Nginx知多少系列之(七)负载均衡策略
目录
1.前言
2.安装
3.配置文件详解
4.工作原理
5.Linux下托管.NET Core项目
6.Linux下.NET Core项目负载均衡
7.负载均衡策略
8.加权轮询(round robin)策略剖析
9.IP哈希(ip hash)策略剖析
10.最少连接(least_conn)策略剖析
11.随机(random)策略剖析
12.URL哈希(url hash)策略剖析
13.响应时间(fair)第三方模块详解
14.Linux下.NET Core项目Nginx+Keepalived高可用(主从模式)
15.Linux下.NET Core项目Nginx+Keepalived高可用(双主模式)
16.Linux下.NET Core项目LVS+Keepalived+Nginx高可用集群
17.构建静态服务器
18.日志分析
19.优化策略
20.总结
目前Nginx服务器的upstream模块支持5种方式的策略:round robin(轮询)、ip_hash(ip哈希)、least_conn(最少连接)、url_hash(url哈希)、random(随机)、fair(响应时间),下面我们将逐一的介绍,当然了具体的原理剖析请看具体的文章。
下面的内容是基于上一篇文章,所以有不懂如何部署或者文件在哪里的,可以阅读《Nginx知多少系列之(六)Linux下.NET Core项目负载均衡》
1.round robin(轮询)
轮询是Nginx默认的策略,上面的配置就是轮询的方式,每个请求按照时间顺序逐一分配到不同的后端服务器,不关心服务器实际的连接数和当前的系统负载,若所有服务器都已被调度过,则从头开始调度,相当于人人都有份。
适合于服务器组中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
①、默认轮询
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132; server 192.168.157.133; server 192.168.157.138; } #按Esc,:wq保存退出 #重启nginx sudo nginx -s reload
每次Nginx启动或者重启之后,都会从配置服务器组里面的第一个开始轮询,按照请求时间逐一的分配下去、例如Nginx启动,发起请求,按照轮询会访问132服务器,再发起请求,访问133服务器,以此类推。当最后一次访问是133服务器时,我们重启Nginx,然后发起请求,又从第一个服务器开始轮询,即132服务器,如下图

②、weight
Nginx默认的weight为1,表示每一台服务器权重都一样,按照请求时间顺序分配到具体的服务器,因此我们可以在轮询的基础上,加入weight(权重),Weight 指定轮询权值,Weight值越大,分配到的访问机率越高,主要用于后端每个服务器性能不均的情况下。一般来说权重是用在服务器性能不一的情况下,性能较好的服务器响应的请求可以更多一些。还有一种情况就是上线部署的时候,我们可以把其中一台权重比例降低,只引流部分的,然后只上线这一台服务器,部分引流的客户可以使用最新的功能。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132 weight=4; server 192.168.157.133 weight=3; server 192.168.157.138 weight=3; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
