#版本控制发展历史简单了解#Git
版本控制发展历史简单了解
本地版本控制
开发的过程是一个不断迭代的过程,许多人在本地复制整个项目目录的方式来保存不同版本,加上时间之类的以示区别,这么做的唯一好处就是简单,但是也特别容易犯错。
为了解决这个问题,很久以前人们就开发了许多种本地版本控制系统,大多数都是采用某种简单的数据库来记录文件的历次更新差异。
首为代表的就是 RCS,RCS的工作原理是在硬盘上保存补丁集(文件修订前后的变化);通过应用所有的补丁,可以重新计算出各个版本的文件内容。
特点:本地通过补丁集记录文件的变动,应用不同的补丁集,可以计算出各个版本的文件内容。
缺点:无法协同合作,本地丢失,全部丢失。。。
集中化版本控制系统(Centralized Version Control Systems,CVCS)
为了解决本地版本控制的问题,为了满足日益增加的协同工作的需求,诸如CVS、Subversion、Perforce等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,协同工作的人都可以通过客户端连接到这台服务器,取出最新的文件或者提交更新。
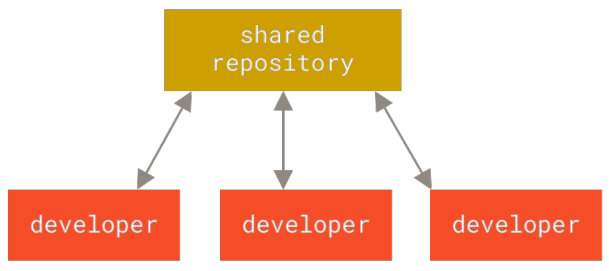
特点:每个人都可以在一定程度上看到其他人在做什么,管理员可以轻松掌握每个开发者的权限,统计集中数据。
缺点:中央服务器宕机,中心数据库所在磁盘损坏等。全员自闭。。。
分布式版本控制系统(Distributed Version Control System,DVCS)
为了解决集中化版本控制系统所面临的问题,于是后来出现了分布式版本控制系统。这类系统中,比较著名的有:Git、Mercurial、Bazaar、Darcs等。 客户端不仅仅只是提取最新版本的文件快照,而是把代码仓库完整地镜像下来,包括了完整的历史记录。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。

Git简介
2005年,分布式版本管理系统BitKeeper收回了作为世界级开源项目Linux免费使用的权利。这迫使以linux缔造者,Linus Torvald为受的Linux开源社区开发出自己的版本管理系统。也就是现在的Git。
Git 被设计的目标要求
- 速度
- 设计简单
- 允许成千上万个并行开发的分支
- 完全分布式
- 有能力胜任超大的数据量
Git与其他分布式系统的区别
Git直接记录快照,而非差异比较
Git 和其他的分布式版本管理系统的最主要差异,在于对待数据的方法不同。其他大部分分系统,以文件变更列表的方式存储信息,通常被称作基于差异 (delta-based)的版本控制。
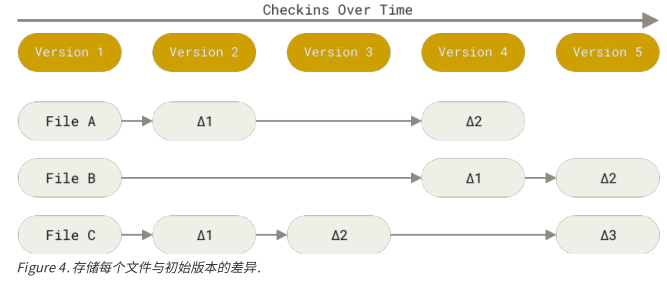
但是Git与几乎所有其他版本控制系统的重要区别,就是Git更像是把数据看作是对小型文件系统的一系列快照。在Git中,没当你提交更新或者保存项目状态时,它基本上就会对当时的全部文件创建一个快照并保存这个文件的快照的索引。为了效率,如果文件没有被修改,Git并不会再重新存储该文件,而是只保留一个链接指向之前存储的文件。Git 对待数据,更像是一个快照流。

Git近乎所有的操作都是本地执行
在Git中的绝大多数操作都只需要访问本地文件和资源,一般不需要来自网络上的其他计算机的信息。这使得Git可以 非常快速。 例如,要浏览项目的历史,Git并不需要外连到服务器去获取历史,然后在显示出来。它只需要从本地数据库中读取。你能立即查看到历史。 如果你想查看当前版本与一个月前的版本之前引入的修改。Git会查找一个月前的问津啊做一次本地的差异计算,而不是由远程服务器处理或者从远程服务器拉回旧版本的文件再来进行本地处理。 这都意味着,你可以在离线的时候或者没有VPN的时候,几乎可以进行任何操作。例如在飞机火车上想做些工作,就能提交到本地副本,直到有网络连接的时候,再进行上传。 这些在其他版本管理系统上几乎不可能或者费力。
(本文节选总结自 《Pro Git》- Scott Chacon and Ben Straub 一书)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号