
去哪儿网支付系统架构演进(下篇)
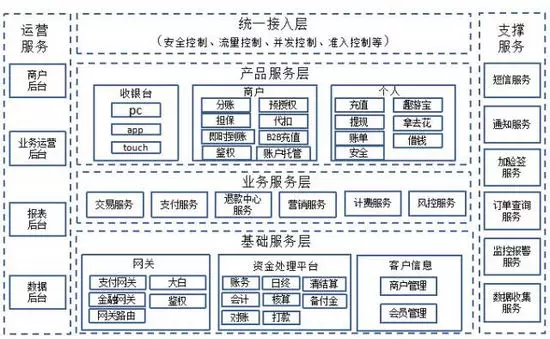
上篇给大家介绍了去哪儿支付系统架构演进的服务化拆分(点击阅读原文可查看上篇内容),接下来介绍一下在服务化拆分过程中遇到的一些问题与挑战,拆分过程中的DB处理、异步化,监控&报警等内容。
2.2 服务化拆分带来的挑战
服务化拆分后,在系统结构上更加清晰了,但对于整体系统的开发管理和日常运营带来更大的挑战。比如下几个方面:
2.2.1 如何提高开发效率
系统拆分后主要提供dubbo服务和对外http(https)服务
1. 针对Dubbo服务的约定
接口定义:粒度控制、边界控制。一个接口不能存在模棱两可的情况,只做其一
参数标准:复杂接口使用对象做参数(避免map)、统一父类、支持扩展属性透传、提供create/builder构造合法参数、使用枚举限制参数范围。有效避免调用端参数错传
返回值:统一QResponse封装、错误码管理(非数字形式含义明确、按业务区分避免重复等)
业务模板:定义标准业务处理流程、标准化异常处理
接口文档化:定义好接口后,通过注解动态生成接口文档
2. 针对http服务的约定
a)接口参数:command、校验器、参数类型配置化。
command中定义接口信息,包括请求返回参数、每个参数的参数类型、参数的校验器、参数类型的校验器。校验器可以组合使用,也可以自定义实现扩展。如下示例:
Command定义:
汇率查询接口
20150808
查询本币和目标币种汇率
本币true
目标币种true
卖出价true
购买价true
汇率时间true
校验器:^[A-Z]{3}$
参数类型:商户号
用来区分不同商户
java.lang.String
testbgd
^[A-Za-z0-9]{1,20}$
b)并发控制
在某些操作场景下,对于并发写会有一些问题,此时可以通过依赖cache加锁来控制。比如通过在接口增加注解来启用。可以指定接口参数来作为锁的lockKey ,指定锁失效时间和重试次数,并指定异常时(lockGotExIgnore )的处理方案。
@RequestLock(lockKeyPrefix = "combdaikoupay:",
lockKey = "${parentMerchantCode}_${parentTradeNo}",
lockKeyParamMustExists = true,
lockKeyExpireSecs = 5,
lockUsedRetryTimes = 0,
lockUsedRetryLockIntervalMills = 500,
lockGotExIgnore = false)
c)流量控制
流控目前分两种:qps、并行数。
qps分为节点、集群、接口节点、接口集群。通过对每秒中的请求计数进行控制,大于预设阀值(可动态调整)则拒绝访问同时减少计数,否则通过不减少计数。
行数主要是为了解决请求横跨多秒的情况。此时qps满足条件但整体的访问量在递增,对系统的吞吐量造成影响。大于预设阀值(可动态调整)则拒绝访问。每次请求结束减少计数
d)安全校验
接口权限:对接口的访问权限进行统一管理和验证,粒度控制到访问者、被访问系统、接口、版本号
接口签名:避免接口参数在传递过程中发生串改
e)统一监控
包括接口计数、响应时长和错误码统计三个维度
f)接口文档化
依赖前面command、校验器、参数类型配置进行解析生成
2.2.2 如何管理多个系统?
接口监控模板化:http、Dubbo多系统统一模板,集中展示管理。
组件可监控化:Redis/Memcache、Mybatis 、Lock 、QMQ 、 EventBus 、DataSource 、JobScheduler
监控面板自动化生成:Python自动化生成脚本,新创建系统只需要提供系统名称和面板配置节点即可生成标准监控面板
系统硬件资源、tomcat、业务关键指标可视化监控

2.2.3 如何高效日常运营?
对于各个场景的关键流程进行格式化日志输出,集中收集处理。如orderLog、userLog、cardLog、binlog、busilog、tracelog、pagelog...

