
OO_Unit3_JML规格
JML基础知识
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规范语言,可用于指定Java模块的行为。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具以静态方式来检查代码实现对规格的满足情况。
JML有两种主要的用法: (1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。 (2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
1.注释结构
JML以javadoc注释的方式来表示规格,每行都以@起头。有两种注释方式,行注释和块注释。其中行注释的表示方式为//@annotation,块注释的方式为/* @ annotation @*/。
2.JML表达式
2.1.原子表达式
-
\result:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。 -
\old(expr):表示一个表达式expr在相应方法执行前的取值,该表达式涉及到评估expr中的对象是否发生变化。 如果是引用(如hashmap),对象没改变,但进行了插入或删除操作。v和odd(v)也有相同的取值。 -
\not_assigned(x,y,...):用来表示括号中的变量是否在方法执行过程中被赋值。如果没有被赋值,返回为true ,否则返回 false 。用于后置条件的约束,限制一个方法的实现不能对列表中的变量进行赋值。 -
\not_modified(x,y,...):该表达式限制括号中的变量在方法执行期间的取值未发生变化。 -
\nonnullelements(container):表示container对象中存储的对象不会有null。 -
\type(type):返回类型type对应的类型(Class),如type(boolean)为Boolean.TYPE。TYPE是JML采用的缩略表示,等同于Java中的 java.lang.Class。 -
\typeof(expr):该表达式返回expr对应的准确类型。如\typeof(false)为Boolean.TYPE。
2.2.量化表达式
-
\forall:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。 -
\exists:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。 -
\sum:返回给定范围内的表达式的和。 -
\product:返回给定范围内的表达式的连乘结果。 -
\max:返回给定范围内的表达式的最大值。 -
\min:返回给定范围内的表达式的最小值。 -
\num_of:返回指定变量中满足相应条件的取值个数。
2.3.集合表达式
