

准备:新V8即将到来,Node.js的性能正在改变
V8的Turbofan的性能特点将如何对我们优化的方式产生影响

审阅:来自V8团队的Franziska Hinkelmann和Benedikt Meurer.
**更新:Node.js 8.3.0已经发布了V8 6.0和Turbofan.
Node.js依靠V8 JavaScript引擎来运行代码,其语言本身也是我们熟悉和喜爱的。V8 JavaScript引擎是Google为Chrome浏览器编写的JavaScript虚拟机。从一开始,V8的一个主要目标是让JavaScript运行地更快,或者至少比竞争对手更快。而对于一个高动态的松散类型的语言来说,这并不容易。本文介绍了有关V8和JS引擎性能的演变。
JIT(Just In Time)编译器是V8引擎的核心部分,它允许高速执行JavaSctipt代码。它是一个动态编译器,可以在运行时对代码进行优化。在一开始的V8引擎中JIT编译器被称为FullCodegen,后来V8团队实现了Crankshaft,其中包含了很多在FullCodegen中没有实现的性能优化。
修正:FullCodegen是V8引擎的第一个优化编译器,感谢Yang Guo提供。
作为JavaScript的局外人和用户,从90年代开始,似乎JavaSciprt中的快慢路径(无论何种引擎)看起来都违背常理,而JavaScript代码很慢的原因通常也难以理解。
近几年,Matteo Collina和我一直关注如何编写高性能的Node.js代码,这意味着我们必须知道在用V8 JavaScript引擎运行代码时哪些方法要快哪些方法要慢。
现在是时候挑战这些有关性能方面的假设了,因为V8团队已经编写了一个新的JIT编译器:Turbofan.
从众所周知的“V8杀手”(一段会导致optimazation bail-out的代码——该术语在Turbofan中已经没有意义)开始,以及Matteo和我围绕Crankshaft性能方面的一些发现,我们将对V8版本的进展进行一系列的观察并给出微基准测试结果。
当然,在进行V8的逻辑路径优化之前,我们应该首先关注API设计,算法和数据结构。这些微基准测试用来标识JavaScript在Node中的执行过程如何被改变。我们可以使用这些指示器来改变我们的代码风格以及在应用优化之后提高性能的方式。
我们将在V8的5.1,5.8,5.9,6.0和6.1版本上查看微基准测试的性能。
我们将把每个不同的版本放到对应的环境中:V8 5.1引擎使用Node 6和Crankshaft JIT编译器,V8 5.8使用Node 8.0和8.2并混合使用Crankshaft和Turbofan。
当前的6.0引擎属于Node 8.3(或者可能是Node 8.4),而V8的6.1是最新版(在编写本文时),它被集成到Node中,可以查看实验中的node-v8 repo。也就是说,V8 6.1版本最终将会出现在未来的Node版本中,有可能是Node.js 9。
我们来看看微基准测试,而另一方面我们也将讨论这些微基准测试对未来都意味着什么。所有的这些微基准测试都是通过benchmark.js来执行的,并且数值都是按秒绘制的,因此值越高越好。
try/catch的问题
其中一个比较著名的去优化模式是使用try/catch块。
在这个微基准测试中,我们比较了以下四种情况:
- 有try/catch的function(sum try catch)
- 没有try/catch的function(sum without try catch)
- 在try块中调用function(sum wrapped)
- 简单调用一个function,没有try/catch(sum function)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/try-catch.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() function sum (base, max) { var total = 0 for (var i = base; i < max; i++) { total += i } } suite.add('sum with try catch', function sumTryCatch () { try { var base = 0 var max = 65535 var total = 0 for (var i = base; i < max; i++) { total += i } } catch (err) { console.log(err.message) } }) suite.add('sum without try catch', function noTryCatch () { var base = 0 var max = 65535 var total = 0 for (var i = base; i < max; i++) { total += i } }) suite.add('sum wrapped', function wrapped () { var base = 0 var max = 65535 try { sum(base, max) } catch (err) { console.log(err.message) } }) suite.add('sum function', function func () { var base = 0 var max = 65535 sum(base, max) }) suite.on('complete', require('./print')) suite.run()

