
TP5.1 简单使用QueryList4爬数据(官方有些错误)
先安装
composer require jaeger/querylist
完成后会有jaeger文件
网页布局图
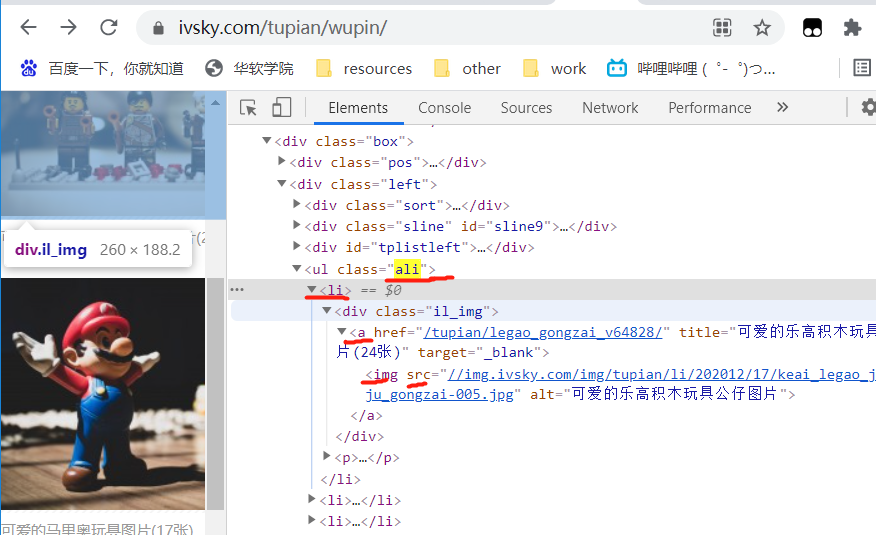
1.单属性查询
use QL\QueryList;
public function test() { $url = 'https://www.ivsky.com/tupian/wupin/index_1.html'; $data = QueryList::get($url)->find('.ali li a img')->attrs('src'); print_r($data->all()); }
效果
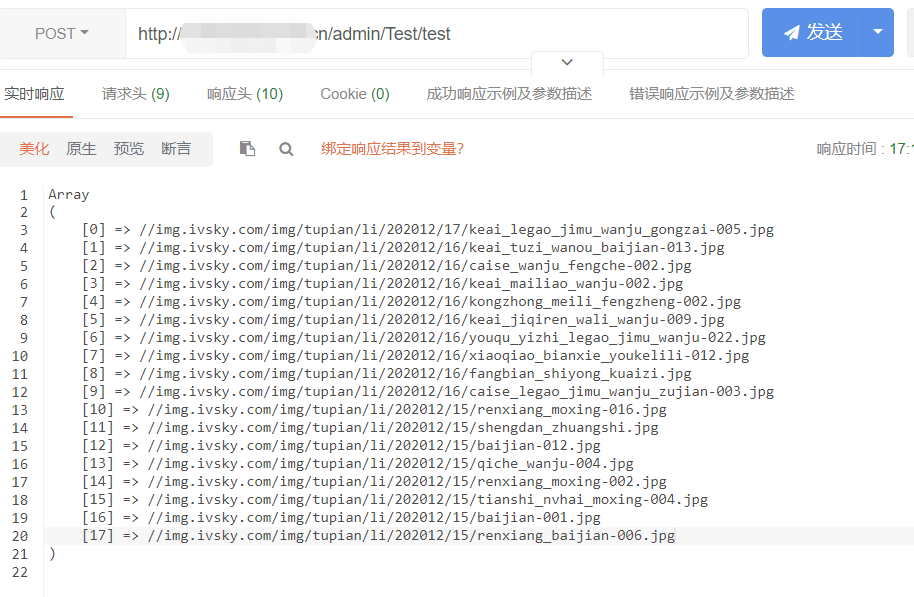
2.多属性查询
public function test() { $url = 'https://www.ivsky.com/tupian/wupin/index_1.html'; $html = file_get_contents($url); //获取某页面所有的代码 $data = QueryList::html($html)->rules([ //设置采集规则 'img' => [' a img', 'src'], 'title' => [' a img', 'alt'] ])->range('.ali li')->removeHead()->queryData(); //range为前缀 print_r($data); }
效果

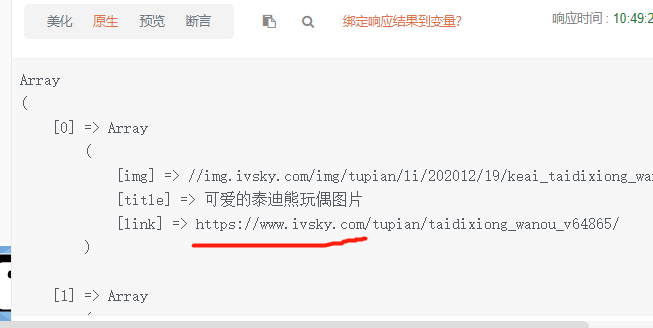
3.回调