可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。集合构造表达式的一般形式为:new ST {T x|R(x)&&P(x)},其中的R(x)对应集合中x的范围,通常是来自于某个既有集合中的元素,如s.has(x),P(x)对应x取值的约束。
2.4.操作符
JML可以正常使用java所定义的操作符,此外,还专门定义了以下四类。
-
子类型操作符:
E1<:E2。如果类型E1是类型E2的子类型(sub type)或相同类型,则该表达式的结果为真,否则为假。任意一个类X,都必然满足X.TYPE<:Object.TYPE。 -
等价关系操作符:
b_expr1<==>b_expr2或b_expr1<=!=>b_expr2。其中b_expr1和b_expr2都是布尔表达式。 -
推理操作符:
b_expr1==>b_expr2或b_expr1<==b_expr2。对于表达式b_expr1==>b_expr2而言,当b_expr1==false,或者b_expr1==true且b_expr2==true时,整个表达式的值为 true 。 -
变量引用操作符:
\nothing或\everthing。表示当前作用域访问的所有变量,前者空集,后者全集。变量引用操作符经常在assignable句子中使用,如assignable \nothing表示当前作用域下每个变量都不可以在方法执行过程中被赋值。
3.方法规格
3.1.前置条件
requires P,对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性。
3.2.后置条件
ensures P,对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。
3.3.副作用
副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。
- 从方法规格的角度,必须要明确给出副作用范围。
- JML提供了副作用约束子句,使用关键词
assignable或者modifiable。
3.4.signals/signal_only子句
signals子句的结构为signals (Exception e) b_expr,意思是当b_expr为 true 时,方法会抛出括号中给出的相应异常e。
- signals子句强调在对象状态满足某个条件时会抛出符合相应类型的异常;
- signals_only则不强调对象状态条件,强调满足前置条件时抛出相应的异常。
4.类型规格
4.1.不变式(invariant)
不变式(invariant)是要求在所有可见状态下都必须满足的特性,语法上定义invariant P,其中invariant为关键词, P 为谓词。
- 静态不变式(static invariant):只针对类中的静态成员变量取值进行约束。
- 实例不变式(instance invariant):可以针对静态成员变量和非静态成员变量的取值进行约束。
