoop之前,需要在windows中,安装winscp软件
- 作用:用于将windows中的文件传输到虚拟机的linux系统中
- 安装包下载:百度搜索,很多
- 安装方法:下载好安装包后,双击安装包,选择好安装目录,一直下一步即可
- 连接虚拟机:输入linux系统的ip、端口号,以及用户名和密码即可,记得保存账号密码,后续会多次使用此软件传输安装包等
-
下载hadoop:官网(点击跳转),找到对应版本号,下载
binary版本 -
安装
-
将下载的安装包通过winscp传输到linux
-
解压:
tar -zxvf hadoop-*.tar.gz -
重命名文件夹(去掉版本号):
mv hadoop-*... hadoop -
移动文件夹到
/usr/local/:mv hadoop /usr/local/ -
配置环境变量:
vim ~/.bashrc# 在原来的基础上,新增加hadoop # 注意最后一行有bin和sbin export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$JAVA_HOME/bin:JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
生效环境变量:
source ~/.bashrc -
进入hadoop的etc目录:
/usr/local/hadoop/etc/hadoop-
修改core-site.xml文件
-
vim core-site.xml -
增加以下内容:
# spark1是主节点 <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://spark1:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> <description>该属性值单位为KB,131072KB即为默认的64M</description> </property> </configuration>
-
-
修改hdfs-site.xml文件
-
vim hdfs-site.xml -
增加以下内容:
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/data/datanode</value> </property> <property> <name>dfs.tmp.dir</name> <value>/usr/local/hadoop/data/tmp</value> </property> <property> <name>dfs.replication</name> <value>3</value> //节点数量 </property> <property> <name>dfs.namenode.hosts</name> <value>spark2, spark3</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> <description>大文件系统HDFS块大小为256M,默认值为64M</description> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> <description>更多的NameNode服务器线程处理来自DataNodes的RPCS</description> </property> <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> <dedication> Datanode 有一个同时处理文件的上限,至少要有4096</dedication> </property> </configuration>
-
-
修改mapred-site.xml文件
-
vim mapred-site.xml -
增加以下内容:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
-
修改yarn-site.xml文件
-
vim yarn-site.xml -
增加为以下内容:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>spark1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
-
-
修改workers文件
-
注:hadoop3.0版本以前是修改slaves文件
-
vim workers -
增加以下内容:
spark1 spark2 spark3
-
-
-
修改文件夹权限
sudo chown -R jayson /usr/local/hadoop/ # 创建data目录 sudo mkdir /usr/local/hadoop/data/ -
在hadoop里面添加java环境变量
-
打开文件:
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh -
在文件末尾添加java环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
-
-
-
配置完成后,需要将hadoop文件复制到其他两个节点上
- 复制hadoop:
