一、传入数据
tensor只能传入数据
可以传入现有的数据列表或矩阵
import torch
# 当是标量时候,即只有一个数据时候,[]括号是可以省略的
torch.tensor(2)
# 输出:
tensor(2)
# 如果是向量或矩阵,必须有[]括号
torch.tensor([2, 3])
# 输出:
tensor([2, 3])
Tensor可以传入数据、维度。
建议tensor给数据,Tensor给维度,不然容易把维度和数据搞混淆
# 没有[]时候是指维度,数据是随机初始化的,都接近于0
torch.Tensor(4)
# 输出:
tensor([0., 0., 0., 0.])
# 当有[]时候是指数据
torch.Tensor([2])
# 输出:
tensor([2.])
```python
# float类型
torch.FloatTensor(3)
# 输出:
tensor([0., 0., 0.])
# double类型。
# 一般在增强学习里面用Double类型,因为增强学习对数据精度要求更高。
# 其他地方一般用float类型就够了。精度越高消耗的资源也会越多。
torch.DoubleTensor(3)
# 输出:
tensor([3.5825e+246, 2.0475e+161, 3.1725e+180], dtype=torch.float64)
二、传入维度的方法
rand
# 传入维度,随机生成相应维度数据
# 生成的数是0~1之间的,随机分布的数据(均匀分布)
# 默认是N(0, 1)均值为0,方差为1
# 推荐使用rand方法初始化数据
torch.rand(2, 3, 2)
# 输出:
tensor([[[0.0316, 0.3464],
[0.2537, 0.3074],
[0.4512, 0.5535]],
[[0.5645, 0.9134],
[0.7151, 0.2645],
[0.9773, 0.6580]]])
# 维度可以加括号
torch.rand([2, 3, 2])
# 输出:
tensor([[[0.3623, 0.7754],
[0.7515, 0.0527],
[0.2006, 0.6329]],
[[0.7246, 0.0875],
[0.8303, 0.2042],
[0.7149, 0.2826]]])
rand_like
a = torch.ones(2, 3)
a
# 输出:
tensor([[1., 1., 1.],
[1., 1., 1.]])
# 根据a数据的shape来生成随机数据
# 另外还有:ones_like、zeros_like等。
torch.rand_like(a)
# 输出:
tensor([[0.6721, 0.8581, 0.2823],
[0.0510, 0.9334, 0.8291]])
randint
# 生成1~10之间随机整数
# [2, 5]是维度
torch.randint(1, 10, [2, 5])
# 输出:
tensor([[8, 2, 5, 5, 2],
[5, 7, 8, 1, 7]])
normal
# 生成正态分布数据
# 维度2行3列
# 均值为4
# 方差0.6-0.1的数据。方差数据量需要与维度数据量相等:
# 比如此处是2*3=6个数据。方差就是6个数据。
torch.normal(mean=torch.full([2, 3], 4), std=torch.arange(0.6, 0, -0.1))
# 输出:
tensor([[3.7889, 3.9049, 3.9840],
[4.1137, 3.9285, 4.0589]])
full
# 生成给定维度,全部数据相等的数据
torch.full([2, 3], 7)
# 输出:
tensor([[7., 7., 7.],
[7., 7., 7.]])
# 也可以给定空维度,生成标量
torch.full([], 7)
# 输出:
tensor(7.)
# 一维,长度为1的向量
torch.full([1], 7)
# 输出:
tensor([7.])
arange
也可以用 range(),但不推荐
# 生成[0, 10)的tensor
torch.arange(0, 10)
# 输出:
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 生成[0, 10)间隔为2的tensor
torch.arange(0, 10, 2)
# 输出:
tensor([0, 2, 4, 6, 8])
linspace
# 将[0,10]等分切割成4份
torch.linspace(0, 10, steps=4)
# 输出:
tensor([ 0.0000, 3.3333, 6.6667, 10.0000])
ones
# 给定维度,生成全为1的数据
c = torch.ones(3, 3)
c
# 输出:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
ones_like
torch.ones_like(c)
# 输出:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
zeros
# 生成全为0的tensor
a = torch.zeros(3, 3)
a
# 输出:
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
zeros_like
torch.zeros_like(a)
# 输出:
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
eye
torch.eye(3, 3) # 生成对角矩阵
# 输出:
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
torch.eye(3, 4) # 若不是方阵,最后多的列会用0填充
# 输出:
tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.]])