在这里我们配置132权重为4,133的权重为3,138的权重为3。相当于每10次请求里,有四次为132的服务器,三次为133的服务器,三次为138的服务器,具体的服务器顺序132,133,138,132,133,138,132,133,138,132,看下图效果。

一开始还没具体去验证的时候,就认为按照上面的权重,每10次请求里,前面四次为132,后面三次为133,最后三次为138。顺序的结果为132,132,132,132,133,133,133,138,138,138。这种想法呢,是普通的基于权重的轮询算法。但是这样的算法得出来的加权请求顺序并不好,假如我们把权重设置的比较大的时候,它会一下子把大压力压到同一台机器上,这样会产生一个机器一下子很忙的情况。
所以Nginx的加权是基于平滑的轮询,所谓平滑就是调度不会集中压在同一台权重比较高的机器上。这样对所有机器都更加公平。
此轮询调度算法思路首先被 Nginx 开发者提出,见 phusion/nginx 部分。
那么它是怎么实现的?更详细的内容请看《Nginx知多少系列之(八)加权轮询(round robin)策略剖析》
③、max_fails
这个是Nginx在负载均衡功能中,用于判断后端节点状态,所用到两个参数其中之一,表示在设置的fail_timeout时间内与后端节点通信失败的尝试次数,默认为1,超出失败尝试次数则认为后端节点在fail_timeout内不可用,等待下一个fail_timeout再次尝试通信。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132 max_fails=3; server 192.168.157.133 max_fails=4; server 192.168.157.138 max_fails=4; } #按Esc,:wq保存退出 #重启nginx sudo nginx -s reload
我们来试试132最大失败次数为3,133最大失败次数为4,138最大失败次数为4,fail_timeout默认是10s,看看日志情况以及会不会自动剔除,首先先正常访问,然后停止192.168.157.132服务,最后在访问看效果,上图

上面的图片,正常情况下是均衡的轮下三台服务器,当我人为挂掉了132服务器之后,再次访问,Nginx探测到132服务器已经停止服务,自动请求到了133和138服务器。
那么我们下面先重启Nginx,在用Postman连续请求60次,每秒一次,看看error日志探测后端节点的结果。
不过我们来先看看如何创建Postman测试
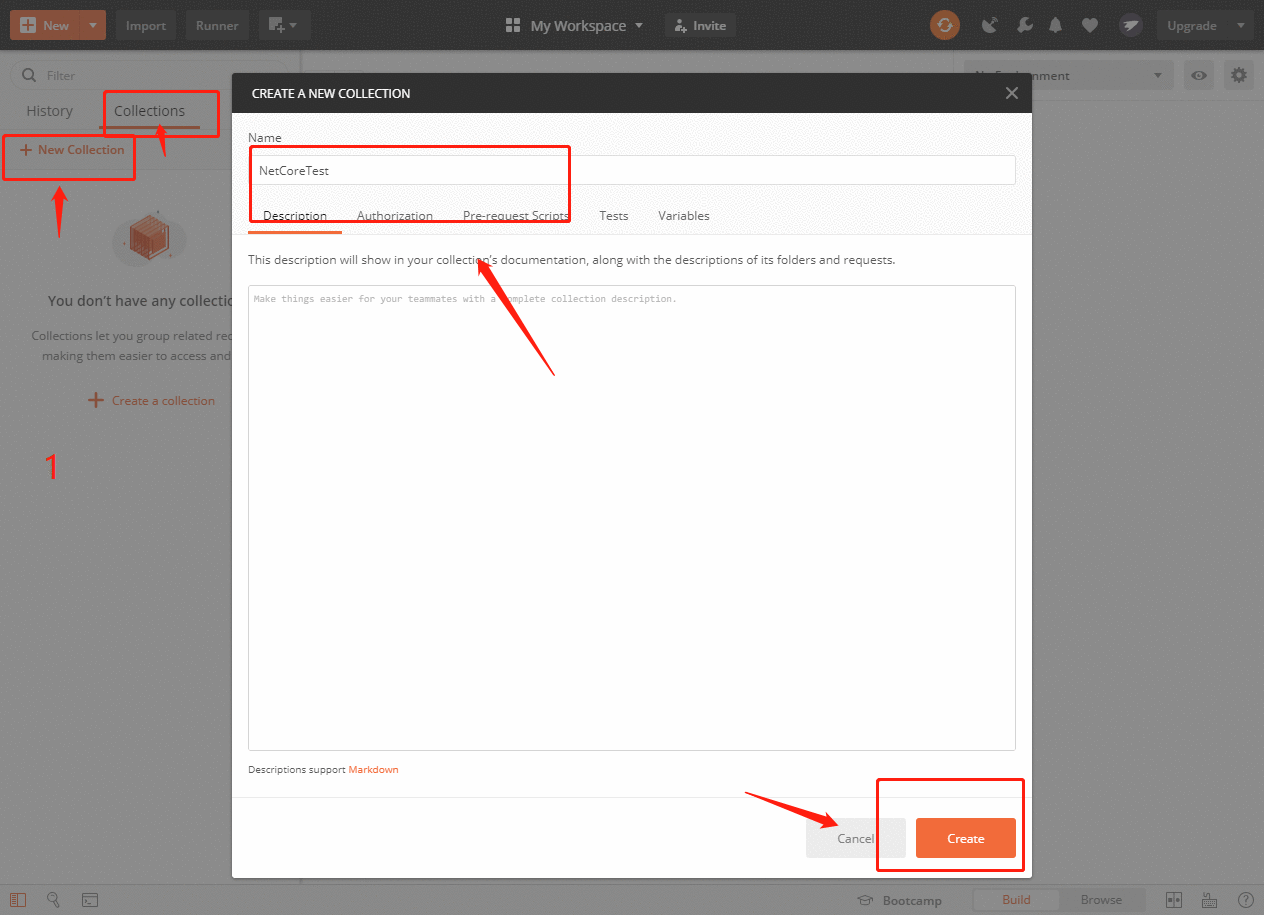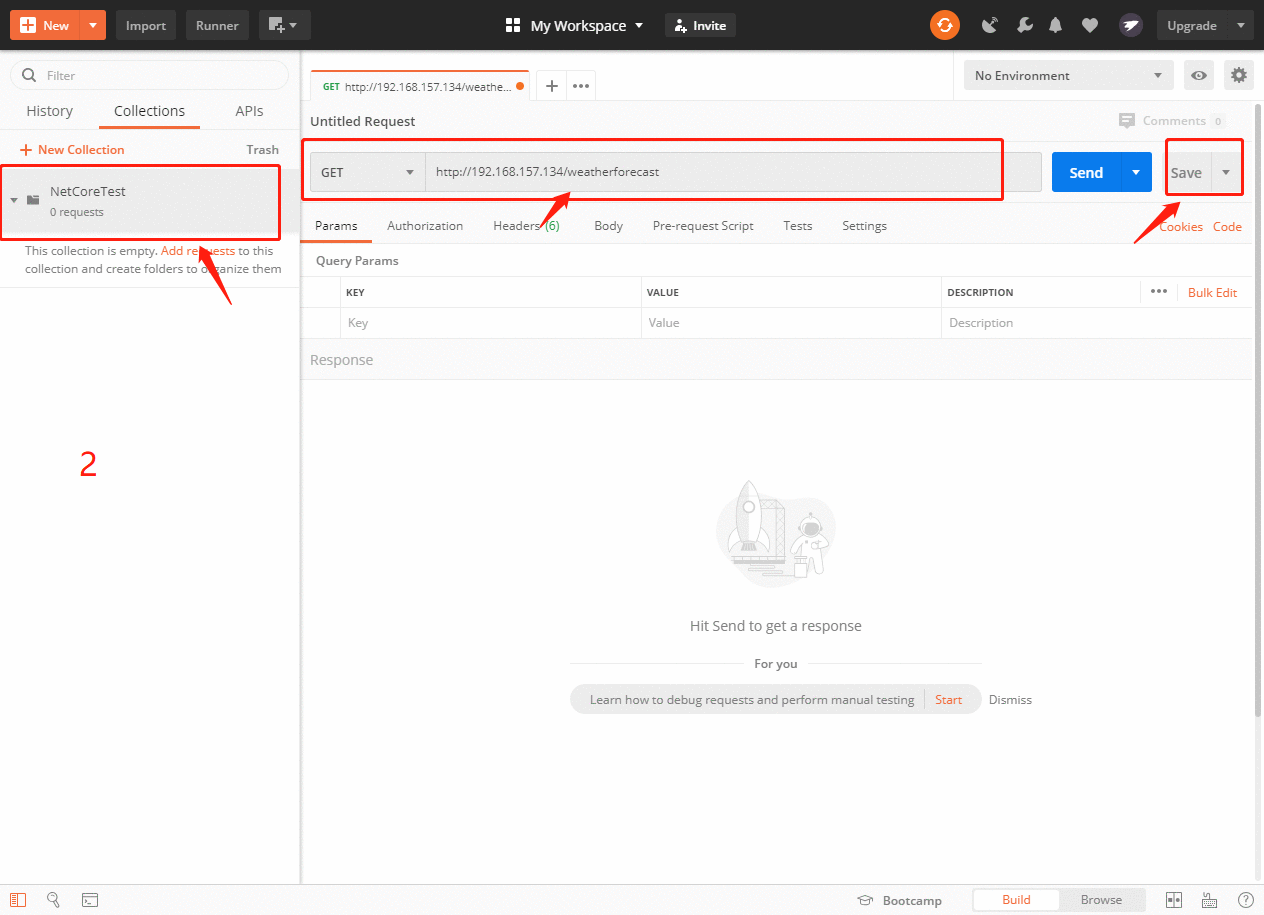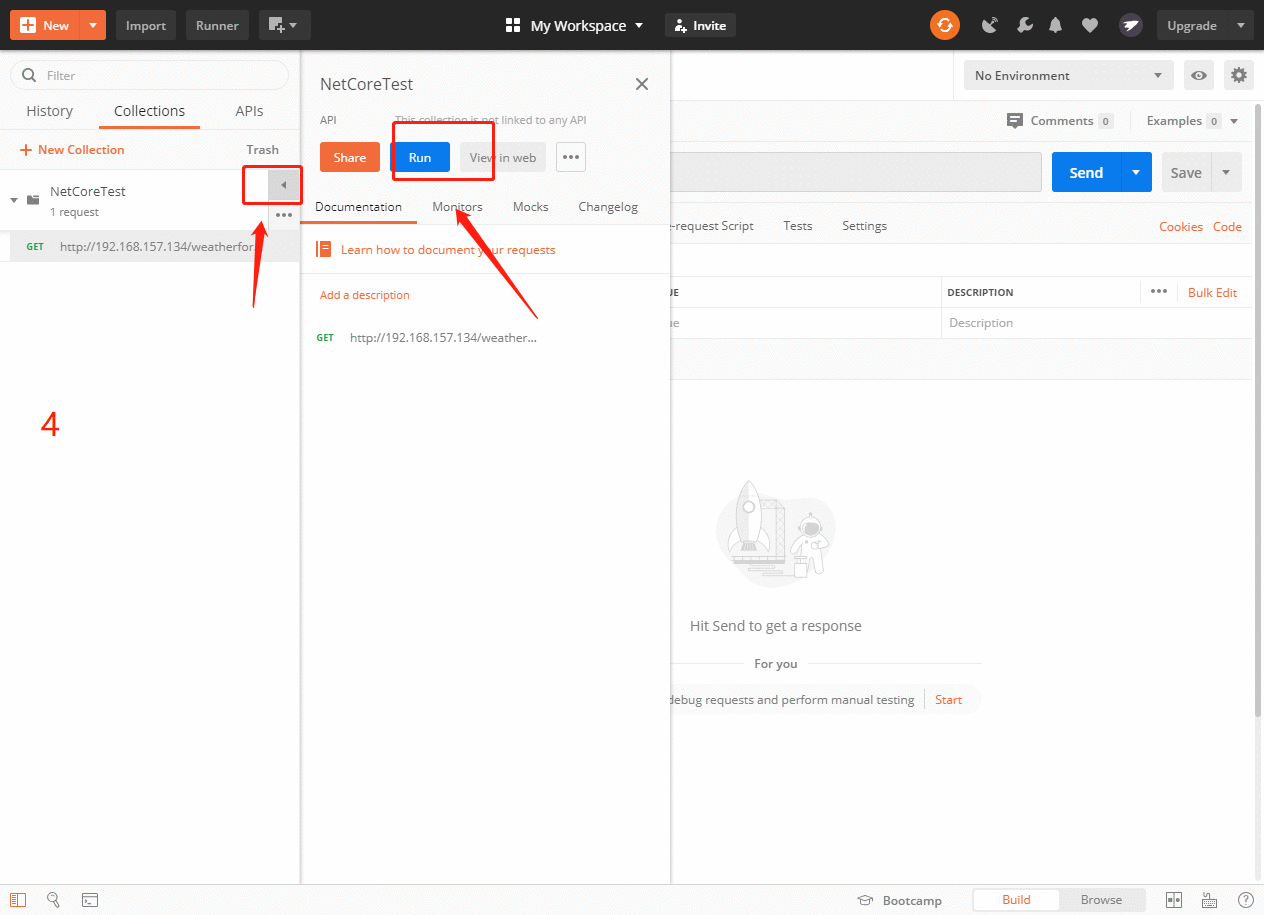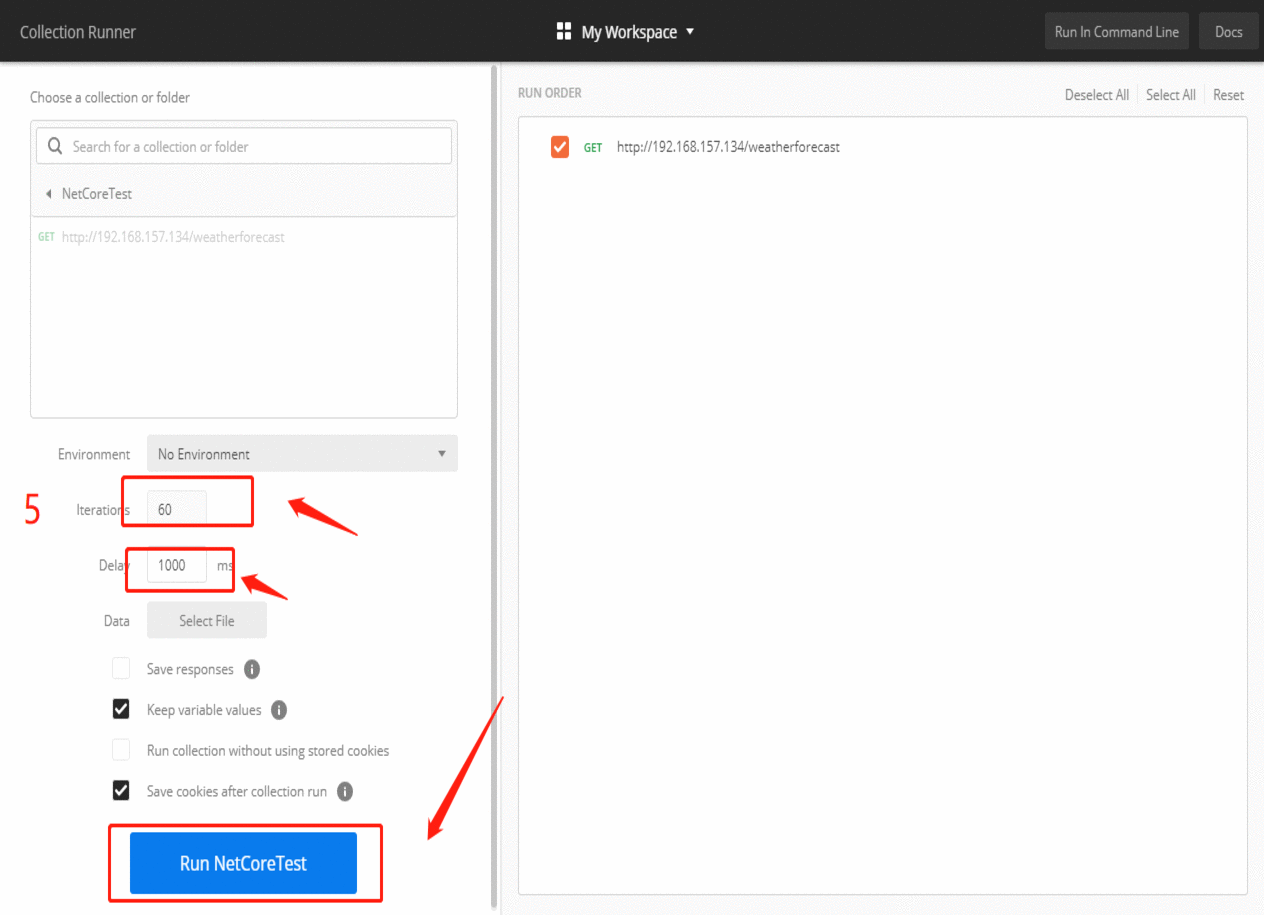
