Nginx知多少系列之(四)工作原理
目录
1.前言
2.安装
3.配置文件详解
4.工作原理
5.Linux下托管.NET Core项目
6.Linux下.NET Core项目负载均衡
7.负载均衡策略详解
8.加权轮询(round robin)策略剖析
9.IP哈希(ip hash)策略剖析
10.最少连接(least_conn)策略剖析
11.随机(random)策略剖析
12.URL哈希(url hash)策略剖析
13.响应时间(fair)第三方模块详解
14.Linux下.NET Core项目Nginx+Keepalived高可用(主从模式)
15.Linux下.NET Core项目Nginx+Keepalived高可用(双主模式)
16.Linux下.NET Core项目LVS+Keepalived+Nginx高可用集群
17.构建静态服务器
18.日志分析
19.优化策略
20.总结
1.Nginx的模块
Nginx的模块从结构上分为核心模块、基础模块和第三方模块:
核心模块:HTTP模块、EVENT模块和MAIL模块
基础模块:HTTP Access模块、HTTP FastCGI模块、HTTP Proxy模块和HTTP Rewrite模块,
第三方模块:HTTP Upstream Request Hash模块、Notice模块和HTTP Access Key模块。
用户根据自己的需要开发的模块都属于第三方模块
Nginx的模块从功能上分为如下三类。
Handlers(处理器模块)。此类模块直接处理请求,并进行输出内容和修改headers信息等操作。Handlers处理器模块一般只能有一个。
Filters (过滤器模块)。此类模块主要对其他处理器模块输出的内容进行修改操作,最后由Nginx输出。
Proxies (代理类模块)。此类模块是Nginx的HTTP Upstream之类的模块,这些模块主要与后端一些服务比如FastCGI等进行交互,实现服务代理和负载均衡等功能。
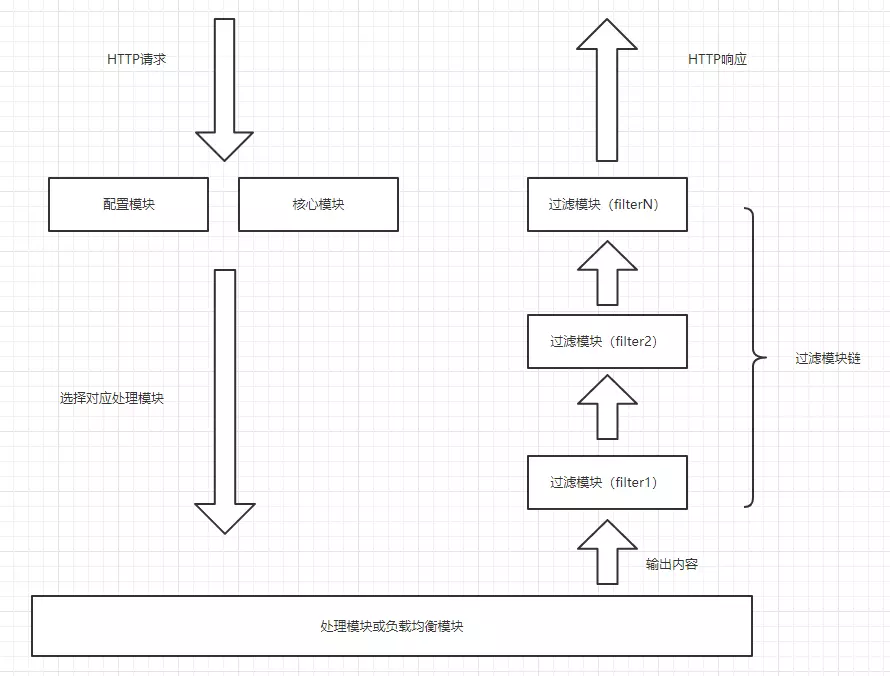
Nginx本身做的工作实际很少,当它接到一个HTTP请求时,它仅仅是通过查找配置文件将此次请求映射到一个location block,而此location中所配置的各个指令则会启动不同的模块去完成工作,因此模块可以看做Nginx真正的劳动工作者。通常一个location中的指令会涉及一个handler模块和多个filter模块(当然,多个location可以复用同一个模块)。handler模块负责处理请求,完成响应内容的生成,而filter模块对响应内容进行处理。
2.Nginx的进程模型
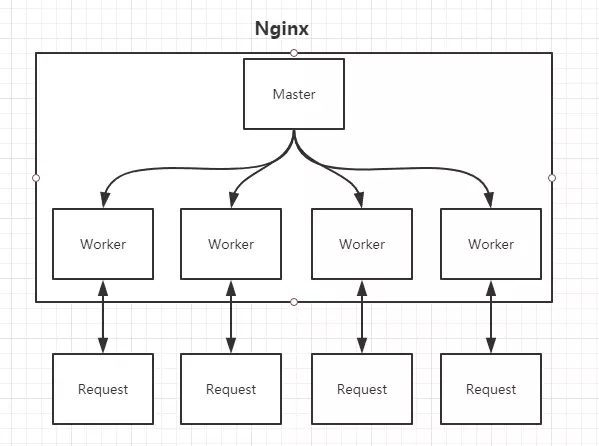
在工作方式上,Nginx分为单工作进程和多工作进程两种模式。在单工作进程模式下,除主进程外,还有一个工作进程,工作进程是单线程的;在多工作进程模式下,每个工作进程包含多个线程。Nginx默认为单工作进程模式。
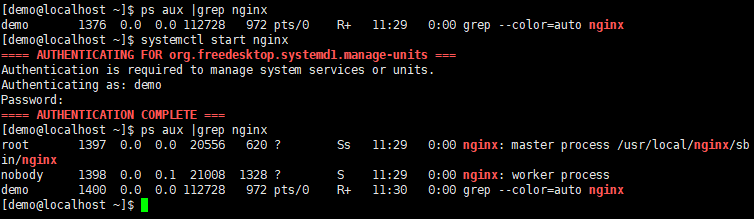