empty
# 给定维度,随机生成未初始化的数据
# 非常不规则,可能出现非常大,非常小的情况,尽量要覆盖完成数据
torch.empty(1, 2)
# 输出:
tensor([[ inf, 6.9533e-310]])
randperm
生成随机排序的整数序列
torch.randperm(10) # 相当于[0, 10) 的随机排序
# 输出:
tensor([0, 5, 3, 9, 8, 1, 2, 6, 7, 4])
# 定义a、b两个维度相等的数据
a = torch.rand(2, 3)
a
# 输出:
tensor([[0.5030, 0.5566, 0.5968],
[0.9044, 0.5012, 0.2717]])
b = torch.rand(2, 3)
b
# 输出:
tensor([[0.4264, 0.5325, 0.4145],
[0.6967, 0.1065, 0.0063]])
# 随机生成2个维度数据
idx = torch.randperm(2)
idx
# 输出:
tensor([1, 0])
# 相当于a、b同时根据随机生成的维度排序+
a[idx]
# 输出:
tensor([[0.9044, 0.5012, 0.2717],
[0.5030, 0.5566, 0.5968]])
b[idx]
# 输出:
tensor([[0.6967, 0.1065, 0.0063],
[0.4264, 0.5325, 0.4145]])
三、数据维度查看
# 生成数据
a = torch.Tensor(2, 3, 4)
a
# 输出:
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
a.shape # 注意shape没有括号
# 输出:
torch.Size([2, 3, 4])
a.size() # 与shape等价
# 输出:
torch.Size([2, 3, 4])
a.dim() # 表示维度
# 输出:
3
len(a) # 查看第一维度数据大小
# 输出:
2
tensor数据内存大小查看
a.numel()
# 输出:
24
四、pytorch数据类型
-
标量:
可以理解为常量,没有方向的向量(只有数值,没有方向),dimension=0
常用于计算loss。预测值与真实值之间误差计算出来就是标量 -
张量:
张量与标量的区别:张量有方向(维度)
二维:适合线性batch输入,比如:torch.randn(2, 3) # 随机生成2行3列的张量。
三维:torch.rand(1, 2, 3);三维适合RNN,[10, 20, 100] 20个句子,10个单词,每个单词用一个100维的向量表示
四维:torch.rand(2, 3, 28, 28) 2张照片,3个通道,照片大小28(h)*28(w); -
pytorch数据类型:
pytorch只支持数字类型数据,不支持字符串类型数据。
如果要用pytorch来表示string,就将string转换为数字编码(或矩阵、向量)来处理。常用方法:One-hot,Embedding(Word2vec, glove)
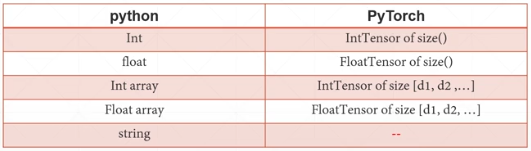
tensor和numpy类型互换:
直接将tensor转换为numpy
a = torch.Tensor([2, 3])
a
# 输出:
tensor([2., 3.])
a.numpy()
# 输出:
array([2., 3.])
将numpy数据转换为张量
import numpy as np
a = np.array([3, 4])
a
# 输出:
array([3, 4])
torch.from_numpy(a)
# 输出:
tensor([3, 4], dtype=torch.int32)
1. tensor数据类型查看
a = torch.Tensor(2)
a.type() # 查看tensor的数值类型
# 输出:
'torch.DoubleTensor'
type(a) # 返回数据类型是tensor,但是不会返回具体的数值类型
# 输出:
torch.Tensor
2. 判断数字类型是否是指定类型
a = torch.Tensor(2)
# 判断a的数值类型是否是float
isinstance(a, torch.FloatTensor), isinstance(a, torch.DoubleTensor)
# 输出:
(False, True)
# GPU与CPU数据比较
b = a.cuda() # 将b布置在GPU上。(数据默认是布置在CPU上的)
# CPU和GPU数据不能直接比较
isinstance(b, torch.FloatTensor), isinstance(b, torch.DoubleTensor)
# 输出:
(False, False)
# 若要进行比较,需要将数据转换为GPU
isinstance(b, torch.cuda.FloatTensor), isinstance(b, torch.cuda.DoubleTensor)
# 输出:
(False, True)
设置默认数据类型
1. 设置默认数据类型前
# Tensor默认是Float类型
a = torch.Tensor(2)
a.type() # 查看数据类型
# 输出:
'torch.FloatTensor'
a = torch.Tensor([2.])
a.type()
# 输出:
'torch.FloatTensor'
# tensor传入整数默认是LongTensor类型
a = torch.tensor(2)
a.type()
# 输出:
'torch.LongTensor'
# 传入小数,是Float类型
a = torch.tensor(2.)
a.type()
# 输出:
'torch.FloatTensor'
2. 设置默认数据类型后
# 设置默认tensor数据类型
torch.set_default_tensor_type(torch.DoubleTensor)
# 即使设置了默认数据类型是double,但是给定的数据中至少要有一个是小数,不然设置会无效
a = torch.tensor([2, 3])
a.type()
# 输出:
'torch.LongTensor'
# 加了小数后,数据类型就是设置的默认double类型
b = torch.tensor([2., 3])
b.type()
# 输出:
'torch.DoubleTensor'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号