- 首先我们选择左边的collections->New Collection,输入自定义名称,如NetCoreTest,按Create保存。
- 勾选左边刚刚新建的collection,然后右边Request输入要测试的URL:http://192.168.157.134/weatherforecast,按Save,打开之后,选择Select a collection or folder to save to为NetCoreTest,最后Save to NetCoreTest保存
- 选择刚刚的collection,点Run,弹出Collection Runner
- 按照图片5配置,执行60次,每隔一秒执行一次请求
#为了方便观察,我们先把原来的日志清空 sudo vim /var/log/nginx/error.log #输入:%d,清空文件内容 #按Esc,然后:wq保存退出 #重启Nginx sudo nginx -s reload
我们来看看Error日志的内容
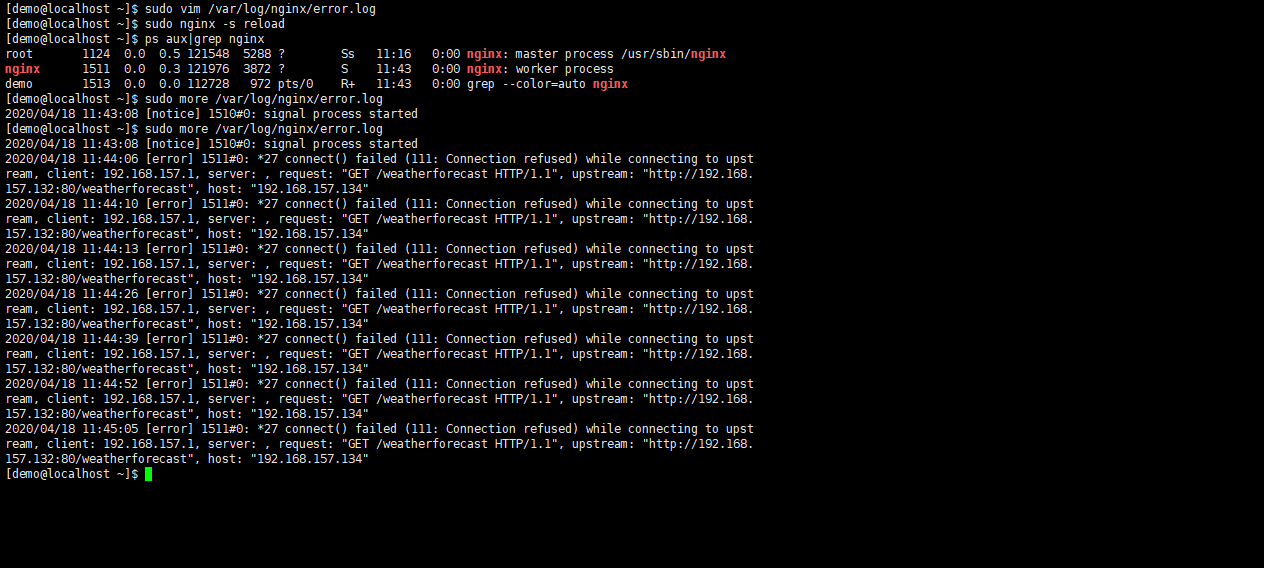
- 我们在132服务器设置max_fails为3,表示尝试通信服务器失败3次
- 从上面可以看到一开始06秒,10秒,13秒分别轮询到了132服务器,但是都失败了
- fail_timeout没有设置,默认为10S,表示服务器不可用时间段
- 从第三次尝试与132服务器通信失败之后的那一刻算起,接下来的fail_timeout的时间段内服务器不可用
- 等到fail_timeout时间段过后,当轮询到132服务器,又尝试通信
- 如果通信132服务器成功,则返回结果
- 如果继续通信失败,则有且仅会通信132服务器一次,然后就标记服务器为不可用,继续等待fail_timeout
- 如果我们在通信132服务器成功后,当再次轮询到132服务器,然后通信失败,接着循环上面的操作,重新通信探测尝试失败max_fails的次数才标记为服务器不可用
言外之意就是说首次请求失败或者成功后的请求失败,需要探测max_fails次数才会标记不可用,标记后,每隔fail_timeout,连续请求失败的,仅会探测请求一次,随即进入下一个周期。这也是为什么上图中26秒,39秒,52秒,05秒,有且只有一次请求132失败的原因。
Nginx基于连接探测,如果发现后端异常,在单位周期为fail_timeout设置的时间,中达到max_fails次数,这个周期次数内,如果后端同一个节点不可用,那么接将把节点标记为不可用,并等待下一个周期(同样时常为fail_timeout)再一次去请求,判断是否连接是否成功。如果成功,将恢复之前的轮询方式,如果不可用将在下一个周期(fail_timeout)再试一次。
④、fail_timeout
在上面讲解max_fails其实也讲到fail_timeout的作用,在Nginx里默认为10S。
