

消息队列性能对比——ActiveMQ、RabbitMQ与ZeroMQ(译文)
Dissecting Message Queues
概述:
我花了一些时间解剖各种库执行分布式消息。在这个分析中,我看了几个不同的方面,包括API特性,易于部署和维护,以及性能质量.。消息队列已经被分为两组:brokerless和brokered。
brokerless消息队列是对等的,没有中间商参与信息的传递,而brokered队列有一些服务器端点之间。
性能分析的一些系统:
Brokerless
nanomsg
ZeroMQ
Brokered
ActiveMQ
NATS
Kafka
Kestrel
NSQ
RabbitMQ
Redis
ruby-nats
测试环境:
首先,让我们来看看性能指标,因为这可以说是人们最关心的。我已经测量了两个关键指标:吞吐量和延迟。
所有的测试都运行在一台MacBook Pro 2.6 GHz的i7处理器,16GB内存。这些测试是评估一个单一的生产者和单一消费者的发布订阅拓扑结构。这提供了一个很好的基线。这将是有趣的基准缩放拓扑结构,但需要更多的仪器。
开始测试:
1、吞吐量基准:
吞吐量基准是指系统每秒能够处理消息的数量,需要注意的是队列中可能有没有单一的“吞吐量”。我们在两个不同的端点之间发送消息,所以我们观察到的是一个“发送方”吞吐量和一个“接收方”吞吐量,即每秒可以发送的消息数和每秒可以接收的消息数.。
我们这次测试通过发送1,000,000 个1kb 的消息并且计算两边发送和接收消息的时间,这里面选择1kb的数据是因为这种数据更加贴近我们日常开发中遇到的消息请求,许多性能测试倾向于在100到500字节的范围内使用较小的消息.,尽管每个系统都是各不相同的,我们只能够选取大体上相似的测试数据来进行测试。对于面向消息的中间件系统,只使用一个代理。
Brokeless:

从图片我们可以看出,在发送测有很高的吞吐量,然而有趣的是,发送者与接收者的比率差距。
ZeroMQ能够发送超过每秒5000000条消息/每秒但只能收到约600000 /秒。
相反,nanomsg发出害羞的3000000帧/秒可接待近2000000。
Brokered:
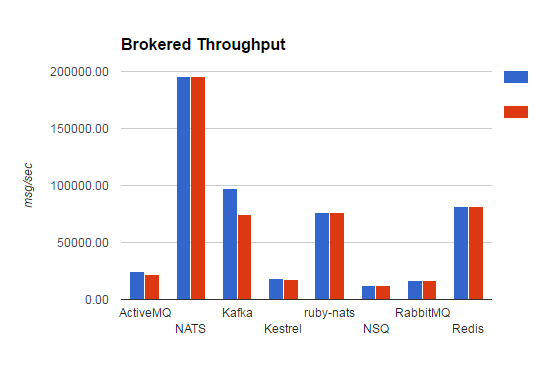
我们可以很直观的观察到,Brokered 消息队列比Brokerless 少了至少两个数量级以上的吞吐量。有一半的Brokered 消息队列吞吐量少于25000条消息每秒。对于Redis的吞吐量或许有一定的误导,尽管Redis 提供 发布/订阅 功能,它并不是真正设计为一个强大的消息队列。以类似的方式使用ZeroMq,Redis切断了慢用户,重要的是要指出,这不是能够可靠地处理这种体积的消息。我们可以将他看成一个特殊点。Kafla 和 ruby-nats 和Redis 有相似的特点,但是能够可靠的处理间歇性故障信息。NATs 在这方面有着优越的吞吐量
通过上述的图示分析,我们可以看到,Brokered 队列在发送和接收两方面有着一致的吞吐量,而不像Brokerless 那样,发送方与接收方的吞吐量有着较大的差异。
2、Latency Benchmarks 延迟基准
第二个关键性能指标是消息延迟,这就测量了在端点之间传输消息需要多长时间。直觉可能告诉我们,这仅仅是吞吐量的逆,即如果吞吐量是消息/秒,延迟是秒/消息。然而,仔细看从ZeroMQ白皮书借这个形象,我们可以看到,这不是个案。
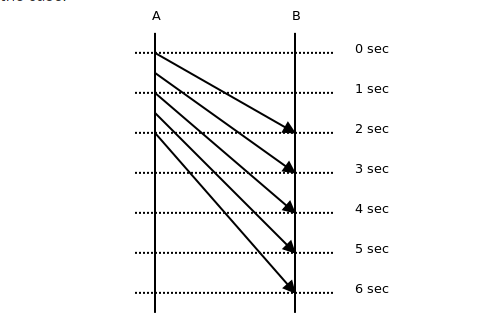
现实情况是,每个消息发送的延迟线是不统一的,它可以为每一个不同的。事实上,延迟和吞吐量之间的关系是有点涉及。
与吞吐量不同的是,延迟的测量并不区分发送方和接收方,而是作为一个整体。但是,由于每个消息都有自己的延迟,我们将看看他们的平均值。进一步,我们将看到平均消息延迟与发送的消息数有关.。直觉告诉我们,更多的信息意味着更多的排队,这意味着更高的延迟。
下图中:
蓝色:nanomsg
红色:ZeroMq