scp -r /usr/local/hadoop spark2:~ - 复制环境变量文件:
scp ~/.bashrc spark2:~ - 然后去spark2/3..节点上,将文件夹移动到
/usr/local目录下 - 生效环境变量:
source ~/.bashrc
- 复制hadoop:
-
启动hadoop
-
先格式化hadoop
-
注意:配置好后,只能在主节点(此处的spark1)上用一次格式化命令,其他节点不用格式化。如果格式化多次,后续会出现各种问题
-
命令如下:
hdfs namenode -format
-
-
启动hdfs:
-
命令:
start-dfs.sh -
启动后,通过
jps命令查看进程- 主节点spark1上有3个进程,分别是:DataNode、NameNode、SecondaryNameNode
- spark2、spark3上分别有1个进程:DataNode
-
web端查看:
-
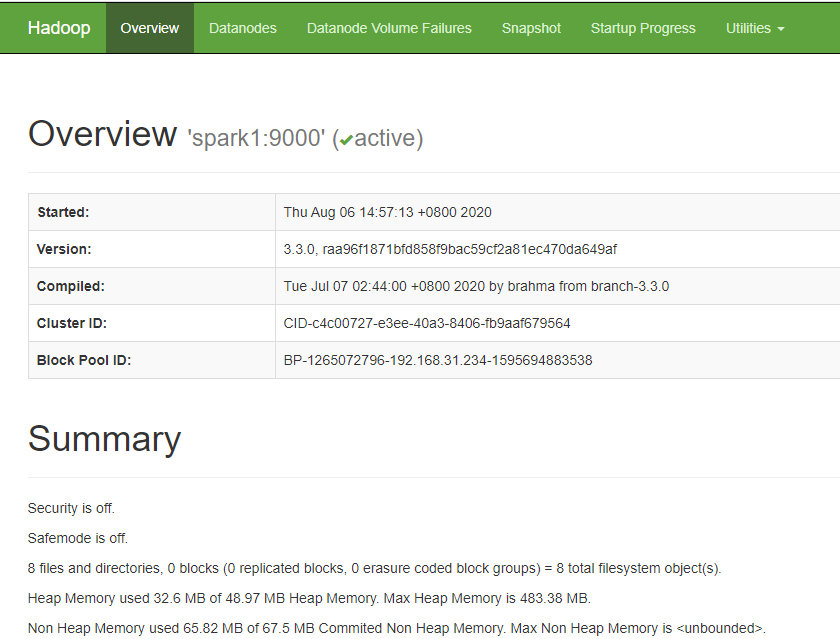
打开浏览器,输入:
http://spark1:9870/ -
会出现如下图所示网页
-
-
设置默认操作目录:
- 创建目录:使用命令
hdfs dfs -mkdir -p /user/{用户名}创建目录,用户名为系统命令行@符号前面名字。 - 测试:使用命令
hdfs dfs -ls,显示的就是此目录下的文件列表。 - 如果不创建这个目录的话,命令后面必须要加上目录路径
hdfs dfs -ls /...,不然会报错
- 创建目录:使用命令
-
-
启动yarn
-
命令:
start-yarn.sh -
启动后,通过
jps命令查看进程- 主节点spark1上有3个进程,分别是:ResourceManager、NodeManager
- spark2、spark3上分别有1个进程:NodeManager
-
web端查看:
-
打开浏览器,输入:
http://spark1:9870/ -
注:2.0和3.0版本端口不一样,对应关系点击此处参考链接
-
会出现如下图所示网页
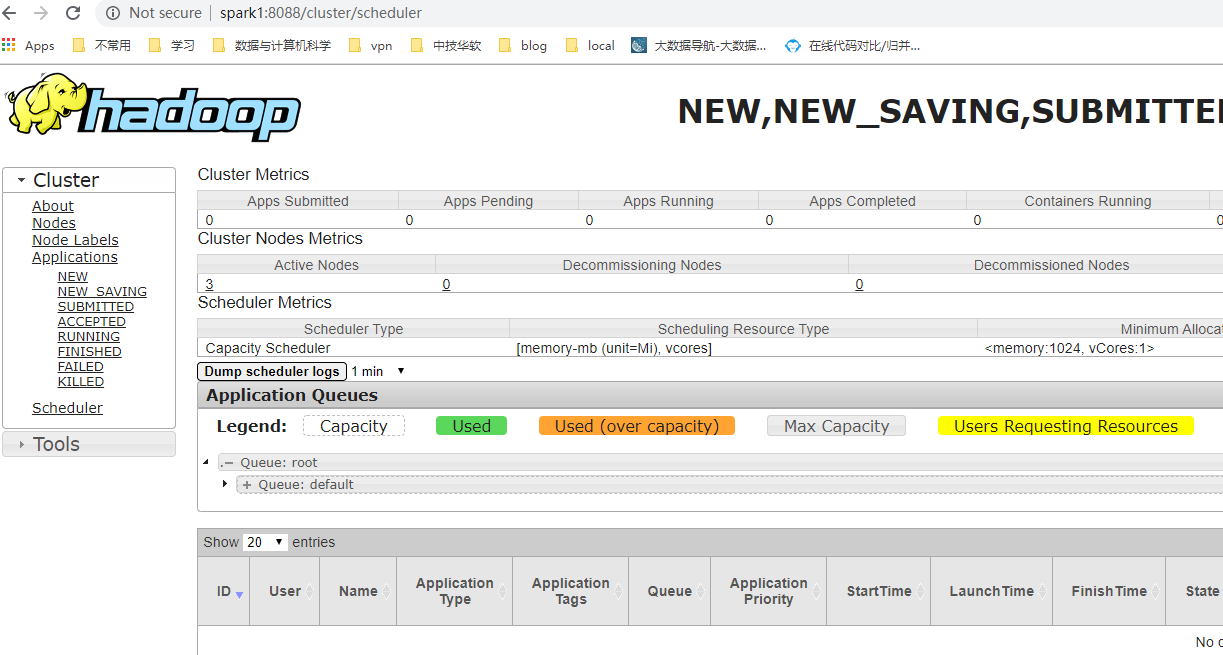
-
-
-
启动成功说明:
- 如果3台机器hdfs,yarn的进程正常,web显示正常,说明hadoop启动成功,hadoop配置完成。
- 如果出现问题,就删掉 /usr/local/data、/tmp、/usr/loca/hadoop/logs文件夹,然后重新格式化,重启电脑,反复尝试。
-
关闭:
-
关闭hdfs:
stop-dfs.sh -
关闭yarn:
stop-yarn.sh
-
-
五、mysql安装
- mysql只需要在主节点(spark1)上面安装
- 更新软件源:
sudo apt-get update - ubuntu17及之前的版本:
- 直接在终端中输入命令即可安装:
sudo apt-get install mysql-server
- 直接在终端中输入命令即可安装:
- ubuntu18及之后的版本:
六、hive安装
-
hive是基于mysql安装的前提下安装的
-
只需要在主节点(spark1)上面安装
-
下载:根据兼容性,选择所需版本下载,官网下载点击这里
-
安装配置:
-
传输到虚拟机后,解压,重命名为hive,移动到/usr/local下
-
配置环境变量:
vim ~/.bashrc# 在之前的基础上,添加hive export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export HADOOP_HOME=/usr/local/hadoop export HIVE_HOME=/usr/local/hive export PATH=$PATH:$JAVA_HOME/bin:JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin -
环境变量生效:
source ~/.bashrc -
在mysql中创建hive元数据库,并对hive进行授权
-
登录mysql
-
创建hive元数据库:
create database if not exists hive_metadata; -
对hive进行授权
-
mysql5和mysql8的授权有区别
-
mysql5
# 格式: grant all privileges on hive_metadata.* to '用户名'@'%' identified by '密码'; # 具体执行下面3句代码: grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive'; grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive'; grant all privileges on hive_metadata.* to 'hive'@'spark1' identified by 'hive'; # spark1主节点 -
mysql8