4.2.状态变化约束(constraint)
对象的状态在变化时往往也许满足一些约束,这种约束本质上也是一种不变式。JML为了简化使用规则,规定invariant只针对可见状态(即当下可见状态)的取值进行约束,而是用constraint来对前序可见状态和当前可见状态的关系进行约束。
- 静态约束(static constraint):指涉及类的静态成员变量。
- 实例约束(instance constraint):指涉及类的静态成员变量和非静态成员变量。
5.类型层次设计(继承)
- 子类继承了父类的规格
- 子类可以重写父类的方法规格
- 子类可以扩充父类的方法规格和数据规格
- 子类的数据抽象:父类数据抽象+新增的数据抽象
- 子类的数据规格:父类的数据规格+扩展的数据规格+新增的数据规格
- 子类的方法规格:父类方法规格+重写的方法规格+新增的方法规格
- 以上描述需满足LSP原则
- 子类重写父类方法时不能与父类的方法规格相冲突
- 子类新增和扩展的数据规格不能与父类数据规格相冲突
JML应用工具链
OpenJML
OpenJML是一套用于编辑、解析、类型检查、验证(静态检查)和运行时检查Java程序的工具。这些程序都使用JML语句进行注释,说明程序的方法应该做什么,以及数据结构应该遵守的不变量。关于方法或类的JML注释,声明前置条件、后置条件、不变量等。OpenJML将检查实现和规范是否一致。
JMLUnitNG
单元测试工具。可以通过编写单元测试类和方法,来实现对类和方法实现正确性的快速检查和测试。还可以查看测试覆盖率以及具体覆盖范围(精确到语句级别),以帮助编程者全面无死角的进行程序功能测试。
- 测试可以自动化,只要代码发生变化,可以自动回归
- 通过维护规格和测试代码的一致性,软件质量水平得到了保持
SMT Solver
JUnit单元测试
public class MyGraphTest { private static MyGraph myGraph = new MyGraph(); @BeforeClass public static void beforeClass() throws Exception { myGraph.addPath(new MyPath(1, 2, 3, 4)); myGraph.addPath(new MyPath(1, 2, 3, 3, 4, 5)); myGraph.addPath(new MyPath(7, 8, 9, 10)); myGraph.addPath(new MyPath(5, 8)); } @Before public void before() { System.out.println("before class"); } @After public void after() { System.out.println("after class"); } /** * Method: containsNode(int i) */ @Test public void