redis单节点集群
一、概念
redis是一种支持Key-Value等多种数据结构的存储系统。可用于缓存、事件发布或订阅、高速队列等场景。该数据库使用ANSI C语言编写,支持网络,提供字符串、哈希、列表、队列、集合结构直接存取,基于内存,可持久化。
二、redis的应用场景有哪些
1、会话缓存(最常用)
2、消息队列,比如支付
3、活动排行榜或计数
4、发布、订阅消息(消息通知)
5、商品列表、评论列表等
1.redis安装:
1 # wget http://download.redis.io/releases/redis-4.0.6.tar.gz 2 # yum install gcc 3 # make MALLOC=libc 4 # cd src && make install 5 # ./redis-server
2.修改配置文件:
1 # vim ../redis.conf 2 daemonize yes #以后台进程方式启动 3 #bind 127.0.0.1 #允许本地连接 4 requirepass redhat #设置连接密码
3.后台启动:
1 # ./redis-server /root/redis-4.0.6/redis.conf
4.登录:
1 # redis-cli -h 127.0.0.1 -p 6379
认证:
1 auth redhat
5.redis数据类型:
字符串(string):set bp 123 #设置字符串类型bp 值为122
1 hget ID name #获取散列名ID的name对应的值 2 hgetall ID #获取散列ID的全部值 3 hmset age name linux kali contos debian 30 #一次性设置散列age的值 4 hdel ood name #删除某个散列的值 5 hexists age kali #判断某个散列的值是否存在,0不存在
散列(hash):hset ID(散列名) name(键) passwd(值) #设置散列名ID存放的值对
1 hget ID name #获取散列名ID的name对应的值 2 hgetall ID #获取散列ID的全部值 3 hmset age name linux kali contos debian 30 #一次性设置散列age的值 4 hdel ood name #删除某个散列的值 5 hexists age kali #判断某个散列的值是否存在,0不存在
列表(list):lpush test 1 #列表名为test,从左边加入1,编号为最后一位数
1 rpush test -1 #列表名为test,从右边加入-1,编号为0 2 llen test #列表长度 3 lpop test #左边出去一个数 4 rpop test #右边出去一个数 5 lrange test 2 3 #列表下标从0开始计算,显示第三个数和第四个数 6 lrem test 1 3 #左数删除1个3 7 lindex test 2 #获取2的下标 8 ltrim test 0 2 #test取截取(删除)出来的下标0到2对应的值
集合(set):sadd linux a b c d e a b #增加linux集合,集合内容为a b c d e ,不能出现相同数据
1 srem linux d e #删除linux集合中的d e元素 2 smembers linux #查看linux的元素 3 sismember linux d #查看d是否是集合linux的元素,否 4 sdiff linux centos #两个集合取差集,(顺序不同,结果不同) 5 sinter linux centos #取交集 6 sunion linux centos #取并集
有序集合(zset):zadd test1 10(值) a(键) #增加test1有序集合,分数为10 等级为a
1 zrem test1 b #移除test1的等级b的值 2 zscore test1 a #查看test1的等级a的值 3 zrange test1 0 1 #查看test1第一个和第二个的值 4 zrangebyscore test1 5 10 #根据分数查看对应的的等级
三、redis持久化
1.RDB持久化
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照,将Redis内存中的数据,完整的生成一个快照,以二进制格式文件(后缀RDB)保存在硬盘当中。当需要进行恢复时,再从硬盘加载到内存中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。但是一旦发生故障,可能会丢失几分钟的数据。
触发:
1.配置文件:
1 #vim redis.conf 2 save 900 1 // 900内,有1条写入,则产生快照 3 save 300 1000 // 如果300秒内有1000次写入,则产生快照 4 save 60 10000 // 如果60秒内有10000次写入,则产生快照 5 stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入? 主进程不停止 容易造成数据不一致 6 rdbcompression yes // 导出的rdb文件是否压缩,如果rdb的大小很大的话建议这么做 7 Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性 验证版本是不是一致 8 dbfilename dump.rdb //导出来的rdb文件名 9 dir ./ //rdb的放置路径
2.手动:save(同步)
bgsave(异步)
2.AOF持久化
AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂,AOF 文件是一个只进行追加操作的日志文件
触发:
1 #vim redis.conf 2 appendonly no // 是否打开aof日志功能,aof跟rdb都打开的情况下 3 appendfsync always // 每1个命令,都立即同步到aof.安全,速度慢 4 appendfsync everysec // 折衷方案,每秒写1次 5 appendfsync no // 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快, 6 no-appendfsync-on-rewrite yes: // 正在导出rdb快照的过程中,要不要停止同步aof 7 auto-aof-rewrite-percentage 100 //aof文件大小比起上次重写时的大小,增长率100%时,重写缺点刚开始的时候重复重写多次 8 auto-aof-rewrite-min-size 64mb //aof文件,至少超过64M时,重写
3.测试使用 redis-benchmark -n 10000 ::表示 执行请求10000次
四,单节点集群
1 1.创建集群目录:# mkdir /usr/local/redis-cluster 2 3 # wget http://download.redis.io/releases/redis-3.0.6.tar.gz 4 2.解压6次到该目录:# tar zxvf redis-3.0.6.tar.gz -C /usr/local/redis-cluster 5 3.编译安装:# make MALLOC=libc
1 # cd src && make install
1 4.修改绑定IP:# sed -i 's/bind 127.0.0.1/bind 192.168.11.199/g' redis.conf