上图我们启动Nginx之后,查看进程,会看到一个master进程和一个worker进程,其中master进程只有一个,工作进程至少一个或以上,这里只有一个因为我们在nginx.conf设置了worker_processes=auto,这样nginx会自动根据核心数为生成对应数量的worker进程。
Master进程:
- 管理 Worker 进程
- 对外接口:接收外部的操作(信号)
- 对内转发:根据外部的操作的不同,通过信号管理 Worker
- 监控:监控 Worker 进程的运行状态,Worker 进程异常终止后,自动重启 Worker 进程
我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。master进程在接收到HUP信号后是怎么做的呢?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。当然,直接给master进程发送信号,这是比较老的操作方式,nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
Worker进程
- Worker 进程都是平等的
- 实际处理:网络请求,由 Worker 进程处理。
- Worker 进程数量:在 nginx.conf 中配置,一般设置为核心数,充分利用 CPU 资源,同时,避免进程数量过多,避免进程竞争 CPU 资源,增加上下文切换的损耗。
当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
3.I/O模型
由于进程是不可直接访问外部设备的,所以只能调用内核去调用外部的设备(上下文切换),然后外部设备比如磁盘,读出存储在设备自身的数据传送给内核缓冲区,内核缓冲区在copy数据到用户进程的缓冲区。在外部设备响应的给到用户进程过程中,包含了两个阶段;由于数据响应方式的不同,所以就有了不同的I/O模型。
①、Blocking I/O 阻塞IO

最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。
当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block状态。
举个栗子:我们去餐厅吃饭的时候,由于人多,服务员写了个排队号给我们,这个时候我们想去逛街,但是又怕刚去逛一会,就轮到我们吃饭了,所以只能坐在那等着叫号,这个过程中我们什么也不做,时间就浪费掉了。
②、Nonblocking I/O 非阻塞IO
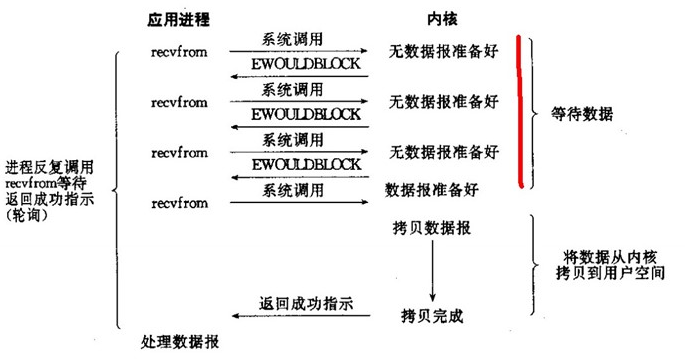
当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
所以事实上,在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。