当与服务器通信尝试不成功之后,标记为fail_timeout时间范围内服务器不可用,也就是服务器不可用的时间段。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132 max_fails=3 fail_timeout=20s; server 192.168.157.133 max_fails=4 fail_timeout=20s; } #按Esc,:wq保存退出 #为了方便观察,我们先把原来的日志清空 sudo vim /var/log/nginx/error.log #输入:%d,清空文件内容 #按Esc,然后:wq保存退出 #重启Nginx sudo nginx -s reload
上面我们配置的是20S为服务器不可用时间段,同时清空日志,然后我们用Postman测试120次,每隔一秒发一次请求,按照第③点去设置Postman请求测试。我们来看看Error日志
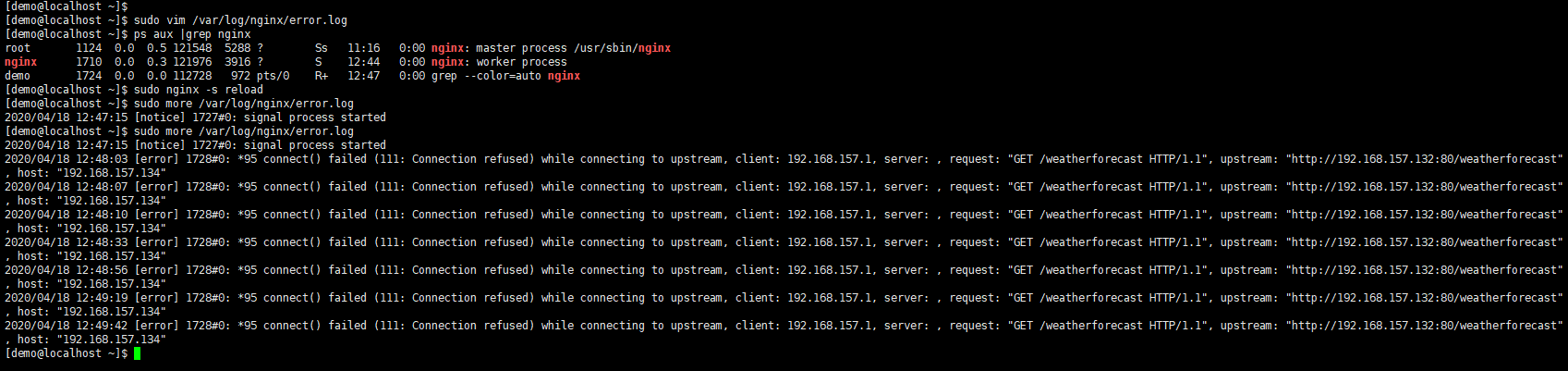
在这里我们设置了132服务器最大允许失败max_fails为3次,不可用时间段fail_timeout为20S,所以上图一开始请求失败了三次就标记为服务器不可能,请求过程中还是以每秒发一次请求到服务器,但是当132标记为不可用的时间段内,就直接把请求转发到133或138服务器上,当下一个周期20S,又开始探测。
另外这里的max_fails最大尝试通信次数指的不是在fail_timeout时间段内的统计,而是统计整个运行过程中的累计,我们来验证下
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132 max_fails=3 fail_timeout=120s; server 192.168.157.133 max_fails=4 fail_timeout=120s; } #按Esc,:wq保存退出 #为了方便观察,我们先把原来的错误日志清空 sudo vim /var/log/nginx/error.log #输入:%d,清空文件内容 #按Esc,然后:wq保存退出 #为了方便观察,我们先把原来的请求日志清空 sudo vim /var/log/nginx/access.log #输入:%d,清空文件内容 #按Esc,然后:wq保存退出 #重启nginx sudo nginx -s reload #关闭132服务器的Nginx服务 sudo nginx -s stop
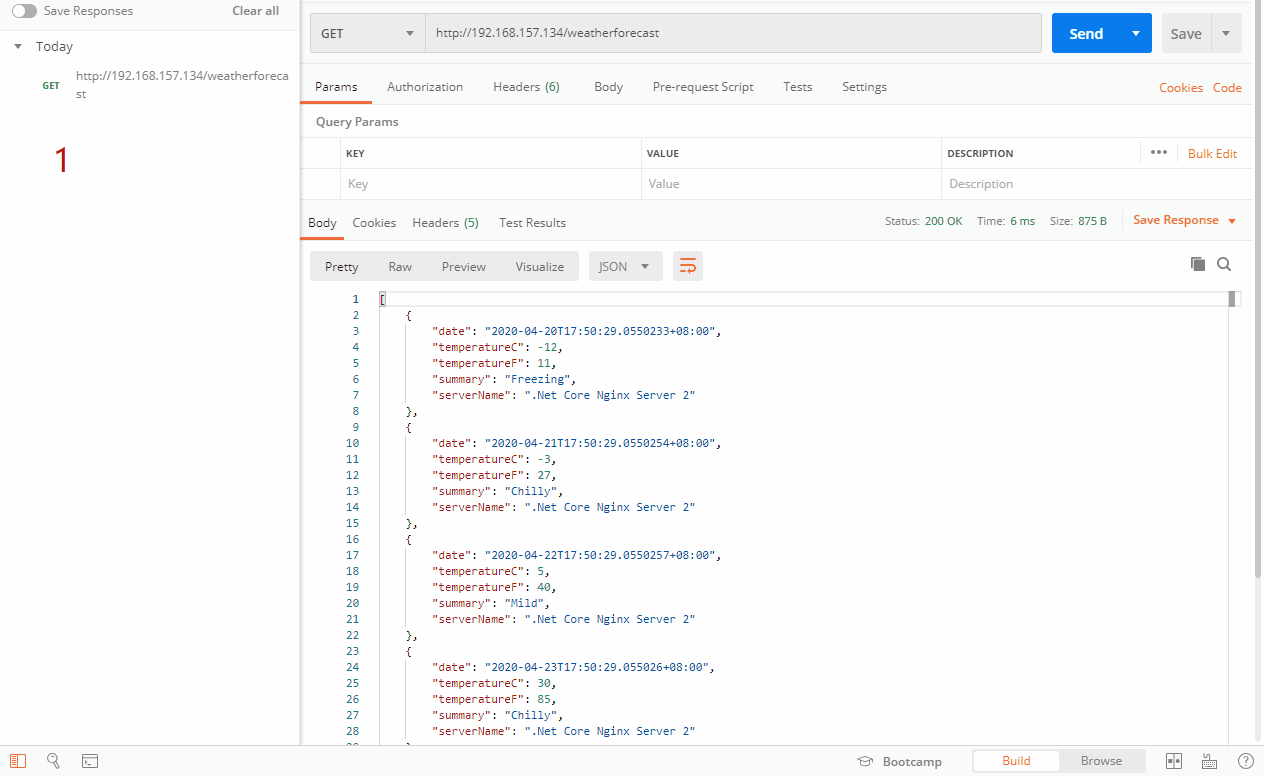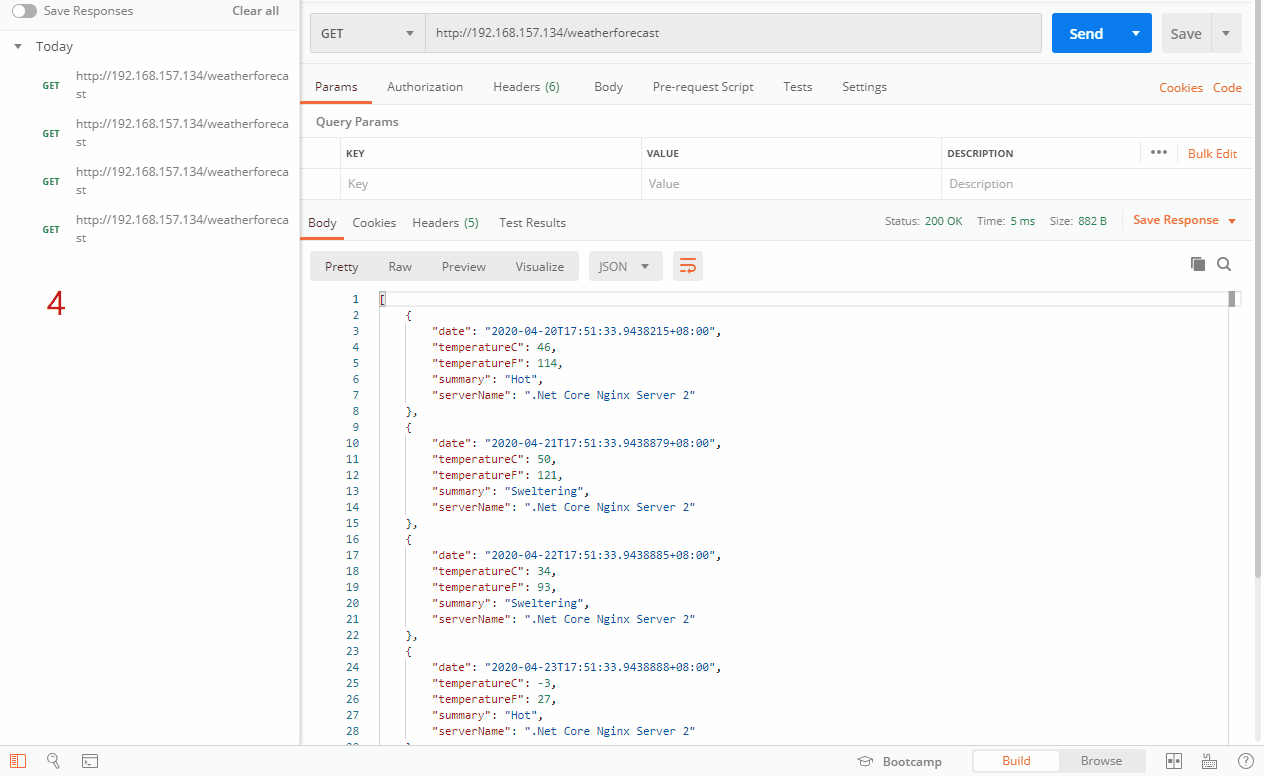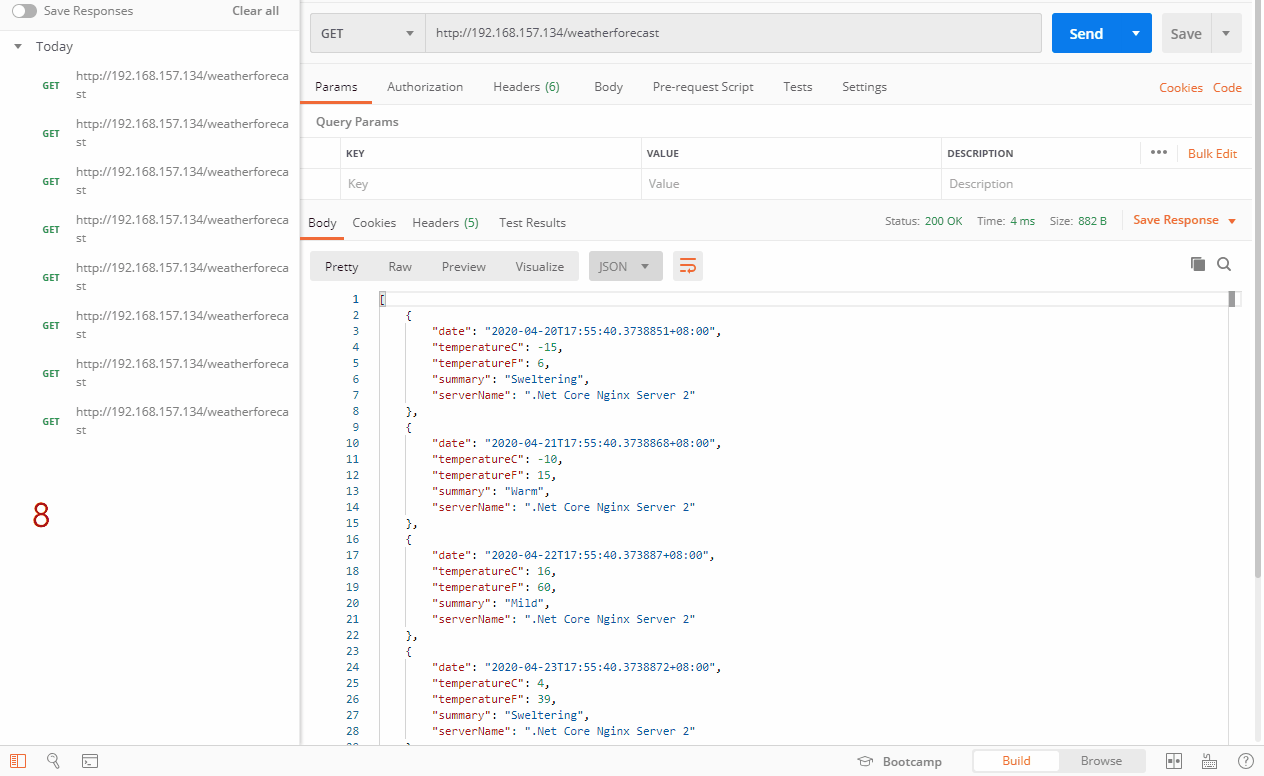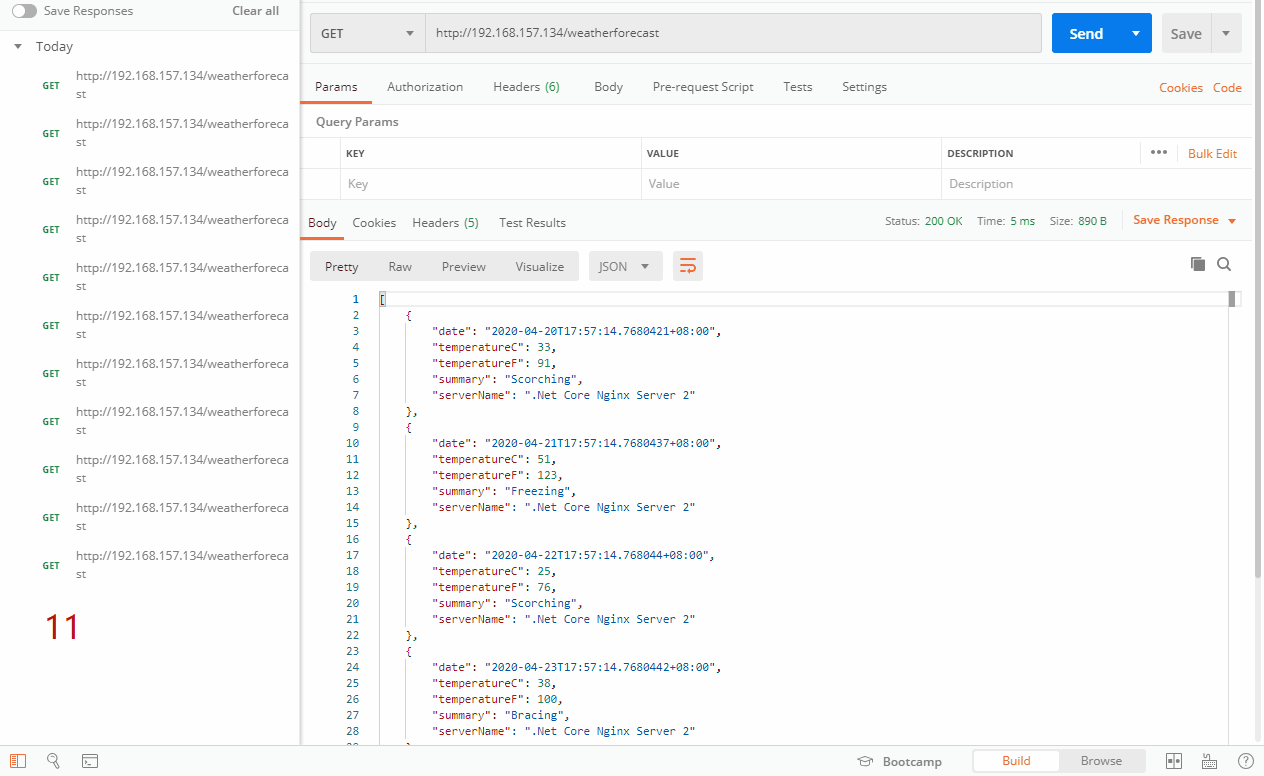
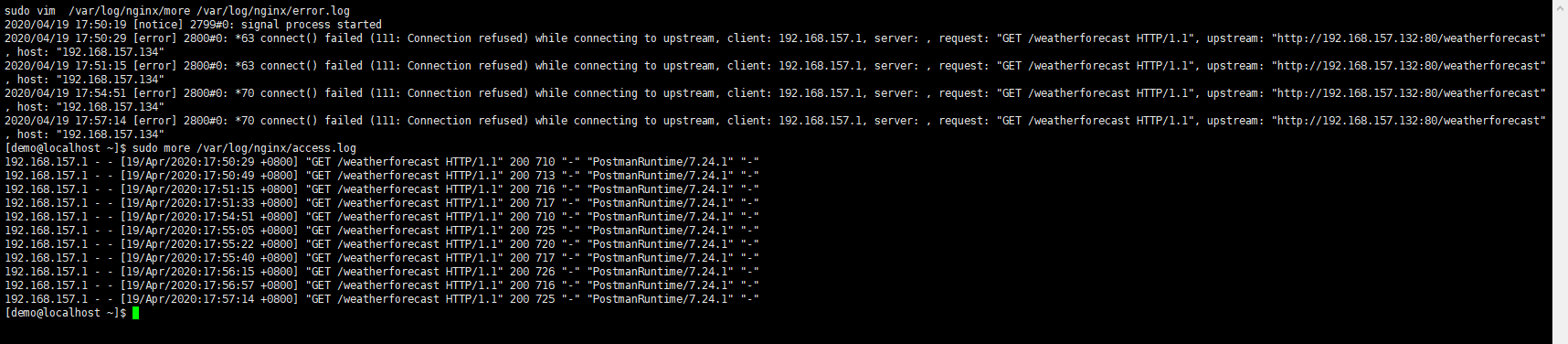