在一般情况下,我们的假设证明正确的,因为更多的消息被发送到系统中,每个消息的延迟增加。有趣的是,当我们接近1000000条消息时,延迟出现的速度变慢了500000点.。另一个有趣的观察是在1000和5000之间的消息延迟的初始峰值,这是更加显着nanomsg。这很难确定因果关系,但是这些变化可能反映了如何在每个库中实现消息批处理和其他网络堆栈遍历优化.。更多的数据点可以提供更好的可视性。
我们看一下Brokered队列和一些有趣的新的类似的模式。
ActiveMq
Kafka
RabbitMq
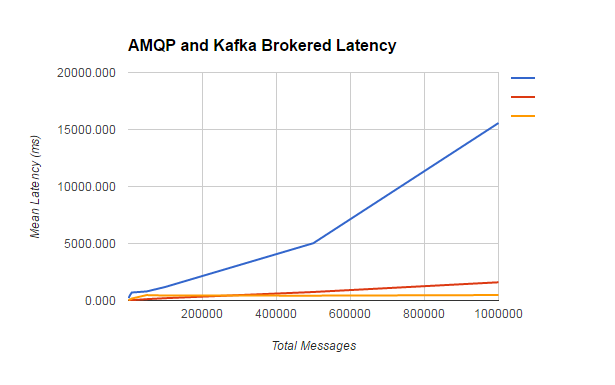
他们的延迟数量级高于其他的Brokered 延迟,因此他们ACtiveMq与RabbitMq分成了自己AMQP范畴。
现在,我们已经看到了一些关于这些不同的库如何执行的经验数据,我将看看他们如何从务实的角度来看工作。消息吞吐量和速度是很重要的,但如果库很难使用、部署或维护,则不太实用.。
ZeroMQ and Nanomsg
从技术上讲,nanomsg不是一个消息队列,而是一个执行socket风格的图书馆分布式消息通过各种便捷的方式。因此,除了在应用程序中嵌入库本身之外,没有什么可以部署的.。这使得部署一个非问题。
Nanomsg是一个由ZeroMQ的作者写的,和我讨论过,在对库的工作以一个非常类似的方式。从发展的角度来看,nanomsg提供全面清洁的API。与ZeroMQ不同,认为不存在一个上下文中,套接字绑定到。此外,nanomsg提供可插拔的运输和通讯协议,使其更加开放的延伸。其额外的内置可扩展性协议也使它相当有吸引力。
像ZeroMQ一样,它保证消息将被原子性地传递完整和有序,但不保证它们的交付。局部的消息将无法交付,并且部分消息可能无法被交付。
ZeroMq 的研发者 Martin Sustrik:很清楚的指出:
Guaranteed delivery is a myth. Nothing is 100% guaranteed. That’s the nature of the world we live in. What we should do instead is to build an internet-like system that is resilient in face of failures and routes around damage.(保证交付是一个神话。没有100%保证。这就是我们生活的世界的性质。我们应该做的是建立一个互联网般的系统,面对失败和路线损坏时弹性。)
ActiveMQ and RabbitMQ
ActiveMQ 和 RabbitMQ 都是AMQP 的一种具体实现。他们扮演着一个保证小心能够正常交付的角色。AcitveMQ 和 RabbitMQ 都支持 持久性或非持久性的信息交付。默认情况下,消息会存储到磁盘中,可以保证消息队列重启时数据的一致,避免消息的丢失。它们还支持同步和异步发送消息,前者对延迟有实质性影响。为了保证交付,这些代理使用消息确认,这也导致巨大的延迟代价。
就可用性和容错性而言,这些代理通过共享存储或无共享支持集群。队列可以跨集群节点进行复制,因此没有单点故障或消息丢失。
AMQP是一个非平凡的协议,其创作者声称过度设计。这些额外的保证是以牺牲主要复杂性和性能折衷为代价的。从根本上说,客户更难实现和使用。
由于它们是消息代理,ActiveMQ和RabbitMQ是需要在分布式系统中管理的额外移动部件,这会带来部署和维护成本。
Redis
最后是Redis。虽然Redis是轻量级消息和临时存储的理想选择,但我不能主张将其用作分布式消息传递系统的主干。它的pub / sub很快,但它的功能有限。它需要大量的工作来建立一个健壮的系统。存在更好地适合于该问题的解决方案,诸如上面描述的那些解决方案,并且还存在一些缩放问题。
除此之外,Redis易于使用,易于部署和管理,并且占用空间相对较小。根据用例,它可以是一个伟大的选择实时消息
附上原博文地址:http://bravenewgeek.com/dissecting-message-queues/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号