举个栗子:我们去餐厅吃饭,由于人多,服务员写了个排队号给我们,这个时候我们选择出去逛街,但是我们不敢逛太久,每次逛一会就过来问服务员到我们了没有,来来回回好多次,一直到轮到我们为止。
③、I/O multiplexing (select and poll) 多路复用IO
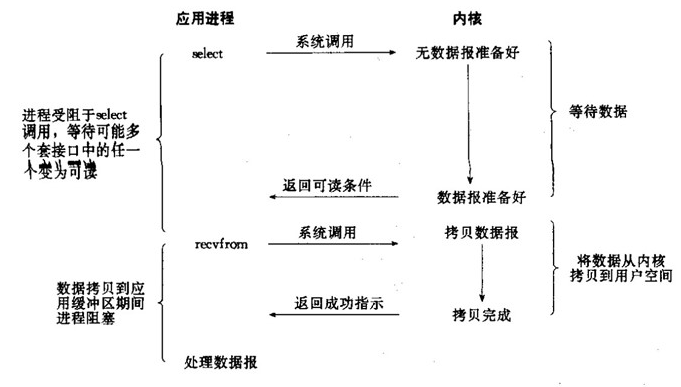
在内核请求IO设备响应指令发出后,数据就开始准备,在此期间用户进程是阻塞的。数据从kernel buffer复制到用户进程的过程也是阻塞的。但是和阻塞I/O所不同的是,它可以同时阻塞多个I/O操作,而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数,也就是说一个线程可以响应多个请求。
举个栗子:我们去餐厅吃饭,由于人多,服务员给我们取了个排队号,同样的我们选择出去逛街,逛一会就回来看当前排队号,但是这个时候我们没有去问服务员,而是餐厅装了电子屏幕,上面显示当前叫号,这样轮到的人直接看电子屏幕就可以了。
④、Signal driven I/O (SIGIO) 信号驱动IO
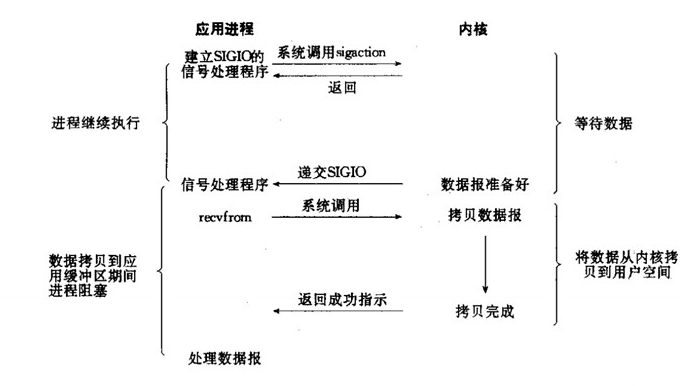
在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
举个栗子:我们去餐厅吃饭,由于人多,服务员给我们取了个排队号,餐厅除了装有电子屏幕之外,还使用了微信通知,只要轮到我们,微信会自动通知已经轮到我们吃饭了,这样我们就可以放心的去逛街,也不需要没逛一会就回来看一看,只需要等待通知就可以了。
⑤、Asynchronous I/O (the POSIX aio_functions) 异步IO
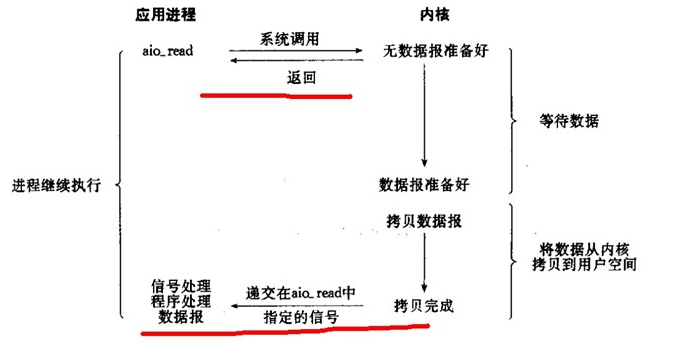
用户进程发起aio_read操作之后,给内核传递描述符、缓冲区指针、缓冲区大小等,告诉内核当整个操作完成时,如何通知进程,然后就立刻去做其他事情了。当内核收到aio_read后,会立刻返回,然后内核开始等待数据准备,数据准备好以后,直接把数据拷贝到用户控件,然后再通知进程本次IO已经完成。
举个栗子:我们怕去餐厅人太多,只想休息下,所以直接叫了个外卖,在家里休息着等送货员送到家里就可以了。
4.Nginx支持高并发原理
Nginx 采用的是多进程(单线程) + 多路IO复用模型,就成了”并发事件驱动“的服务器。
- 基于线程,即一个进程生成多个线程,每个线程响应用户的每个请求。
- 基于事件的模型,一个进程处理多个请求,并且通过epoll机制来通知用户请求完成。
- 基于磁盘的AIO(异步I/O)
- 支持mmap内存映射,mmap传统的web服务器,进行页面输入时,都是将磁盘的页面先输入到内核缓存中,再由内核缓存中复制一份到web服务 器上,mmap机制就是让内核缓存与磁盘进行映射,web服务器,直接复制页面内容即可。不需要先把磁盘的上的页面先输入到内核缓存去。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号