在这里我们设置最大允许失败次数为3,不可用时间段为120秒,我们可以看到在50分19第一次访问132服务器,但是请求失败。在51分15秒又请求了132服务器,还是失败的,当我们过了几分钟后,在54分51秒第三次请求失败132服务器,这个时候已经达到max_fails的次数,从这一刻起的120秒内,132服务器将不可用,我们可以看到access.log里面,在54分51秒后的120秒内,我们发起了4次请求,但是没有一次是请求132的,说明132在这段时间内已经被标记为不可用,哪怕我们开启132的Nginx服务,也不会把请求发到132服务器上。在57分14秒,又请求到了132服务器,过了不可用时间段,又重新与132服务器尝试通信。注意:失败次数的累加过程中,哪怕中途成功访问,也不会重置失败次数,后面再失败,也按之前次数累加。在标记为不用之后,过了不可用时间段,如果成功通信成功,则会重置失败次数。
⑤、backup
其它所有的非backup Server down或者忙的时候,请求backup机器。所以这台机器压力会最轻。我们来试试把132服务器设置为backup,首先133服务器是正常的情况,然后把133服务器服务停掉。在看看效果,真相的图来了。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132 weight=3 max_fails=3 fail_timeout=20s backup; server 192.168.157.133 weight=2 max_fails=3 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
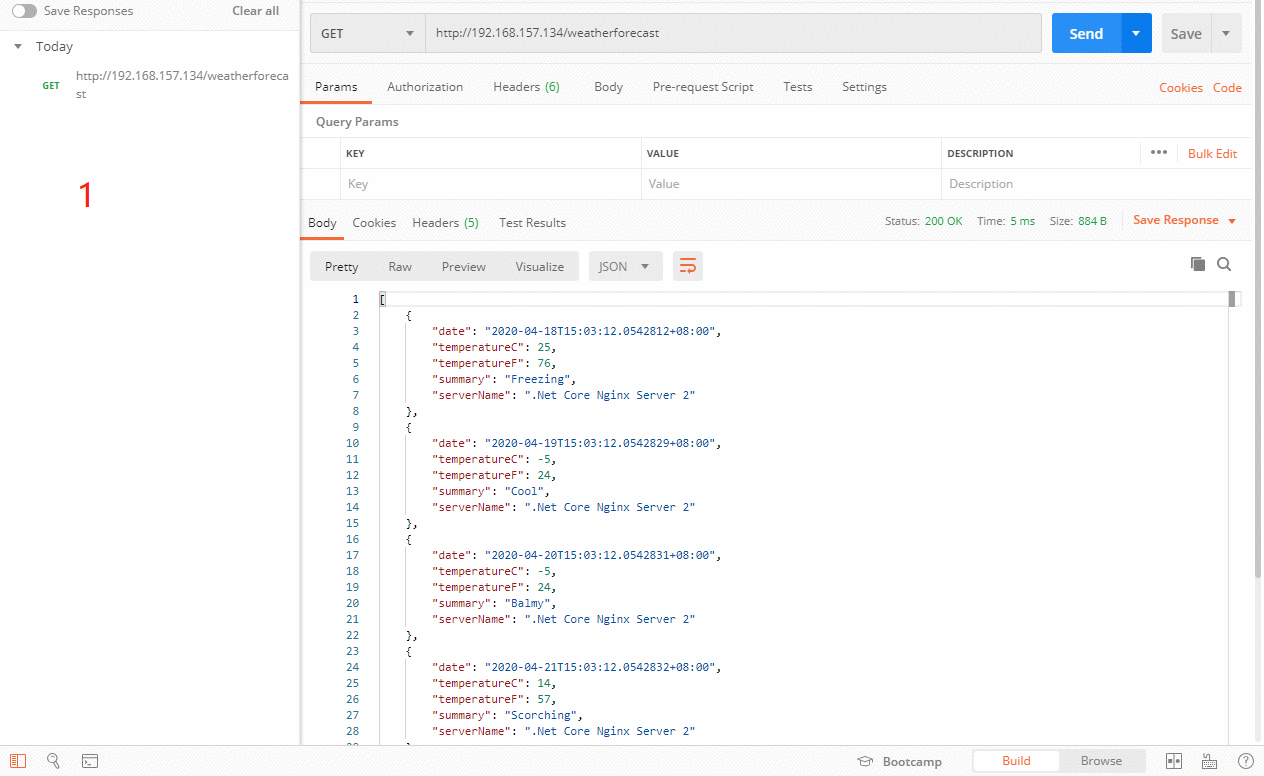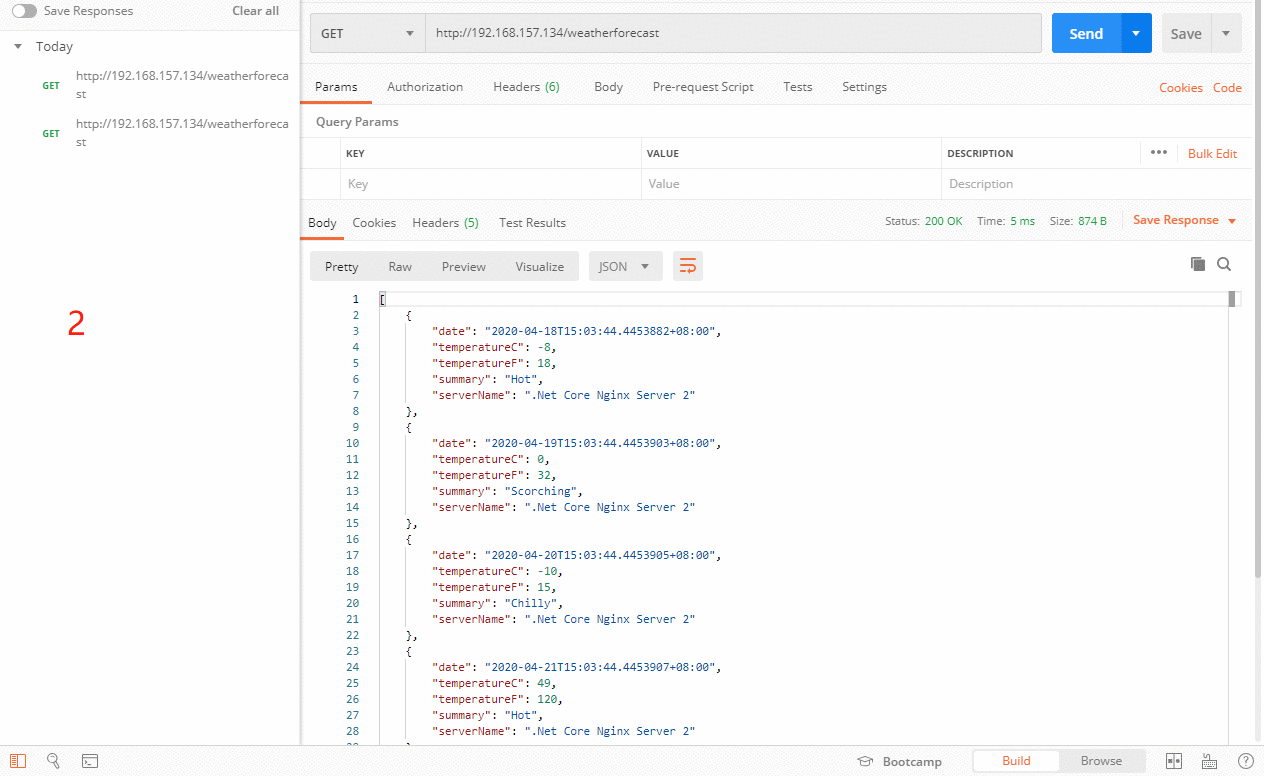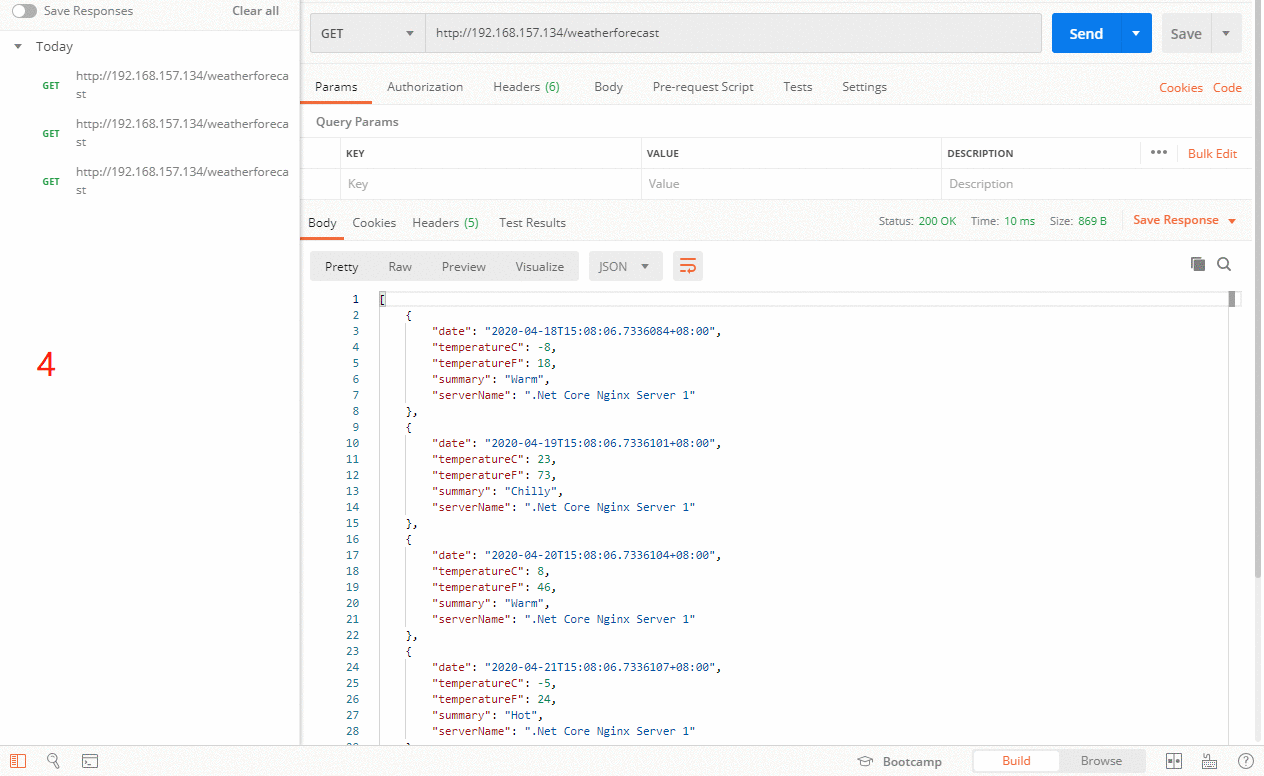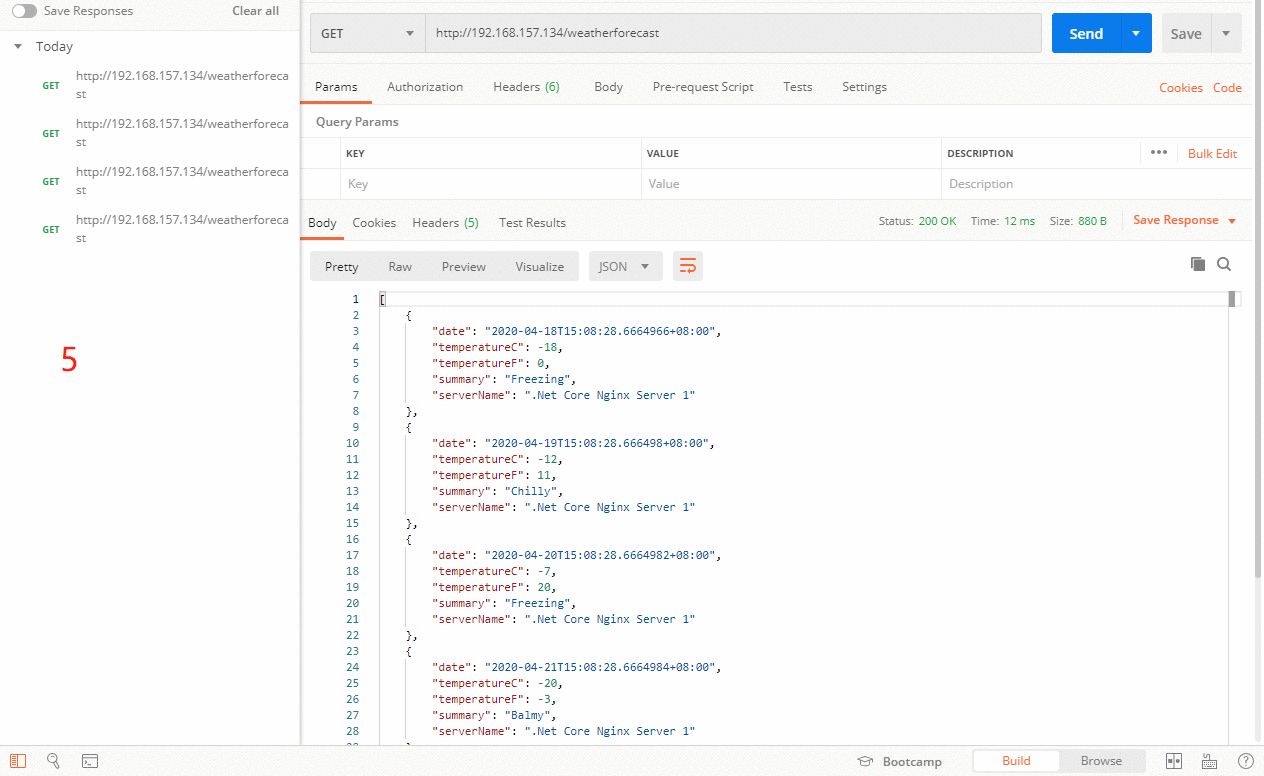
上图一开始133服务器正常的时候,是按照原来正常配置的策略去请求对应的服务器,当133服务器挂了之后,作为backup服务器的132,这个时候就开始干活啦。当133服务器又重启之后,132备份服务器又进入了休息的状态。
在这里留个问题哦,你们可以在部署多一台服务器,同样也配置为bakcup,那么当正常的服务器忙活着挂了之后,Nginx是如何使用backup去分配的呢?这里我就不上图啦,留给你们去验证下具体实践的效果啦。
⑥、down
配置当前服务器不参与负载均衡
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132 weight=3 max_fails=3 fail_timeout=20s down; server 192.168.157.133 weight=2 max_fails=3 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
这个就比较简单,设置为down的服务器直接不参与负载均衡,想要它参与就得重新修改配置文件,然后重启Nginx。我们验证下效果
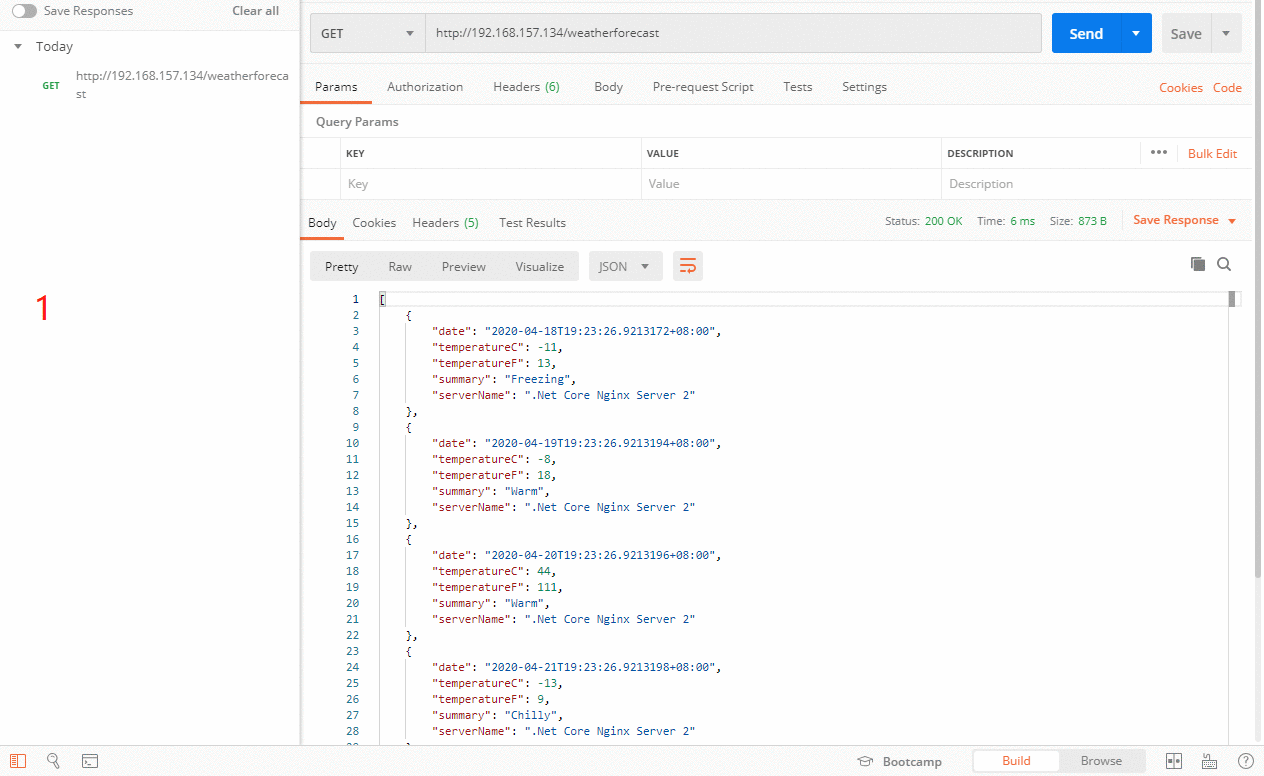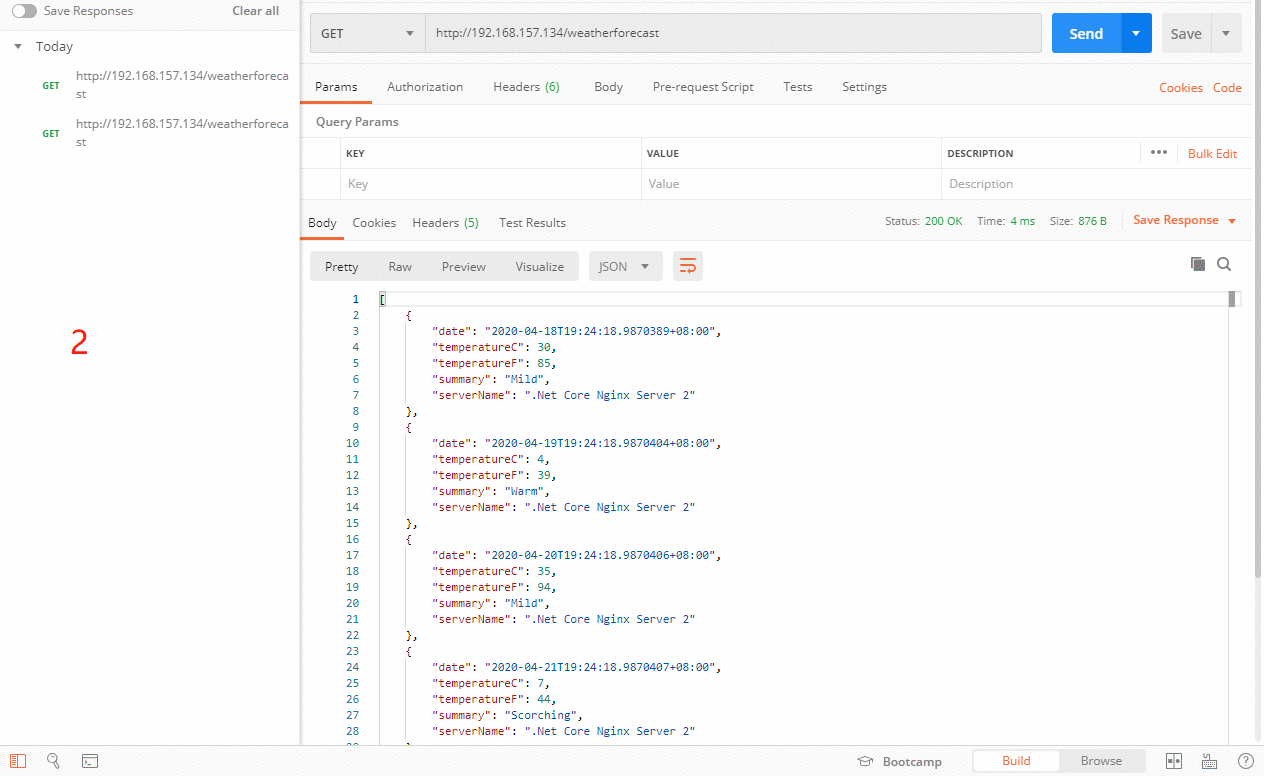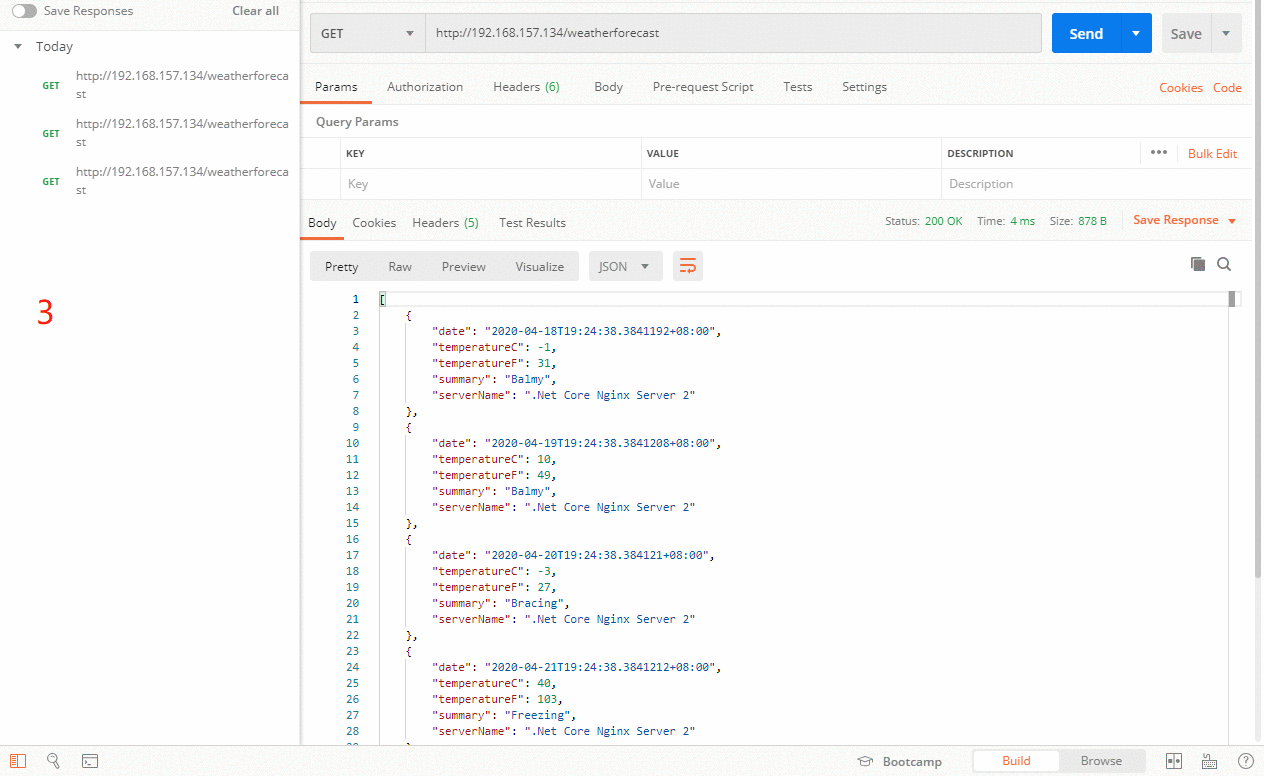
⑦、max_conns
限制同时连接到某台后端服务器的连接数,默认为0即无限制。