testContainsNode() throws Exception { System.out.println(myGraph.containsNode(100)); System.out.println(myGraph.containsNode(3)); } /** * Method: containsEdge(int i, int i1) */ @Test public void testContainsEdge() throws Exception { System.out.println(myGraph.containsEdge(12, 5)); System.out.println(myGraph.containsEdge(1, 2)); myGraph.removePathById(2); System.out.println(myGraph.containsEdge(1, 2)); System.out.println(myGraph.containsEdge(1, 5)); } /** * Method: isConnected(int i, int i1) */ @Test public void testIsConnected() throws Exception { System.out.println(myGraph.isConnected(1, 5)); System.out.println(myGraph.isConnected(3, 3)); myGraph.removePathById(2); System.out.println(myGraph.isConnected(1, 5)); System.out.println(myGraph.isConnected(3, 3)); } /** * Method: getShortestPathLength(int i, int i1) */ @Test public void testGetShortestPathLength() throws Exception { System.out.println(myGraph.getShortestPathLength(4, 10)); System.out.println(myGraph.getShortestPathLength(1, 5)); } }
架构设计
第一次作业
由于本次作业对时间复杂度有限制,所以架构设计的重点主要在于容器的选择。容器相关内容请参考:Java容器详解
- 在
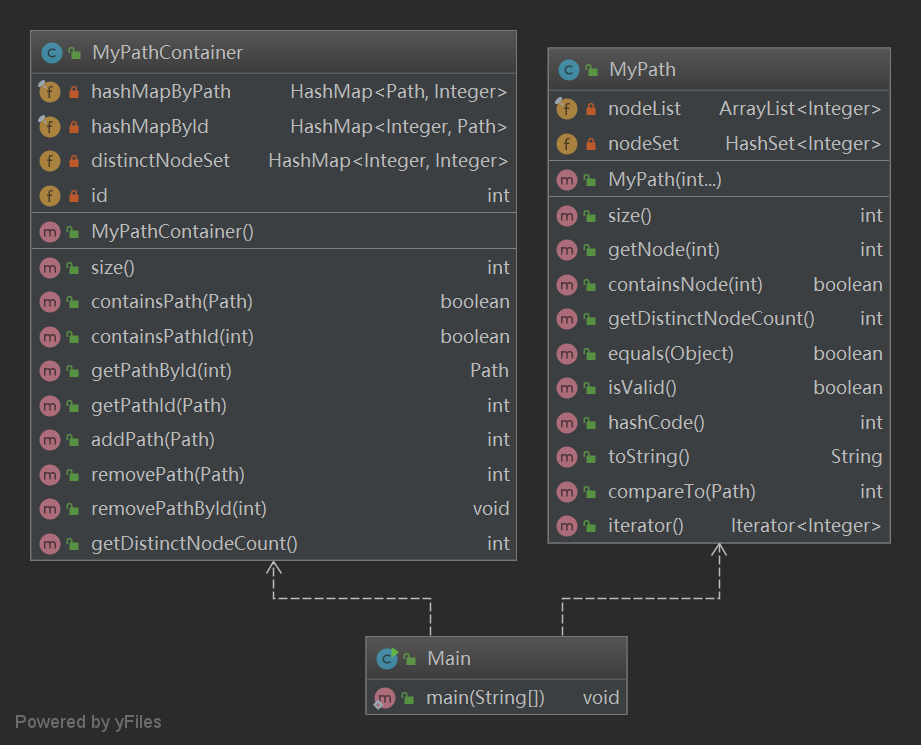
MyPath中,我选择了ArrayList和Hashset两个容器同时记录数据。利用ArrayList顺序存储的特性,我们可以高效实现遍历Path中元素和获取对应下标元素。而利用HashSet内集合元素的唯一性和Hash散列存储的特性,我们可以高效实现计算不同节点的个数以及对元素的查找。 - 在
