

Java集合框架(二)
Set的接口结构
Collection接口:单列集合,用来存储一个一个的对象
-----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
----------HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值
----------LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历对于频繁的遍历操作,LinkedHashSet效率高于HashSet.
----------TreeSet:可以按照添加对象的指定属性,进行排序。
Set的说明(以HashSet为例)
一、Set:存储无序的、不可重复的数据
以HashSet为例说明:
1. 无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。
2. 不可重复性:保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一个。
二、添加元素的过程:以HashSet为例:
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,
此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断
数组此位置上是否已经有元素:
如果此位置上没有其他元素,则元素a添加成功。 --->情况1
如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
如果hash值不相同,则元素a添加成功。--->情况2
如果hash值相同,进而需要调用元素a所在类的equals()方法:
equals()返回true,元素a添加失败
equals()返回false,则元素a添加成功。--->情况2
对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
jdk 7 :元素a放到数组中,指向原来的元素。
jdk 8 :原来的元素在数组中,指向元素a
总结:七上八下
HashSet底层:数组+链表的结构。
//对某类重写equals()和hashcode()
@Override
public boolean equals(Object o) {
System.out.println("User equals()....");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
return name != null ? name.equals(user.name) : user.name == null;
}
@Override
public int hashCode() { //return name.hashCode() + age;
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
LinkedHashSet
LinkedHashSet的使用
----LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。
----优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSet
TreeSet
1.向TreeSet中添加的数据,要求是相同类的对象。
2.两种排序方式:自然排序(实现Comparable接口) 和 定制排序(Comparator)
3.自然排序中,比较两个对象是否相同的标准为:compareTo()返回0.不再是equals().
4.定制排序中,比较两个对象是否相同的标准为:compare()返回0.不再是equals().
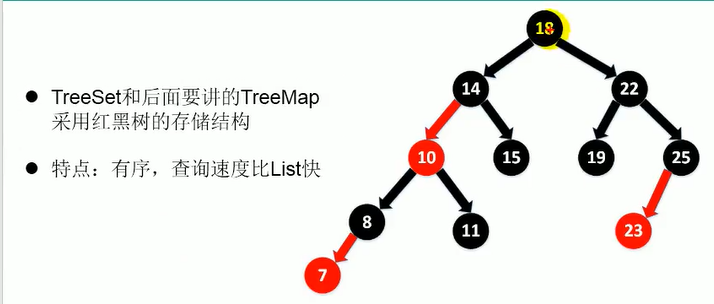
- TreeSet实现自然排序:类中实现Comparable接口和compare()方法
- TreeSet实现定制排序:生成comparator类的对象并传递参数
Comparator com = new Comparator() {
//按照年龄从小到大排列
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof User && o2 instanceof User){
User u1 = (User)o1;
User u2 = (User)o2;
return Integer.compare(u1.getAge(),u2.getAge());
}else{
throw new RuntimeException("输入的数据类型不匹配");
}
}
};
TreeSet set = new TreeSet(com);
Set两道面试题


第二题难度在于,HashSet因为是散列存储,即使中途对某个元素修改参数值其所在散列位置不变(数值hash值变了,散列位置错误),所以之后删除元素或者添加一个新元素(涉及hash查找)都会发生“重复错误”。
所以为了保证避免元素与散列值的不匹配,一般在修改元素值的时候要取出并删除原先的元素,然后再修改元素属性并放回Set中


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现