那我们怎么去验证这个呢,我们先在原来的.NET Core项目,更改接口,主动让它阻塞,如下图
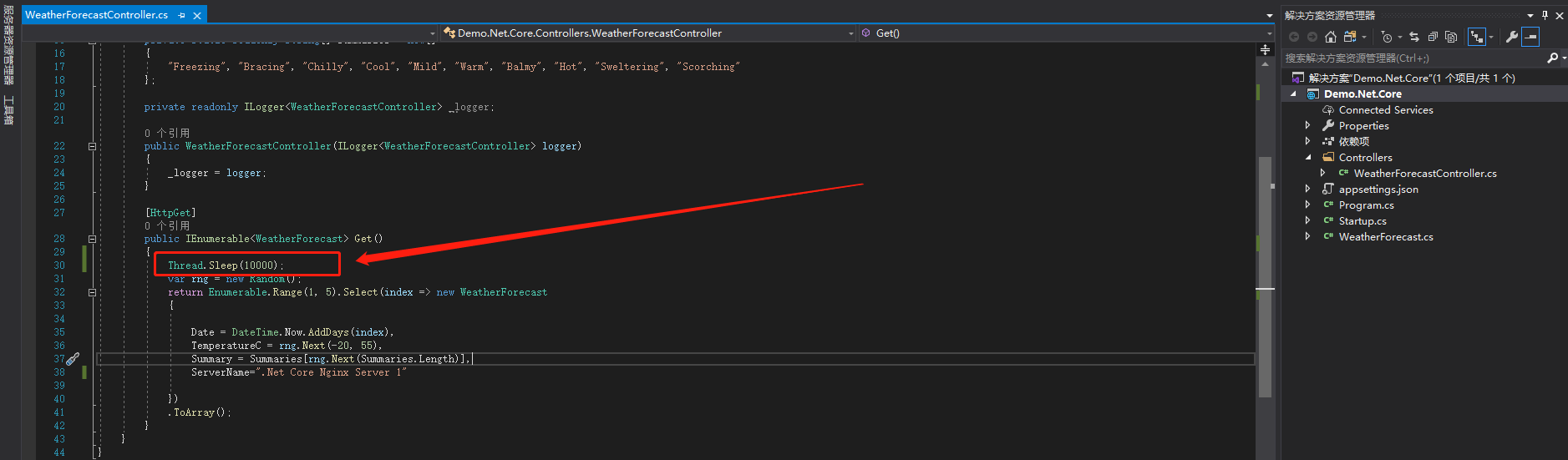
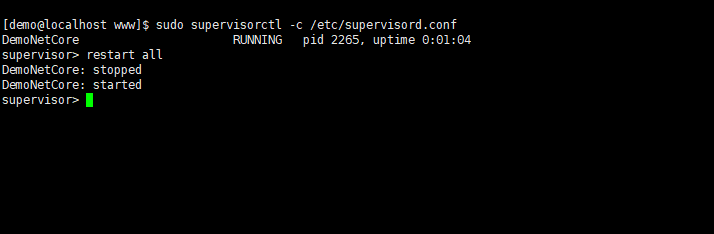
然后把它发布到132的服务器上,发布完之后,我们要重新启动132服务器上的.NET Core服务,这里我们直接重启supervisor进程守护
#启动supervisorctl sudo supervisorctl -c /etc/supervisord.conf #重启 restart all
然后我们在Nginx服务器上更改对应的配置,把132服务器最大同时连接数为1
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { server 192.168.157.132 max_fails=3 fail_timeout=20s max_conns=1; server 192.168.157.133 max_fails=4 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
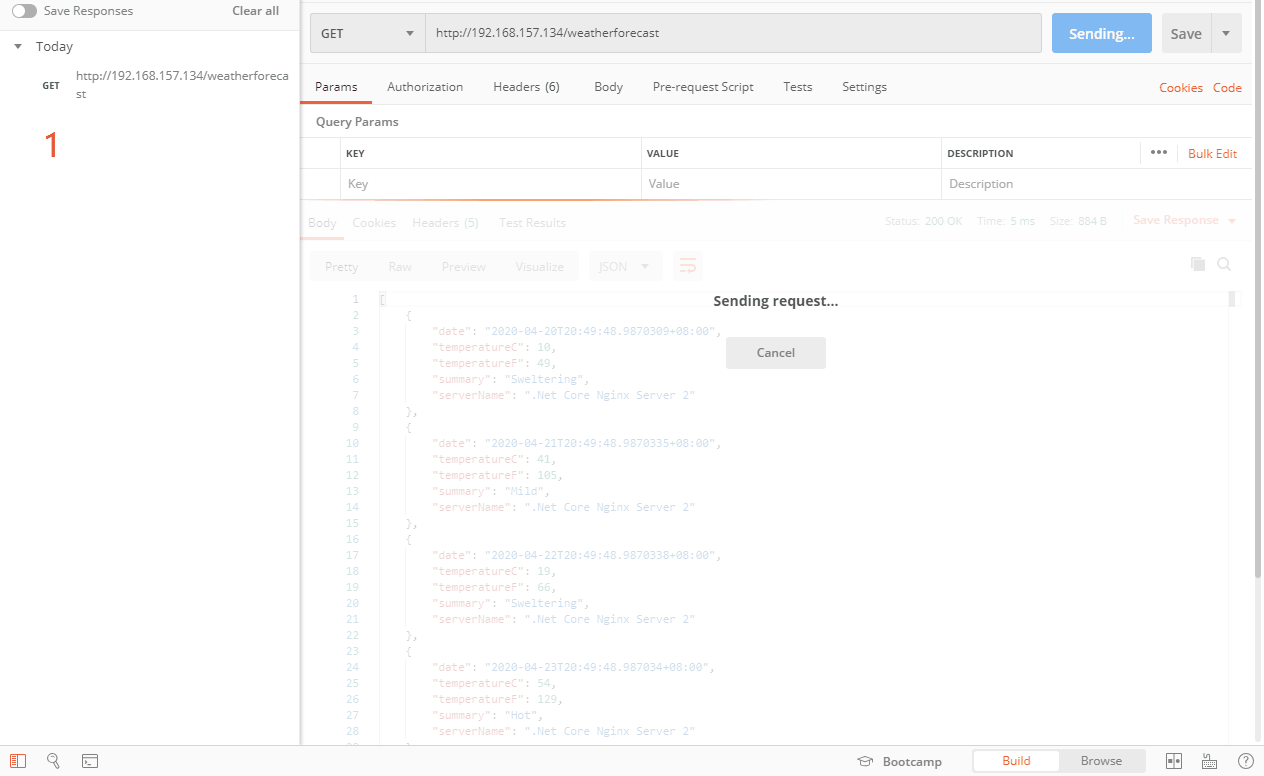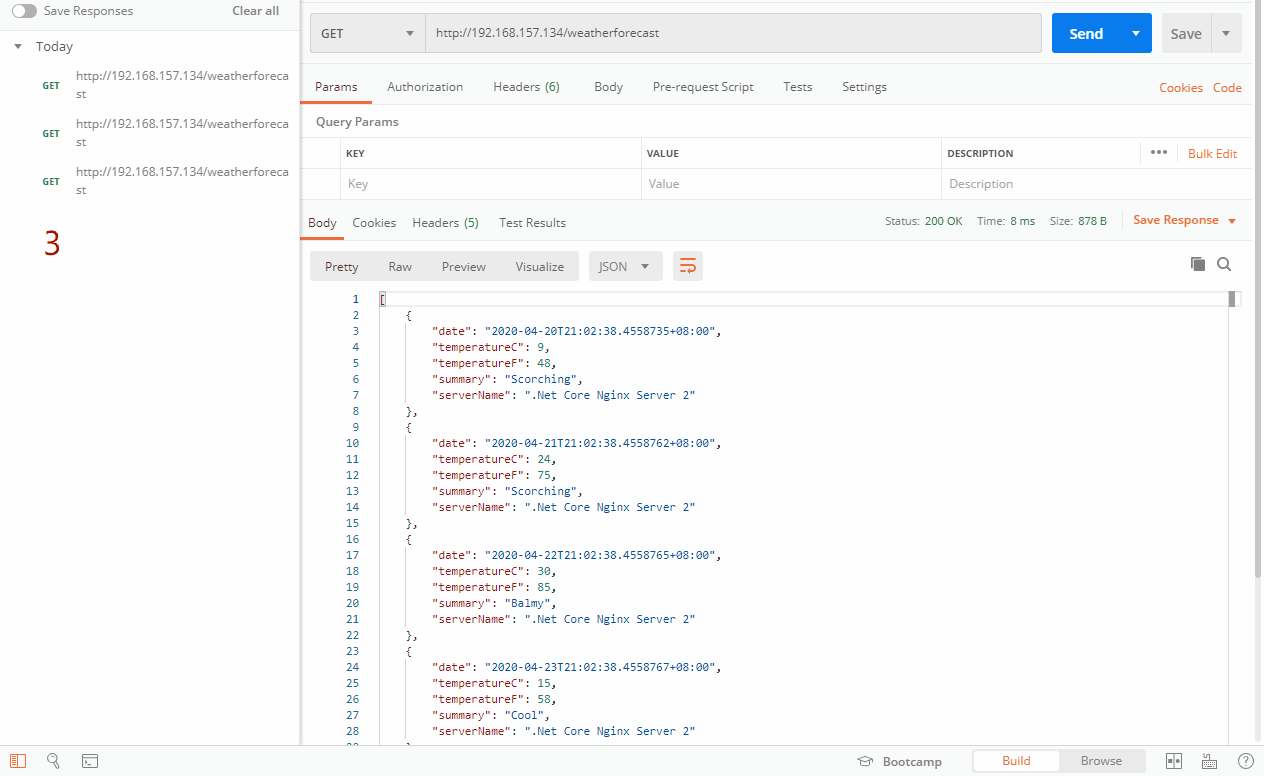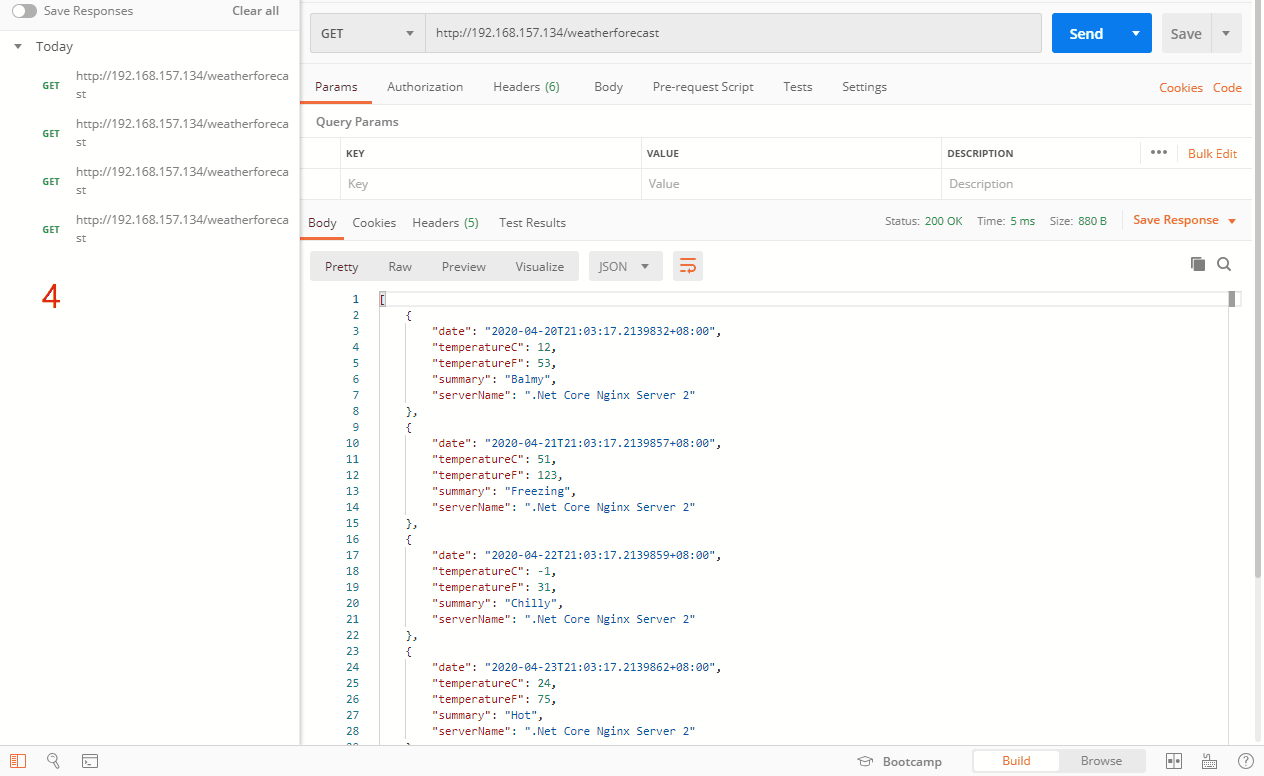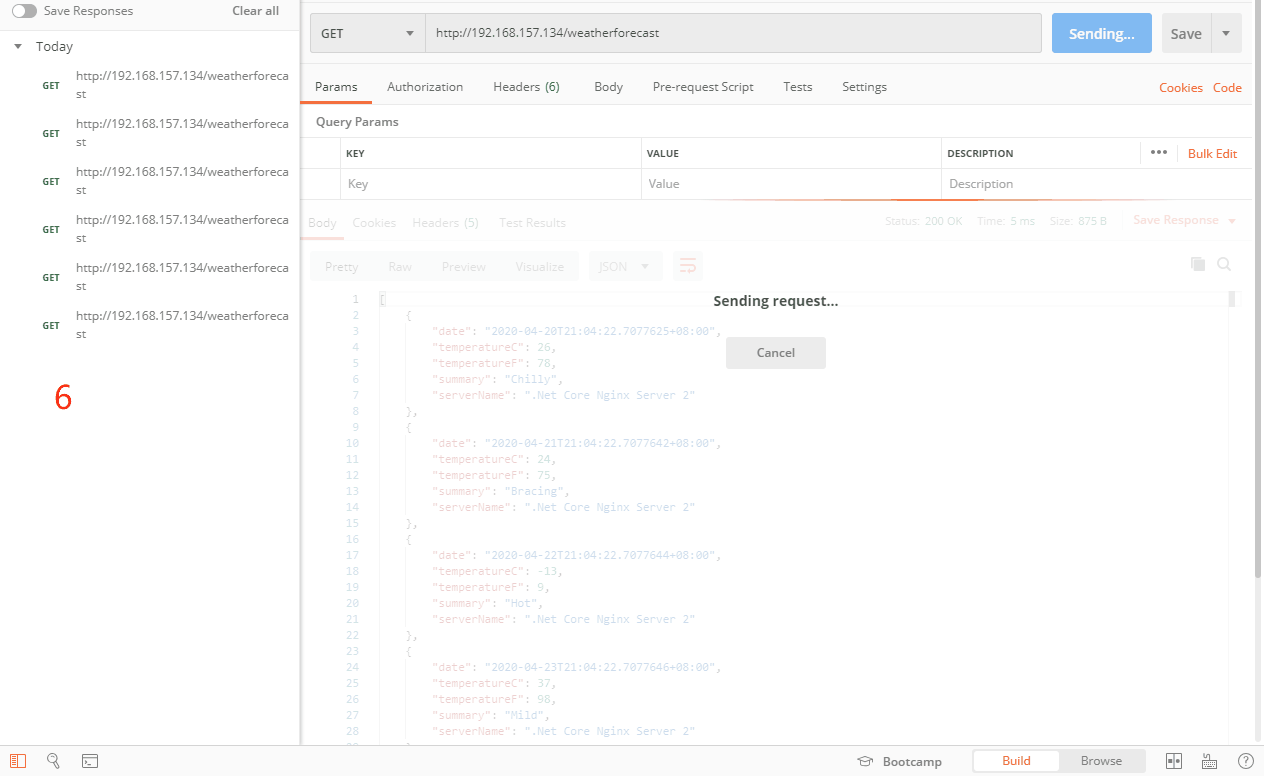
如上图,按正常来说,不同的请求会按照时间顺序轮询到132,133服务器,因为设置了132的max_conns为1,而且我们把132的项目接口阻塞了10秒,当我们第一次访问的时候,请求132服务器,在10秒内还没有完成并返回数据,接着又有一个请求进来,按照轮询,毫无疑问先去133服务器,当第三个请求进来的时候,有轮询到了132服务器,但是因为只允许同时连接数为1,在之前已经有一个请求连接了,还没有释放,所以直接跳过选择132服务器,请求到了133服务器。直到阻塞的那个请求完成后,如图6,又开始请求132服务器了。
2.ip_hash(ip哈希)
每个请求按访问IP的hash结果分配,这样来自同一个IP的访客固定访问一个后端服务器,有效解决了动态网页存在的session共享问题。当然如果这个节点不可用了,会发到下个节点,而此时没有session同步的话就注销掉了。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { ip_hash; server 192.168.157.132 max_fails=3 fail_timeout=20s; server 192.168.157.133 max_fails=4 fail_timeout=20s; server 192.168.157.138 max_fails=4 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
在这里默认的weight都为1,当我们发起请求的时候,会按照请求IP哈希结果分配到了133服务器,同样的访问几次,结果都是一样,中途我们把133服务器关闭之后,请求分配到了138服务器上,直到把133服务器开启之后,才把请求重新分配到原来的133服务器。