MyPathContainer中,考虑到既需要通过Path找Id,又需要通过Id找Path,为了实现高效双向查找,我选择使用两个双向的HashMap来存储Id和Path:
private final HashMap<Path, Integer> hashMapByPath; private final HashMap<Integer, Path> hashMapById;
如此,虽然存储的开销加倍了,但是无论是通过Path还是Id查找,时间复杂度都是,大大提高了查找效率。
![]()
第二次作业
本次作业是在第一次作业的基础上实现一些简单的图计算,同样限制了时间复杂度。
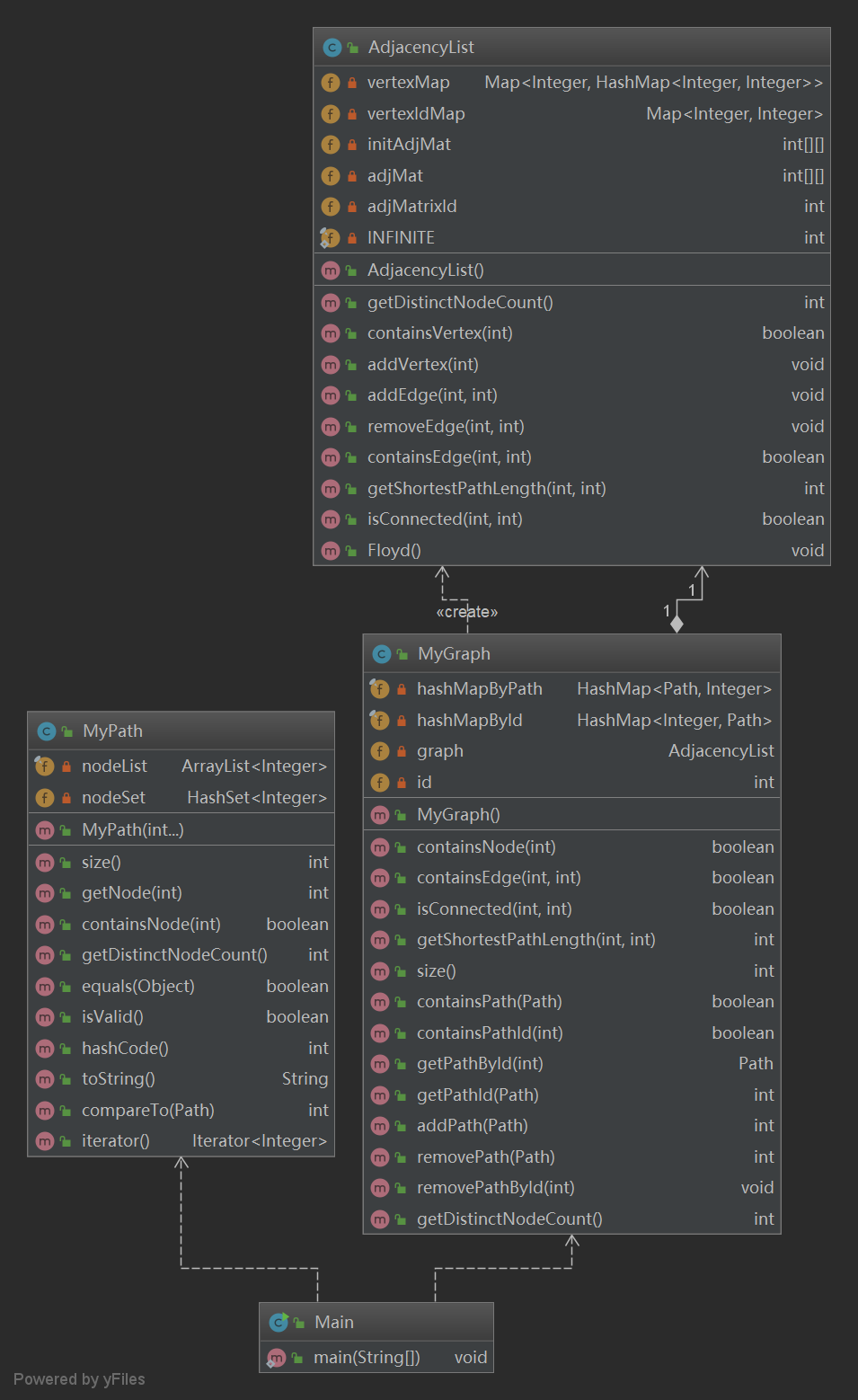
- 为了便于维护,我将所有的图计算都封装在一个单独的类中。
- 需考虑图的存储结构,邻接表or邻接矩阵?对一个稀疏的图而言,邻接表的存储结构可以节省大量的内存空间。但是邻接矩阵在图计算上又比邻接表更便捷。二者各有千秋。为了使图计算变得简单,我选择了空间开销较大的邻接矩阵。毫无疑问,我们不可能建立一个int大小的矩阵,所以我们必须对节点进行映射。用一个
HashMap来记录nodeId与邻接矩阵下标的映射关系。 - 考虑到图结构变更指令只占其中很小的一部分,所以为了优化总体的时间复杂度,应将大量的计算任务按照一定的策略进行均摊,以减少重复劳动。将时间复杂度分散到本就无法降低复杂度的写指令以及线性复杂度指令中;将之前计算出来的部分中间结果保存下来,以减少后续的计算复杂度。在这里,我选择每次变更图结构的时候都进行一次图的刷新和图的计算。(显然这样做很莽,但是结果还不错)
- 至于图最短路径的算法,由于本次作业所涉及的图无向不带权,可考虑BFS、Dijkstra、SPFA、Floyd等算法。我认为最短路径算法的选择不是本次作业的重点,这几种算法都可以满足时间复杂度的要求。重点在于计算任务的均摊和计算结果的缓存。
第三次作业
本次作业是在第二次作业的基础上实现一个简单的地铁网络,同样限制了时间复杂度。
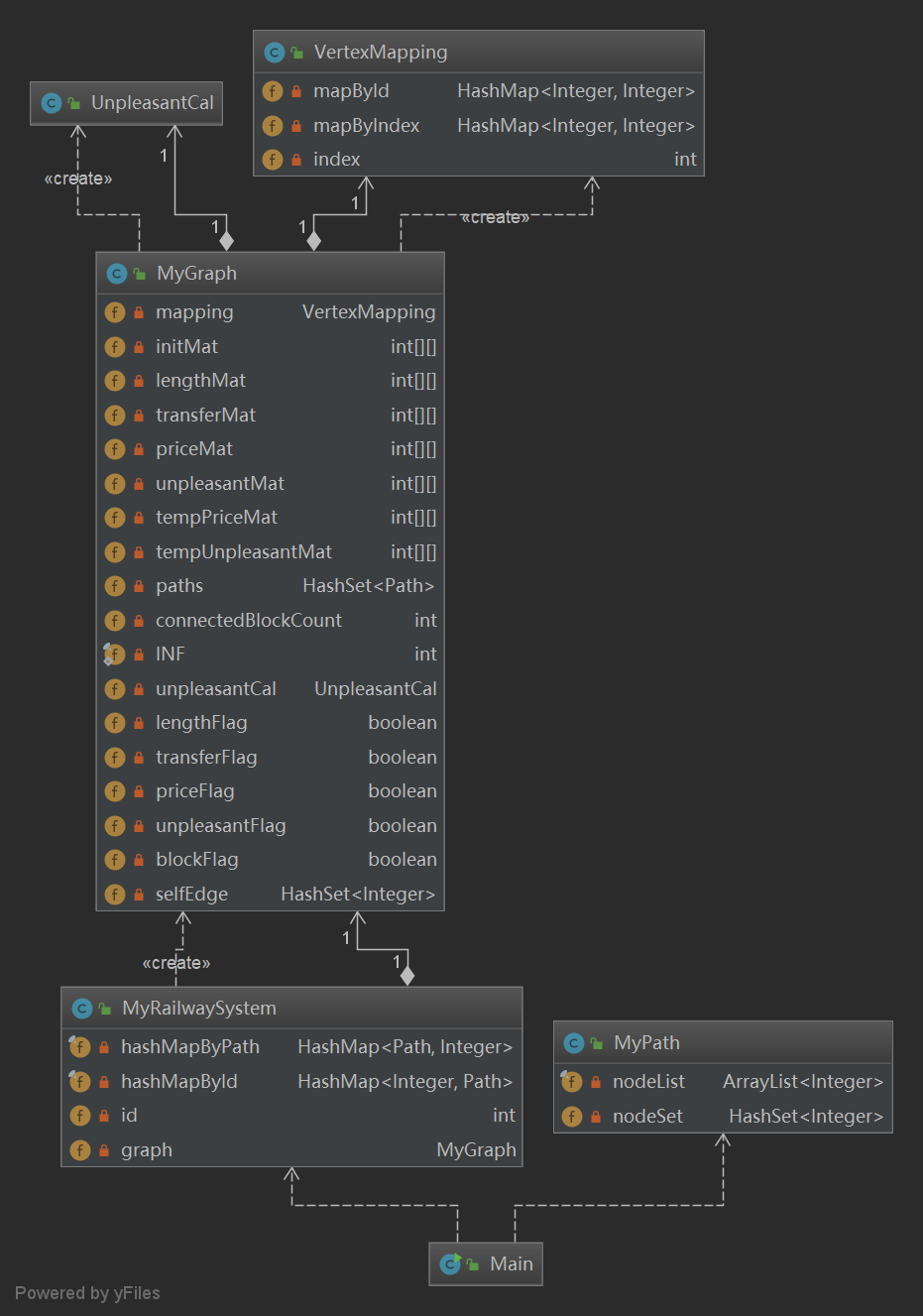
- 为了便于维护,还是将所有的图计算都封装在一个单独的类中,并将节点的映射关系单独建类,进行统一管理。
- 本次作业需实现连通块数量、最低票价、最少换乘次数以及最少不满意度的计算。
- 连通块数量:可以使用BFS算法对图进行染色,染色次数即为连通块的数目。
- 最少换乘次数、最低票价、最少不满意度:这三个问题都可以转化为无向带权图的最短路径问题,进行统一建模。
- 最少换乘次数:构建一个path的完全无向图,把所有边的初始权值全部设置为0。为了体现换乘数,将所有为0的边权值加1得到。这样的话,我们从节点到节点的搭乘线路数就是以为权值的图的最短路径,最小换乘次数=最短线路数-1。
- 最低票价:构建一个path的完全无向图,把所有边的初始权值设置为(同一条线上两点的票价)。为体现换乘数,将所有的边权值加2得到。最低票价 = 以为权值的最短路径 - 2。