2.3 服务化拆分过程中DB处理
2.3.1 分表
随着业务量增加,单表数据量过大,操作压力大。因此分表势在必行。常用的分表策略如按照时间来分表,如月表,季表,按照某个key来hash分表,也可以将两种结合起来使用。分表的好处是可方便将历史数据进行迁移,减少在线数据量,分散单表压力。
2.3.2 分库、多实例
多库单实例,多业务单库。部分业务存在问题会影响全局,从而会拖垮整个集群。因此在业务系统拆分后,db的拆分也是重要的一个环节。举一个例支付库拆分的例子。支付交易的表都在同一个库中,由于磁盘容量问题和业务已经拆分,因此决定进行拆库。稳妥起见,我们采用保守方案,先对目前实例做一个从库,然后给需要拆分出来的库创建一个新的用户U,切换时先收回U的写权限,然后等待主从同步完成,,确定相关表没有写入后将U切到新的实例上。然后删除各自库中无关的表。
2.3.3 读写分离、读负载均衡
很多业务读多写少,使用MMM结构,基本上只有一台在工作,不仅资源闲置且不利于整体集群的稳定性。引入读写分离、读负责均衡策略。有效使用硬件资源,且降低每台服务器压力。
a)读写负载均衡

b)多动态源

c)多库动态源读负载均衡

2.4 异步化使用
servlet3异步:释放出http线程提高系统整体吞吐量,可隔离开不同业务的工作线程
qmq:使用最广泛也更灵活的异步
dubbo:对于服务提供者响应比较慢的情况
servlet异步和qmq结合的场景如下图所示。流程为http服务接到组合扣款请求,然后向后端交易系统下单并发起扣款,此时http服务进入轮询等待,根据轮询间隔定时发起对放在cache中的扣款结果查询。交易系统则根据扣款规则以qmq的方式驱动扣款,直至走完所有流程为止(成功,失败,部分支付)。每次扣款结束将结果放入cache中供http服务查询。

轮询式场景如上图中使用,关键在于确定轮询间隔

2.5 监控&报警
2.5.1 Java监控模块
嵌入在应用中,指标数据可灵活配置发送方式到多个地方。也支持api接口直接拉取数据

2.5.2 离线监控框架
python监控脚本框架,从db、java模块api、redis等获取数据,计算指标并发送
整体架构可插件化、有通用标准功能、也可定制化开发
指标可直接推送至watcher(dashboard)系统添加监控页
报警方式有mail、sms、qtalk
python监控脚本框架主要包含四个重要组件:
metric_manager:指标管理器
graphite_sender:指标推送
Dbpool:数据库链接池管理
Scheduler:调度器,定时执行指标数据获取
2.5.3 数据流系统
采用xflume、kafka、storm、hdfs、hbase、redis、hive对业务日志、binlog等实时收集并处理。提供业务日志、订单生命周期日志、各种格式化日志的查询和一些监控指标的计算存储和报警。整体大致流程如下图所示:

2.5.4 报警
业务和系统结构复杂后报警尤为重要。甄别哪些指标是必须报警的和报警阀值的确定是个很复杂的问题。一般有两种情况:一种是明确认为不能出现的,另一种是需要一定计算来决定是否要报警。当然有些基础层的服务出现问题,可能会导致连锁反应,那么如何甄别最直接的问题来报警,避免乱报影响判断是比较难的事情。目前针对这种情况系统会全报出来,然后人工基本判断下,比如接口响应慢报警,此时又出现了DB慢查询报警,那基本可以确认是DB的问题。
A、明确失败报警
日志NPE、业务FAIL、系统ERROR、Access (4xx\5xx)、接口异常、dubbo超时、fullgc、DB慢查询等
B、计算类报警
调用量特别小,波动明细,没有连续性,不具有对比性
期望值:如下图所示,当前值与期望值偏差加大

3. 总结
截止目前交易支付系统从收银台、交易、支付、网关、账务、基础服务、监控等各个模块的拆分并独立完善发展,针对高复杂业务和高并发访问的支撑相比以前强大很多。但还有很多不足的地方有待提高和完善。
继续期待交易支付3.0……
本文作者吕博,系去哪儿网金融事业部研发工程师。毕业于吉林大学,2012年加入去哪儿网。 致力于支付平台研发和支付环节的基础服务建设。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号