在ip_hash策略里,支持weight,max_fails,fail_timeout,down,max_conns。他们之间的关系以及如何互相影响的,我们将会在详细的《Nginx知多少系列之(九)IP哈希(ip hash)策略剖析》文章讲解,敬请关注。注意:当负载调度算法为ip_hash时,后端服务器在负载均衡调度中的状态不能有backup。
3.least_conn(最少连接)
把请求转发给连接数较少的后端服务器。轮询算法是把请求平均的转发给各个后端,使它们的负载大致相同;但是,有些请求占用的时间很长,会导致其所在的后端负载较高。这种情况下,least_conn这种方式就可以达到更好的负载均衡效果。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { least_conn; server 192.168.157.132 max_fails=3 fail_timeout=20s; server 192.168.157.133 max_fails=4 fail_timeout=20s; server 192.168.157.138 max_fails=4 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
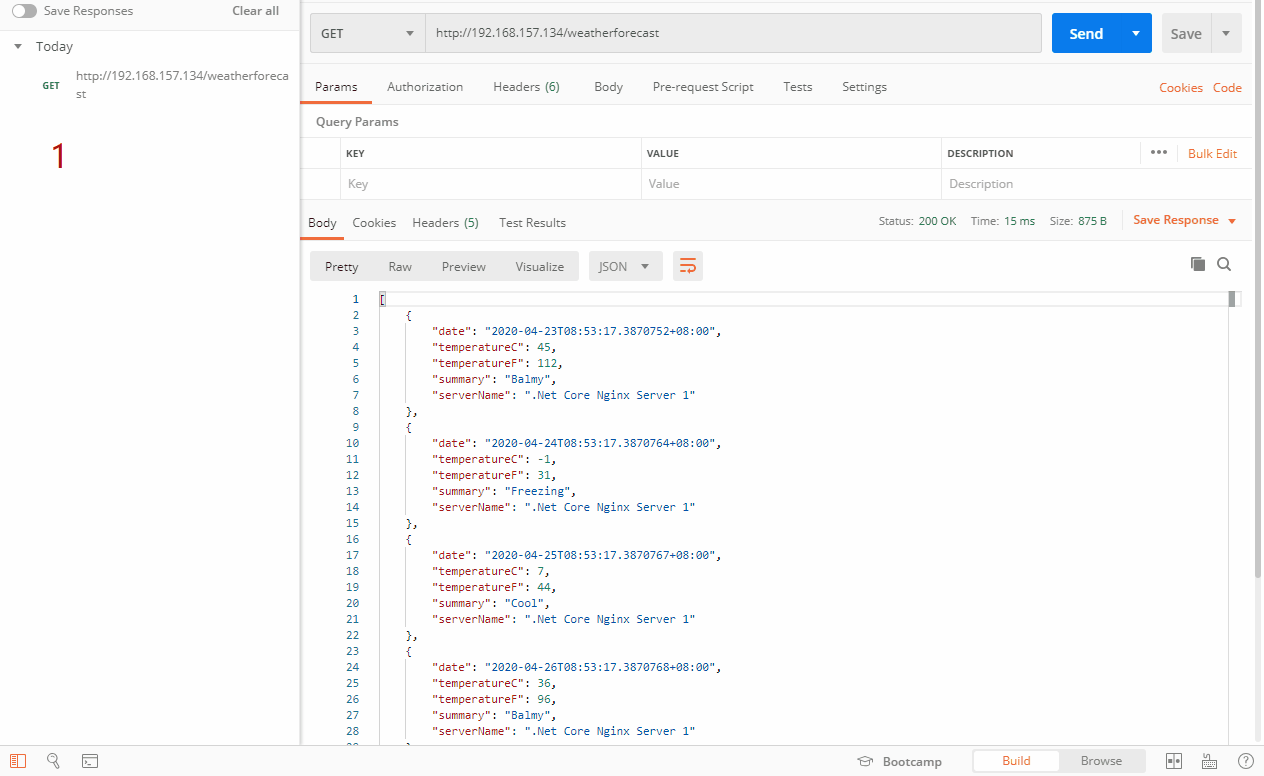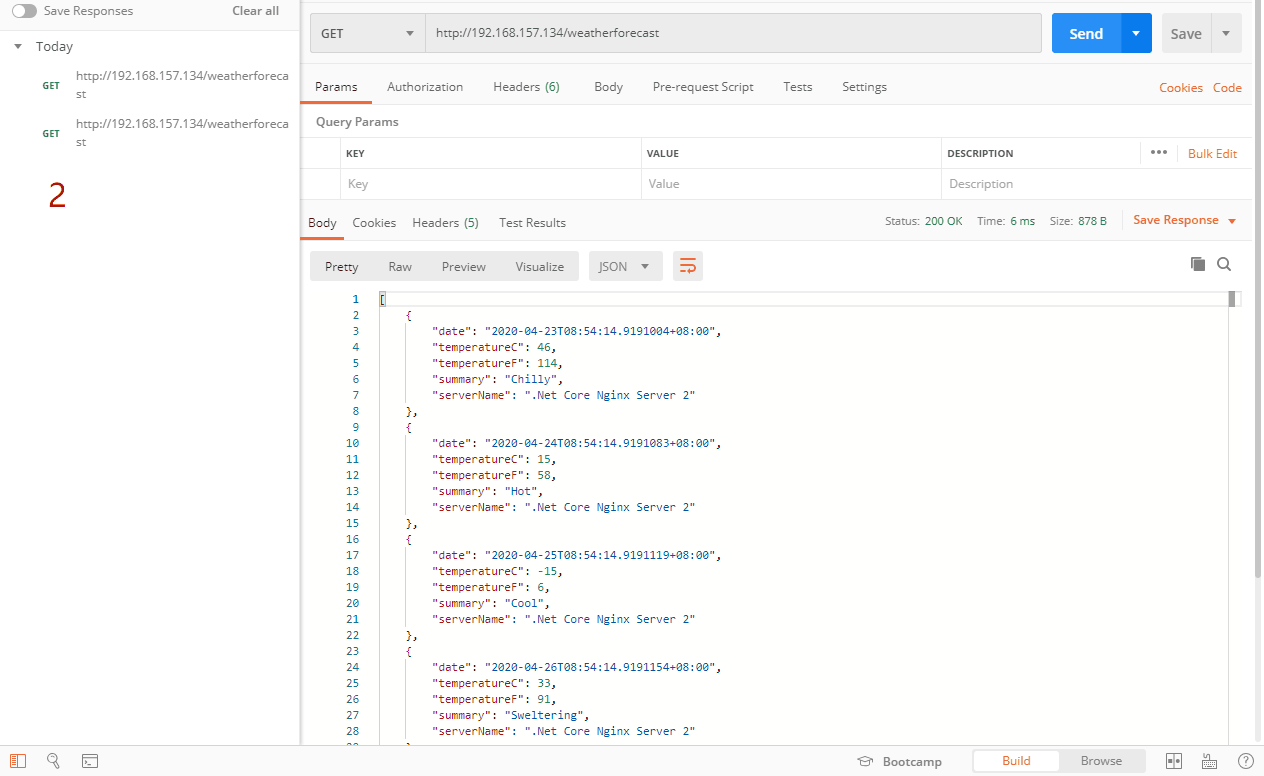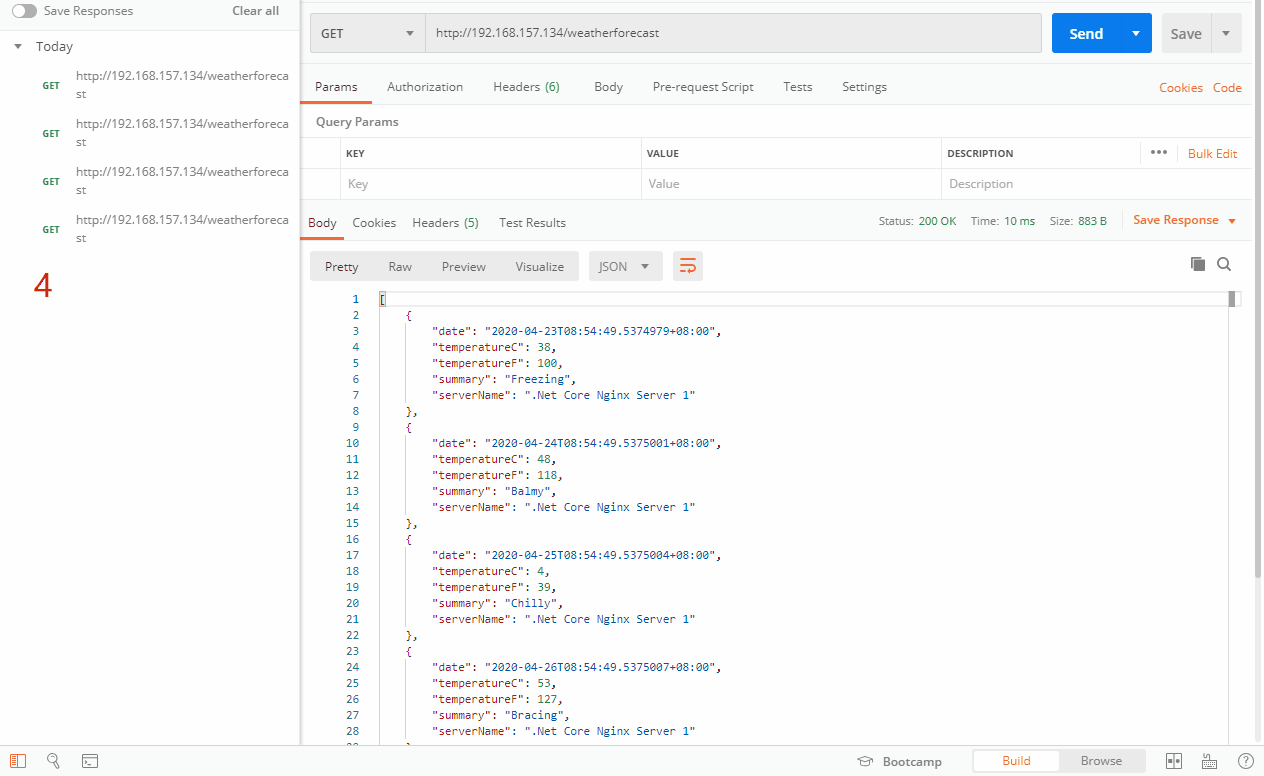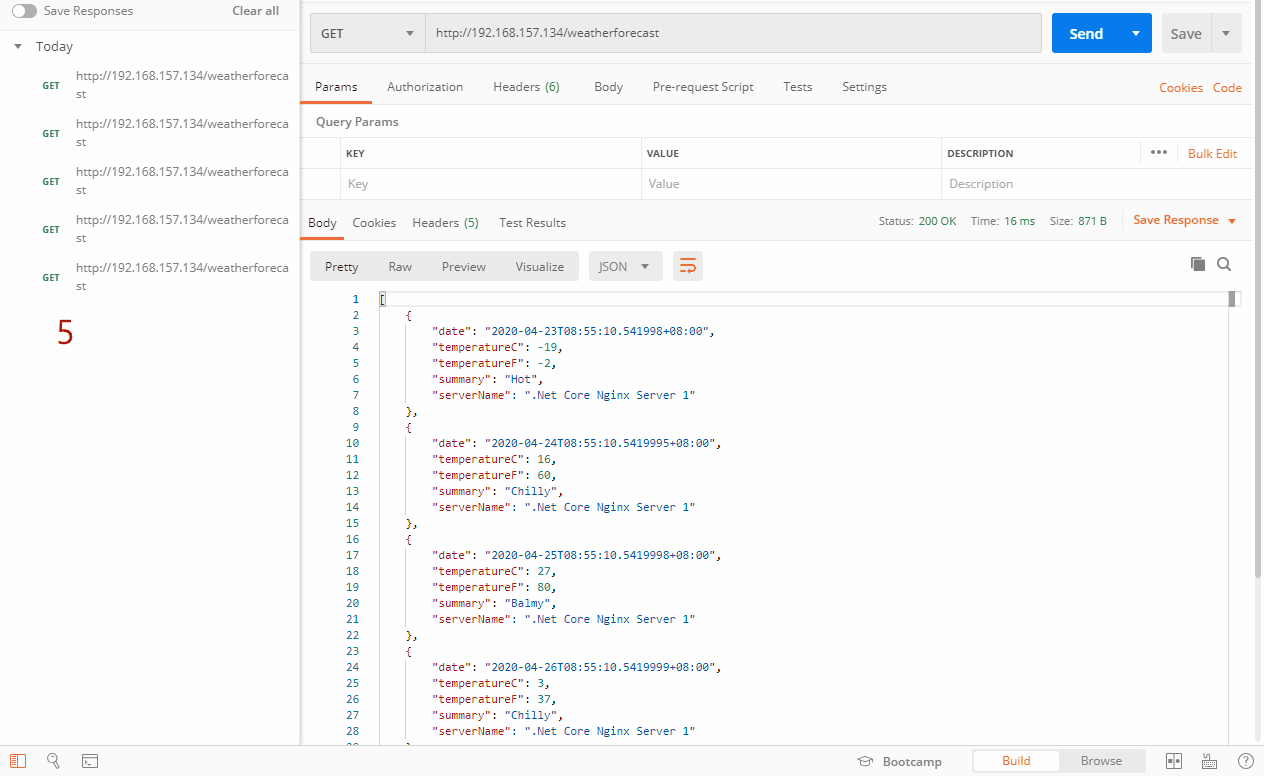
如上图,因为这样测试是测试不出来最少连接的,连接都是为0,这里就要分两种情况,一种是能直接选择连接最少的服务器,第二种是出现多个服务器连接一样的时候,会按照加权轮询的方式去选择服务器。
在least_conn策略里,支持weight,max_fails,fail_timeout,down,max_conns,backup。详细的剖析请看《Nginx知多少系列之(十)最少连接(least_conn)策略剖析》
4.random(随机)
将请求连接发送到随机选择的服务器,同时要考虑weight的值。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { random; server 192.168.157.132 max_fails=3 fail_timeout=20s; server 192.168.157.133 max_fails=4 fail_timeout=20s; server 192.168.157.138 max_fails=4 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
上面的例子是随机从三台服务器里选择一台,当然随机和权重也是有一定关系的。我们来看看效果

随机策略还可以配置随机选择出两台服务器,然后在按照规则去选择其中一台,目前规则只支持least_conn,随机选择两台服务器之后,再按照最少连接选择服务器