# 格式: create user '用户名'@'%' identified by '密码'; grant all privileges on `database`.* to '用户'@'%'; # 具体执行下面3对6句代码: CREATE USER 'hive'@'%' IDENTIFIED BY 'hive'; grant all privileges on hive_metadata.* to 'hive'@'%' ; CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive'; grant all privileges on hive_metadata.* to 'hive'@'localhost' ; CREATE USER 'hive'@'spark1' IDENTIFIED BY 'hive'; grant all privileges on hive_metadata.* to 'hive'@'spark1' ; -
生效mysql,查看数据库
flush privileges; use hive_metadata;
-
-
-
切换到hive 的conf目录:
cd /usr/local/hive/conf-
配置hive-site.xml:
-
重命名得到hive-site.xml文件:
mv hive-default.xml.template hive-site.xml- 执行命令: sudo vim hive-site.xml
-
通过查找以下<name> ...</name>中间的内容来修改对应的value为以下的值:
// vim编辑器中,是通过 :/ 来查找关键字 <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://spark1:3306/hive_metadata?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> // 老版本中这里可能没有.cj,这个视具体情况而定 </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.cli.print.header</name> //在hive中操作显示表头等信息,不然不会显示 <value>true</value> <description>Whether to print the names of the columns in query output.</description> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> <description>Whether to include the current database in the Hive prompt.</description> </property> -
修改相对路径为绝对路径:
- 搜索
${system:java.io.tmpdir},将其替换成/usr/local/hive/tmpdir,vim中使用命令:::%s/\/${system:user.name}//g - 将
/${system:user.name}给删除,vim中使用命令替换:::%s/${system:java.io.tmpdir}/\/usr\/local\/hive\/tmpdir/g
- 搜索
-
删除特殊字符:查找 ,删除特殊字符,不然运行会报错
-
保存并退出hive-site.xml
-
-
配置hive环境变量,添加java环境变量
-
重命名hive-site.xml:
mv hive-env.sh.template hive-env.sh -
配置hive-config.sh:
sudo vim /usr/local/hive/bin/hive-config.shexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HIVE_HOME=/usr/local/hive export HADOOP_HOME=/usr/local/hadoop
-
-
lib驱动配置:
- 两者路径分别为:
/usr/local/hive/lib/usr/local/hadoop/share/hadoop/common/lib/
- log4j-slf4j-impl**.jar文件:上面两个目录中,删除一个
- guava.jar文件:上面两个目录中,删掉低版本的,复制高版本的到原低版本路径下
- 两者路径分别为:
-
-
初始化hive:
schematool -dbType mysql -initSchema
-
-
查看hive版本:
hive -version -
启动hive:
输入hive即可启动
七、zookeeper安装
-
zookeeper需要在三台上面安装,且要分别配置不同的节点编号
-
选择新版本,官网下载链接,点击跳转
-
解压,重命名为zk,移动到/usr/local下面
-
配置环境变量:
vim ~/.bashrc# 在之前的基础上,添加zk export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export HADOOP_HOME=/usr/local/hadoop export HIVE_HOME=/usr/local/hive export ZOOKEEPER_HOME=/usr/local/zk export PATH=$PATH:$JAVA_HOME/bin:JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin -
环境变量生效:
source ~/.bashrc -
进入conf目录:
cd /usr/local/zk/conf:-
配置zoo.cfg:
-
得到zoo.cfg文件:
mv zoo_sample.cfg zoo.cfg -
修改内容:
vim zoo.cfg-
修改:
dataDir=/usr/local/zk/data -
新增:
# 注意:索引是从0开始 # 每一行行末不能有空格,不然运行时候会报错 server.0=spark1:2888:3888 server.1=spark2:2888:3888 server.2=spark3:2888:3888
-
-
-
配置完成后,返回zk目录:
cd ..
-
-
新建data目录:
mkdir data- 进入data目录:
cd data - 新建myid文件:
vim myid- 在下面写入myid文件索引编号,上面
zoo.cfg中的主机对应的索引,比如此处的:spark1对应0
- 进入data目录:
-
复制
zk和.bashrc文件到其他两台机器,source .bashrc,并修改其他两台机器中的myid文件索引 -
通过
zkServer.sh start启动,通过zkServer.sh status查看状态。(注: 需要到每台机器上面去执行命令启动zk) -
通过jps查看进程,进程标识:QuorumPeerMain
八、scala安装
-
下载:根据兼容性,选择所需版本,下载unix类型安装包,官网下载链接,点击跳转,选择other resource,即可下载对应版本
- 解压,重命名为scala,移动到/usr/local下
-
配置环境变量:
vim ~/.bashrc# 在之前的基础上,添加scala export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export HADOOP_HOME=/usr/local/hadoop export HIVE_HOME=/usr/local/hive export ZOOKEEPER_HOME=/usr/local/zk export SCALA_HOME=/usr/local/scala export PATH=$PATH:$JAVA_HOME/bin:JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin -
环境变量生效:
source ~/.bashrc -
通过scala -version查看是否安装成功
-
通过scp,将文件和环境变量传输到其他两台机器
九、kafka安装
-
根据兼容性,选择下载binary版本,官网下载链接,点击跳转
-
解压缩,重命名为kafka,移动到/usr/local下
-
不用配置环境变量
-
配置server.properties:
- 进入目录:
cd /usr/local/kafka/config - 修改文件:
vim server.properties:- 修改broker.id,每台机器的id是唯一的,且从0开始。比如spark1设置:
broker.id=0 - 设置3台机器的ip和端口号,ip根据自己实际的设定,端口号是2181:
zookeeper.connect=192.168.31.234:2181,192.168.31.235:2181,192.168.31.236:2181
- 修改broker.id,每台机器的id是唯一的,且从0开始。比如spark1设置:
- 进入目录:
-
在老版本中需要下载slf4j-nop.jar,新版本中已经不需要了。若需要下载,下载链接点击此处,下载后将其拷贝到kafka的libs目录下面
-
将配置好的kafka复制到另外两台机器上,并分别修改server.properties里面的broker.id为1和2
-
执行kafka
- 切换到kafka目录
cd /usr/local/kafka - 执行:
nohup bin/kafka-server-start.sh config/server.properties &,注:前提是每台机器的zk已启动,且kafka只需要启动1台作为 - 通过
jps可以查看到kafka进程,进程标识:Kafka - 启动kafka:
# 新建一个topic:TestTopic bin/kafka-topics.sh --zookeeper 192.168.31.234:2181,192.168.31.235:2181,192.168.31.236:2181 --topic TestTopic --replication-factor 1 --partitions 1 --create # 启动producer TestTopic bin/kafka-console-producer.sh --broker-list 192.168.31.234:9092,192.168.31.235:9092,192.168.31.236:9092 --topic TestTopic # 打开一个新窗口(其他节点的),在新窗口中启动consumer TestTopic,注意:kafka 0.9版本前后的命令有区别 bin/kafka-console-consumer.sh --bootstrap-server 192.168.31.234:9092,192.168.31.235:9092,192.168.31.236:9092 --topic TestTopic --from-beginning # 然后在producer里面输入内容,回车发送,会在consumer里面接收到消息,如果能正常接收到消息,说明kafka安装成功。 #### 其他命令: # 查看建立的topic列表: bin/kafka-topics.sh --zookeeper 192.168.31.234:2181 --list # 删除,前提是delete.topic.enable is set to true,否则只是标记为deletion ./bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic TestTopic # 查看topic ./bin/kafka-topics.sh --zookeeper localhost:2181 --list - 切换到kafka目录
十、spark安装
-
每台机器上都要安装
-
下载:进入链接,滑到页面底端,点击Spark release archives即可进入下载页面,选择所需版本下载即可
-
解压缩,重命名为spark,移动到/usr/local下
-
配置环境变量:
vim ~/.bashrc# 在之前的基础上,添加spark和class_path # 注意:如果需要使用pyspark的话,需要添加python的变量 # 具体py4j.zip包需要在spark/python/lib目录下查看 export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export HADOOP_HOME=/usr/local/hadoop export HIVE_HOME=/usr/local/hive export ZOOKEEPER_HOME=/usr/local/zk export SCALA_HOME=/usr/local/scala export SPARK_HOME=/usr/local/spark export PATH=$PATH:$JAVA_HOME/bin:JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9-src.zip export export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib -
环境变量生效:
source ~/.bashrc -
进入目录:
cd /usr/local/spark/conf-
配置spark-env.sh:
- 得到spark-env文件:
cp spark-env.sh.template spark-env.sh - 修改:
vim spark-env.sh - 增加内容如下:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 export SCALA_HOME=/usr/local/scala # 注意主节点的ip根据实际情况而定 export SPARK_MASTER_IP=192.168.31.234 export SPARK_WORKER_MEMORY=1g export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop # python使用spark export PYSPARK_PYTHON=/home/jayson/anaconda3/bin/python3 - 得到spark-env文件:
-
配置slaves文件
-
修改slaves文件为如下内容:
# 因为spark比较吃内存,所以主节点就不做slave了 # 不添加spark1,只添加2和3: spark2 spark3
-
-
-
配置完成后,将spark相关文件以及环境变量文件复制到其他机器上,并生效。
-
启动spark
- 必须到spark的sbin目录下:
cd /usr/local/spark/sbin - 执行命令:
./start-all.sh - 通过jps检查,有master进程标识表示启动成功
- 通过网页端口号启动spark,默认是8080。如果已经被占用,会自动加一比如变成8081等
- 必须到spark的sbin目录下:
-
进入sparkshell
- 输入
pyspark,可以进入pyspark环境 - 输入
spark-shell,进入scala spark环境
- 输入
十一、总结三台机器配置需要注意的地方:
- ip地址需要修改
- 主机名称需要修改
- 需要配置两两之间ssh免密登陆
- hadoop需要单独在每台机器/usr/local下新建data文件夹
- zookeeper节点编号(从0开始):myid文件,vim /usr/local/zk/data/myid
- kafka server.properties中的broker.id(从0开始):vim /usr/local/kafka/config/server.properties
- kafka启动需要到其根目录下
- kafka运行的前提条件是启动了zookeeper集群
- 更新环境变量后,记得
source .bashrc使环境变量生效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号