1 5.修改端口号7001-7006:# sed -i 's/port 6379/port 7001/g' redis-1/redis.conf


6.开启后台启动模式:
1 # sed -i 's/daemonize no/daemonize yes/g' redis.conf

7.复制redis配置文件重命名为redis-2...6.conf,修改端口号7002-7006
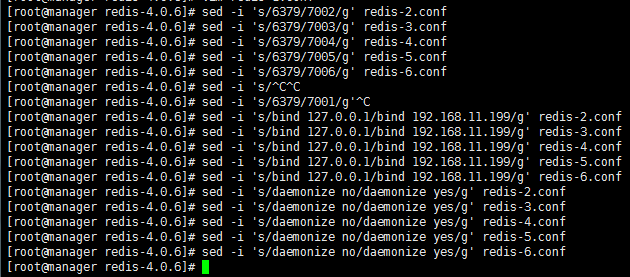
8..安装ruby环境:
1 # yum -y install ruby 2 # yum -y install rubygems
9.安装执行ruby脚本redis-trib.rb执行所依赖的gem包:
# wget https://rubygems.global.ssl.fastly.net/gems/redis-3.2.1.gem # gem install -l ./redis-3.2.1.gem
10.编写脚本启动所有实例
1 #!/bin/bash 2 set -e 3 redis1=/usr/local/redis-cluster/redis-4.0.6/redis-1.conf 4 redis2=/usr/local/redis-cluster/redis-4.0.6/redis-2.conf 5 redis3=/usr/local/redis-cluster/redis-4.0.6/redis-3.conf 6 redis4=/usr/local/redis-cluster/redis-4.0.6/redis-4.conf 7 redis5=/usr/local/redis-cluster/redis-4.0.6/redis-5.conf 8 redis6=/usr/local/redis-cluster/redis-4.0.6/redis-6.conf 9 10 echo "start redis-1..." 11 { 12 /usr/local/bin/redis-server $redis1 >/dev/null 2>&1 13 } || { 14 echo "start error" 15 exit 1 16 } 17 18 19 echo "start redis-2..." 20 { 21 /usr/local/bin/redis-server $redis2 >/dev/null 2>&1 22 } || { 23 echo "start error" 24 exit 1 25 } 26 27 echo "start redis-3..." 28 { 29 /usr/local/bin/redis-server $redis3 >/dev/null 2>&1 30 } || { 31 echo "start error" 32 exit 1 33 } 34 35 echo "start redis-4..." 36 { 37 /usr/local/bin/redis-server $redis4 >/dev/null 2>&1 38 } || { 39 echo "start error" 40 exit 1 41 } 42 43 echo "start redis-5..." 44 { 45 /usr/local/bin/redis-server $redis5 >/dev/null 2>&1 46 } || { 47 echo "start error" 48 exit 1 49 } 50 51 echo "start redis-6..." 52 { 53 /usr/local/bin/redis-server $redis6 >/dev/null 2>&1 54 } || { 55 echo "start error" 56 exit 1 57 }
10.启动

11.复制集群脚本命令
1 # cp src/redis-trib.rb .

12.开启每个配置文件的集群功能
1 # sed -i 's/# cluster-enabled yes/cluster-enabled yes/g' redis-2.conf

13.创建集群
1 # cd src 2 # ./redis-trib.rb create --replicas 1 192.168.11.199:7001 192.168.11.199:7002 192.168.11.199:7003 192.168.11.199:7004 192.168.11.199:7005 192.168.11.199:7006
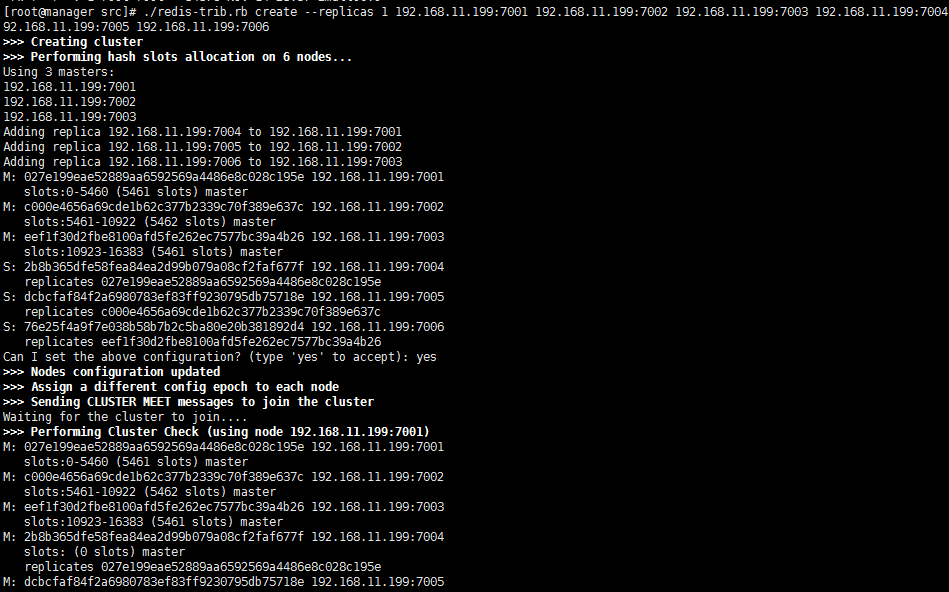
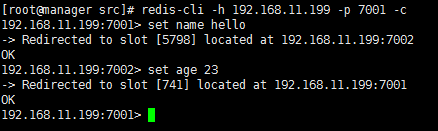
14.连接集群,自动切换集群节点
1 # redis-cli -h 192.168.11.199 -p 7001 -c
15.检查集群状态
1 # ./redis-trib.rb check 192.168.11.199:7001


N~D83P_HB)041V7.png)
您的资助是我最大的动力!
金额随意,欢迎来赏!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号