
Flume+Kafka+Spark Streaming实现大数据实时流式数据采集
大数据实时流式数据处理是大数据应用中最为常见的场景,与我们的生活也息息相关,以手机流量实时统计来说,它总是能够实时的统计出用户的使用的流量,在第一时间通知用户流量的使用情况,并且最为人性化的为用户提供各种优惠的方案,如果采用离线处理,那么等到用户流量超标了才通知用户,这样会使得用户体验满意度降低,这也是这几年大数据实时流处理的进步,淡然还有很多应用场景。因此Spark Streaming应用而生,不过对于实时我们应该准确理解,需要明白的一点是Spark Streaming不是真正的实时处理,更应该成为准实时,因为它有延迟,而真正的实时处理Storm更为适合,最为典型场景的是淘宝双十一大屏幕上盈利额度统计,在一般实时度要求不太严格的情况下,Spark Streaming+Flume+Kafka是大数据准实时数据采集的最为可靠并且也是最常用的方案,大数据实时流式数据采集的流程图如下所示:
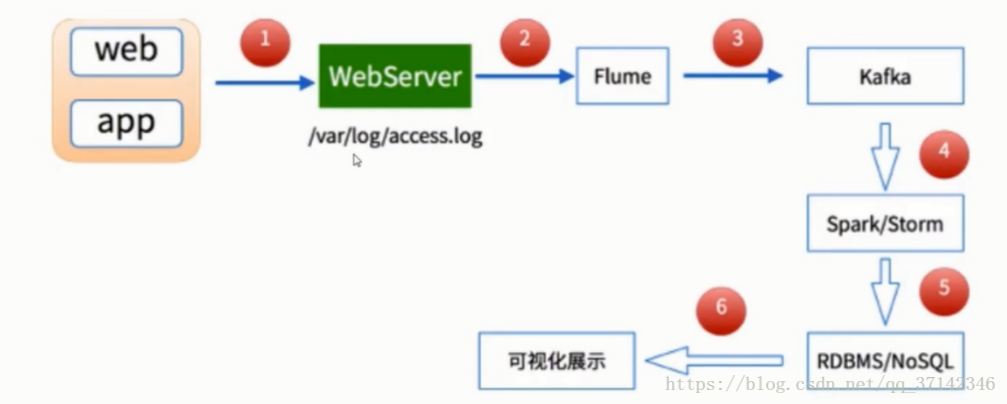
在本篇文章中使用Flume+Kafka+Spark Streaming具体实现大数据实时流式数据采集的架构图如下:

转发请标明原文地址:原文地址
对Flume,Spark Streaming,Kafka的配置如有任何问题请参考笔者前面的文章:
Flume跨服务器采集数据
Spark Streaming集成Kafka的两种方式
Kafka的简单使用以及原理
开发环境、工具:
Linux操作系统,JDK环境,SCALA环境、CDH5版本软件
Spark
Kafka_2.10-0.8.2.1
Flume-1.5.0-cdh5.3.6-bin
Zookeeper-3.4.5
————————————————
版权声明:本文为CSDN博主「不清不慎」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_37142346/article/details/81140618

 浙公网安备 33010602011771号
浙公网安备 33010602011771号