- 最少不满意度:构建一个path的完全无向图,把所有边的初始权值设置为(同一条线上两点的不满意度)。为体现换乘数,将所有的边权值加32得到。最低票价 = 以为权值的最短路径 - 32。
- 同样,考虑到图结构变更指令只占其中很小的一部分,所以为了优化总体的时间复杂度,应将计算结果进行缓存,以减少重复劳动。利用Flag标记当前数据是否是最新的计算结果,即两次相同查询之间是否有图结构的变更。若图结构未发生更改,即可直接读取计算结果,否则需重新计算。
- 若图变更指令为
ADD_PATH,直接在原先的图上继续计算。 - 若图变更指令为
REMOVE_PATH,需将原先的图重置,再重新进行计算。
- 若图变更指令为
bug及修复情况
前两次作业无bug。
第三次作业在算法上出现了一些问题,在进行path矩阵和大矩阵的合并的时候,我没有判断path矩阵与大矩阵重叠的边权是否比大矩阵的小。导致出现了一个非常严重的错误。
- 在合并矩阵的时候新增
src[i][j] + weight < dst[i][j]的判断,true则表示大矩阵的边权大于新增path矩阵的边权,用path矩阵的边权进行替代。
同时,在第三次作业中,由于疏忽了规格,导致在CONTAINS_EDGE中没有考虑自环的情况。
- 由于在
initMat矩阵中没有记录自身边(自环),导致无法正确判断例如CONTAINS_EDGE 2 2的,现添加一个新的HashSet<Integer> selfEdge作为所有自环的点集。在addEdge时如果遇到x==y的情况就将该点放入selfEdge中,每次reset的时候将selfEdge清空。在containsEdge方法中新增对这两个点是否是同一个点的判断,若是同一个点,则判断该点是否在selfEdge集合中,若是返回true,反之返回false。
心得体会
-
通过这一单元的学习,我熟悉和掌握了JML的基本使用方法,了解了规格化概念在实际工程中的重要作用。JML帮助我们在进行程序设计时,使用更加规范的方式来描述每个类和方法的状态。通过基于规格的单元测试方法,我们可以进一步验证程序的正确性。
-
规格保证了我们程序的正确性,只要代码实现严格满足JML,就能保证正确性。但是实际情况下,只有正确性往往是不够的,我们还考虑保证程序的运行效率。所以本单元将规格与算法进行融合,在保证逻辑正确的同时又兼顾效率。可以说,本单元锻炼了我在程序设计中的整体思维。
-
通过三次作业的练习,我学习了一些程序设计中的trick。例如java容器的使用、数据缓存、复杂度优化等,拓宽了我的程序设计思维。
-
本单元在算法设计上的失误给了我当头一棒,但同时也让我学到了教训。在写代码前一定要严格验证算法的正确性,而不是想当然的以为自己想的都是对的,然后就着急着写代码。在设计之初就应该尽可能地全方面考虑的各种情况,保证算法的可行性。在设计完成之后,也应该对代码进行充分地测试,保证算法的正确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号