public function test() { $url = 'https://www.ivsky.com/tupian/wupin/index_1.html'; $html = $html = file_get_contents("compress.zlib://".$url);//获取某页面所有的代码 $data = QueryList::html($html)->rules([ //设置采集规则 'img' => [' a img', 'src'], 'title' => [' a img', 'alt'], 'link' => ['a ', 'href', '',function($url){ //url为查出的结果 $domain = 'https://www.ivsky.com'; return $domain.$url; //拼接 }] ])->range('.ali li')->queryData(); //range为前缀 print_r($data); }
结果
4.过滤,改官方代码
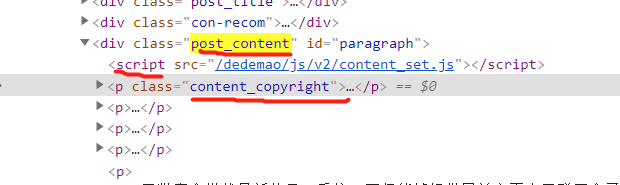
第三个参数格式: -标签 -.类名 -#id
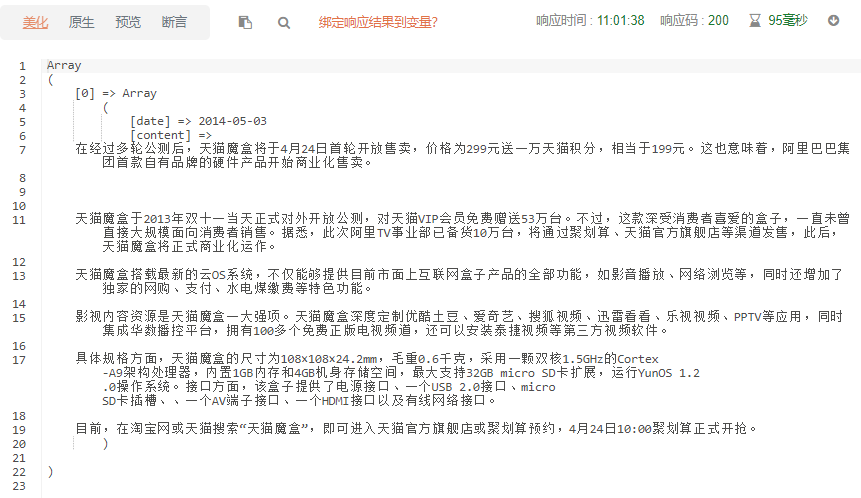
public function test() { $page = 'http://cms.querylist.cc/news/566.html'; $reg = [ //第三个参数 过滤掉span标签和a标签 'date' => ['.pt_info','text','-span -a',function($content){ $arr = explode(' ',$content); //进一步过滤 return $arr[0]; }], //text:只获取文本内容; 第三个参数: 去掉JS标签 版权类 'content' => ['.post_content','text','-script -.content_copyright '] ]; $ql = QueryList::get($page)->rules($reg)->range('.content')->queryData(); print_r($ql); }