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { random two least_conn; server 192.168.157.132 weight=3 max_fails=3 fail_timeout=20s; server 192.168.157.133 max_fails=4 fail_timeout=20s; server 192.168.157.138 max_fails=4 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload
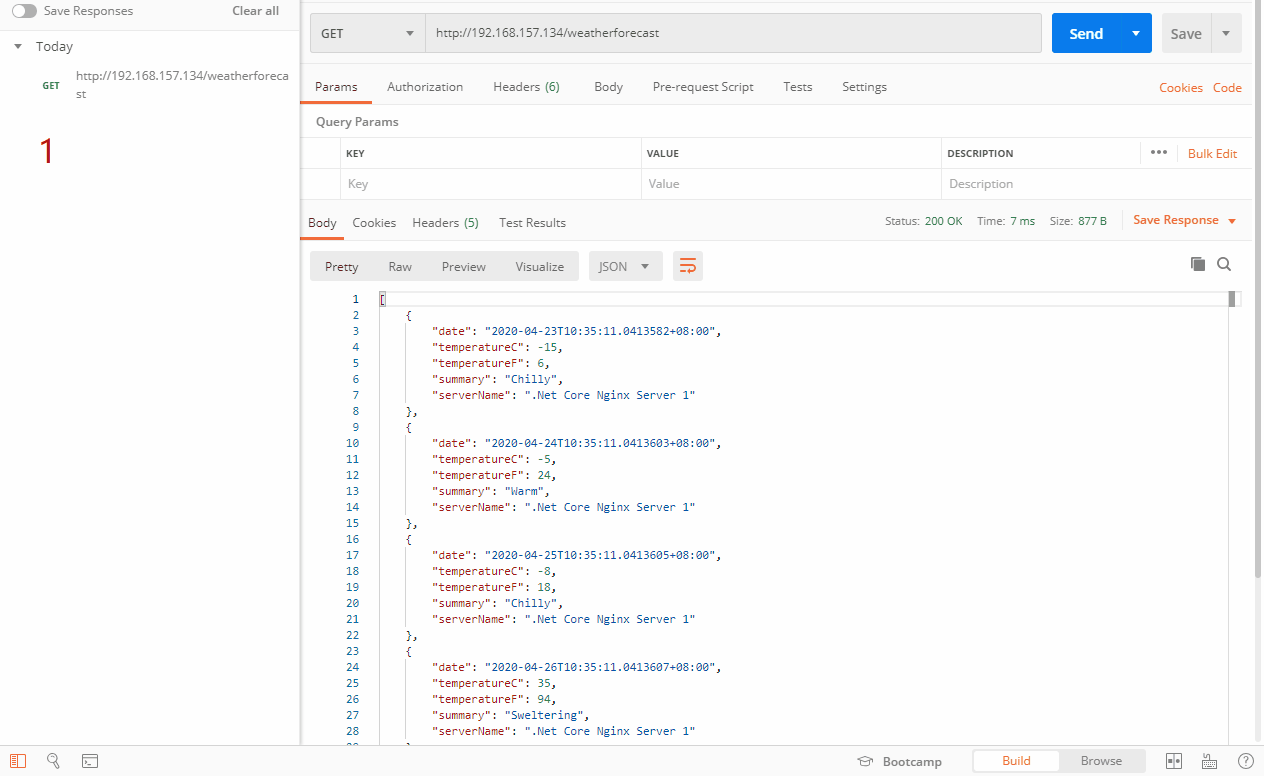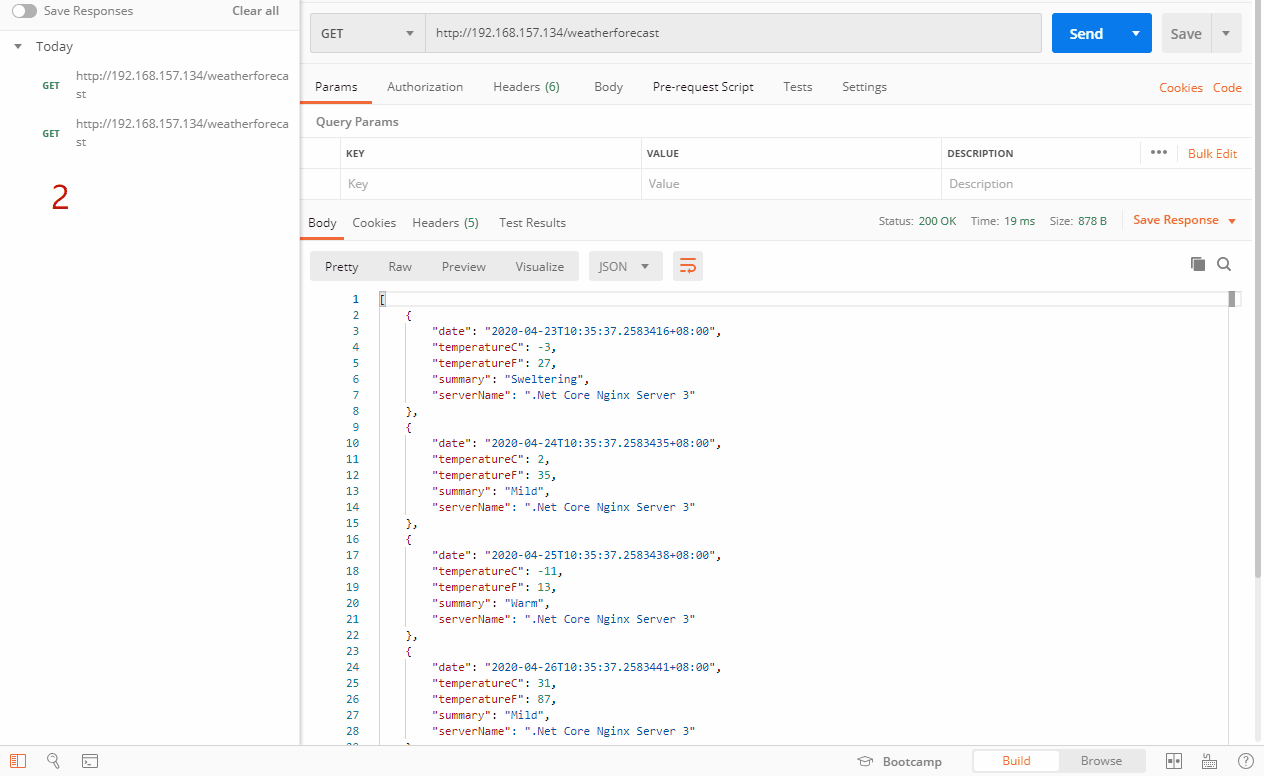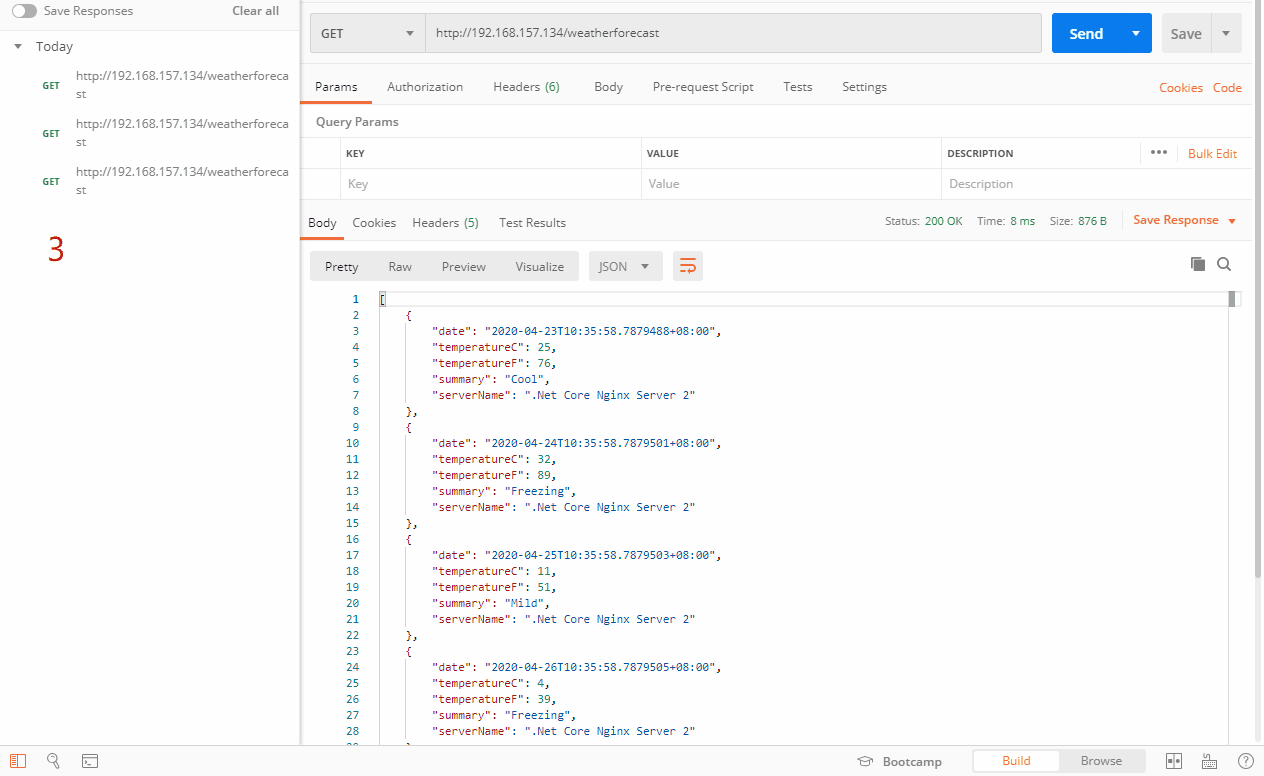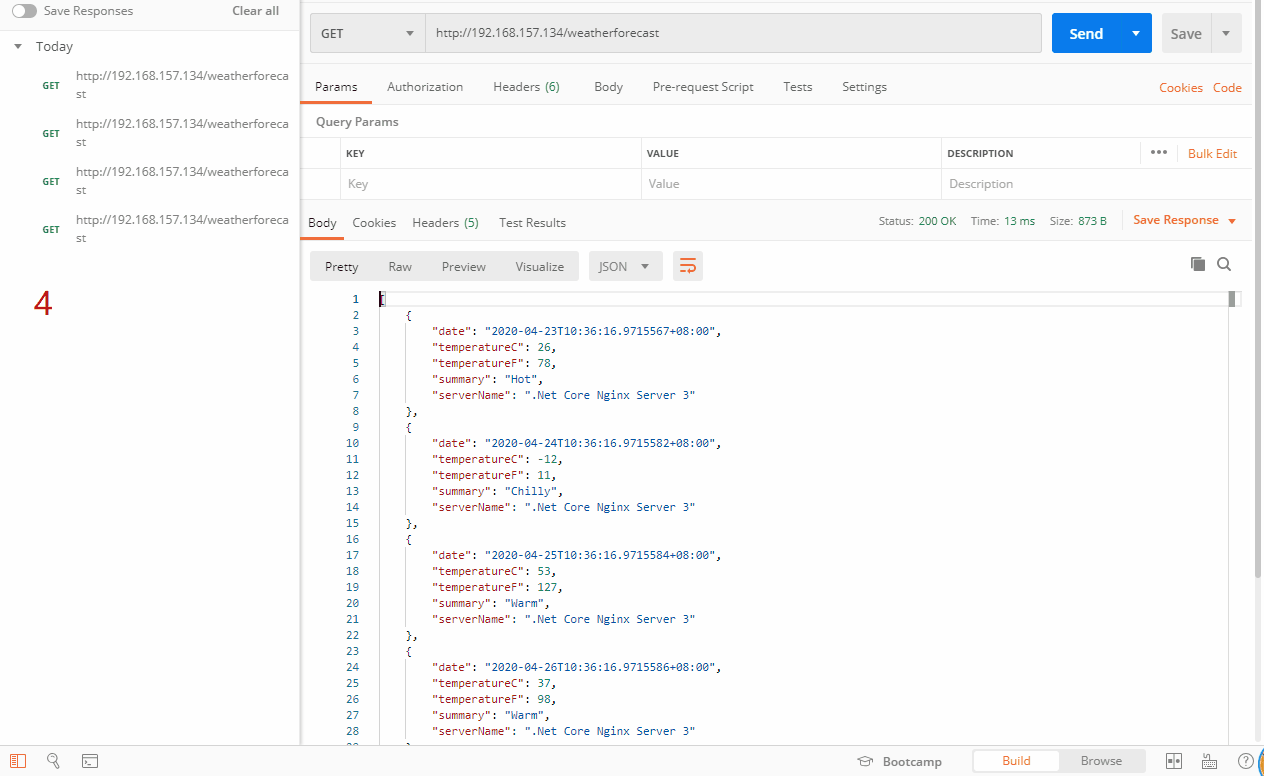
在random策略里,支持weight,max_fails,fail_timeout,down,max_conns。注意:不支持backup。详细的剖析请看《Nginx知多少系列之(十一)随机(random)策略剖析》
5.url_hash(依据URL)
此方法按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。如果使用了consistent参数,则将使用ketama 一致性哈希算法,可确保在将服务器添加到组中或从组中删除服务器时,只有很少的键将被重新映射到不同的服务器。这有助于为缓存服务器实现更高的缓存命中率。
#进入conf.d目录 cd /etc/nginx/conf.d #编辑upstream.conf文件 sudo vim upstream.conf #按i进去插入模式,修改下面内容 upstream netCoreDemo { hash $request_uri consistent; server 192.168.157.132 weight=3 max_fails=3 fail_timeout=20s; server 192.168.157.133 max_fails=4 fail_timeout=20s; server 192.168.157.138 max_fails=4 fail_timeout=20s; } #按Esc,:wq保存退出 #重启Nginx sudo nginx -s reload

在url_hash策略里,支持weight,max_fails,fail_timeout,down,max_conns。注意:不支持backup。详细的剖析请看《Nginx知多少系列之(十二)URL哈希(url hash)策略剖析》
6.fair(响应时间)
因为涉及到如何安装或更新第三方模块,内容比较多,所以单独一篇文章讲解,具体请看《Nginx知多少系列之(十三)响应时间(fair)第三方模块详解》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号