结果
5.实战 爬图片存到服务器
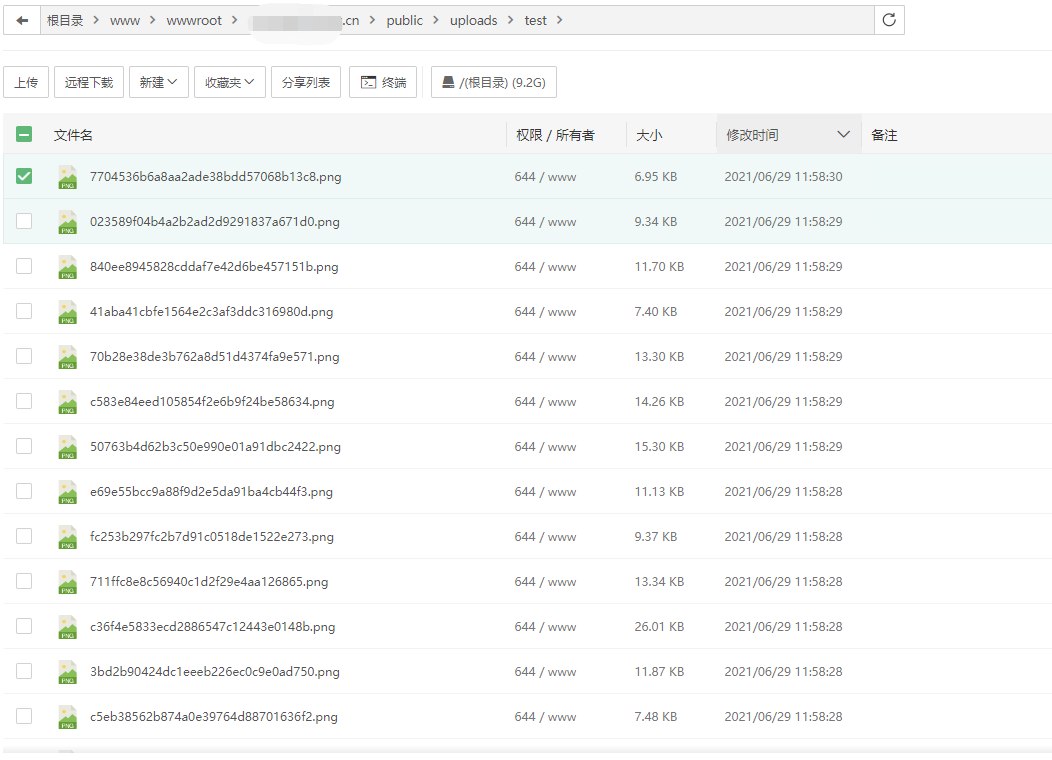
public function test() { $url = 'https://www.ivsky.com/tupian/wupin/index_1.html'; $html = file_get_contents($url); //获取某页面所有的代码 $data = QueryList::html($html)->rules([ //设置采集规则 'img' => [' a img', 'src'], ])->range('.ali li')->queryData(); //range为前缀 foreach ($data as $k => $v) { $url = 'https:' . ($v['img']); // 获取每张图的路径 $local = 'uploads/test/' . md5($url) . '.png'; // 项目public路径 $stream = file_get_contents($url); // 获取字节流 file_put_contents($local, $stream, LOCK_EX); // 保存 } }
结果
爬个b站
$ql = QueryList::use(Baidu::class); $baidu = $ql->baidu(30); // 设置每页搜索15条结果 $searcher = $baidu->search('site:bilibili.com 房东的猫'); $data = $searcher->page(1,true); print_r($data->all());


 浙公网安备 33010602011771号
浙公网安备 33010602011771号