可以看到,在Node 6(V8 5.1)中围绕try/catch所产生的性能问题是真实存在的,但是对Node 8.0-8.2(V8 5.8)版本的性能影响要小得多。
另外值得注意的是,从try块内部调用一个函数要比从try块外部调用一个函数慢得多——这一点在Node 6(V8 5.1)和Node8.0-8.2(V8 5.8)中都是一样的。
不过,对于Node 8.3+而言,在try块内部调用函数的性能可以忽略不计。
但也别高兴得太早。在研究一些性能研讨会的材料时,Mattero和我发现了一个性能问题,就是在某个特定的情况下会导致Turbofan的无限去优化/重新优化循环(这个被称之为“杀手”——一种破坏性能的模式)。
移除Objects中的属性
多年来,delete限制了很多希望能写出高性能JavaScript代码的人(至少对于我们正试图编写一个热路径的最优代码来说是这样的)。
Delete的问题被归结为V8在处理JavaScript objects的动态特性和原型链(也可能是动态的)时,对于属性的查找在实现级别上变得更加复杂。
对于快速生成一个属性对象,V8引擎所采用的技术是在C++层根据对象的“形状”来创建一个类。形状本质上是一个属性的key和value(包括原型链的key和value)。它们被称之为“隐藏类”。但是,如果对象的形状存在不确定性,V8会采用另一种属性检索模式:哈希表查找。这是对运行时对象的一种优化。哈希表查找方式明显要慢许多。从以往来看,当我们将一个key从object中delete时,后续的属性访问将变成哈希表查找方式。这就是为什么我们要避免delete一个属性,而是将值设置为undefined。就属性的值而言,这样操作的结果是一样的,但在查看属性是否存在时会有问题。不过,这对于对象的序列化操作来说通常都是没问题的,因为JSON.stringify在输出时不会包含undefined值(在JSON规范中undefined不是有效值)。
现在,让我们来看看新的Turbofan是否解决了delete问题。
在这个微基准测试中我们比较了以下三种情况:
- 将一个对象的属性设置为undefined,然后序列化对象。
- delete一个对象中非最后添加的属性,然后序列化对象。
- delete一个对象中最后添加的属性,然后序列化对象。
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/property-removal.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() function MyClass (x, y) { this.x = x this.y = y } function MyClassLast (x, y) { this.y = y this.x = x } // You can tell if an object is in hash table mode by calling console.log(%HasFastProperties(obj)) when the flag --allow-natives-syntax is enabled in Node.JS. // you can convert back to fast properties using // https://www.npmjs.com/package/to-fast-properties suite.add('setting to undefined', function undefProp () { var obj = new MyClass(2, 3) obj.x = undefined JSON.stringify(obj) }) suite.add('delete', function deleteProp () { var obj = new MyClass(2, 3) delete obj.x JSON.stringify(obj) }) suite.add('delete last property', function deleteProp () { var obj = new MyClassLast(2, 3) delete obj.x JSON.stringify(obj) }) suite.add('setting to undefined literal', function undefPropLit () { var obj = { x: 2, y: 3 } obj.x = undefined JSON.stringify(obj) }) suite.add('delete property literal', function deletePropLit () { var obj = { x: 2, y: 3 } delete obj.x JSON.stringify(obj) }) suite.add('delete last property literal', function deletePropLit () { var obj = { y: 3, x: 2 } delete obj.x JSON.stringify(obj) }) suite.on('complete', require('./print')) suite.run()
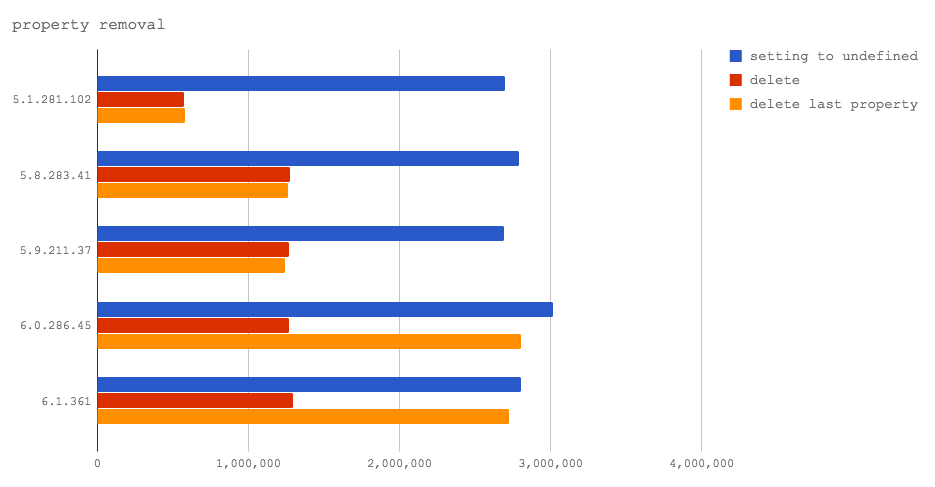
在V8 6.0和6.1中(尚未在任何Node的发行版中使用),删除对象中最后一个添加的属性会在V8中命中快速路径,因此这个操作会比直接将属性值设置为undefined要快。这是一个好消息,因为这表明V8团队正在努力提高delete操作的性能。但是,如果删除的不是最后添加的属性,delete操作仍然会导致其余属性的查找性能下降。所以总的来说,我们还是要推荐继续使用delete。
修正:之前我们认为delete可能并且应该在未来的Node.js版本中使用。感谢Jakob Kummerow告知我们,我们的基准测试只触发了最后一个属性被访问的情况!
显式并数组化Arguments
对普通JavaScript函数来说(ES6中的箭头函数“=>”没有arguments对象),一个常见的问题是隐式arguments对象为类数组,它不是一个真正的数组。
为了使用数组的方法和数组的大部分特性,arguments对象的索引属性被复制到了数组中。在以前,JavaScripters倾向于将代码量与运行速度等同起来,即代码量越少则执行越快。这条规则会有效地减少浏览器端的代码量,但对于服务端来说代码的执行速度更重要。因此这样一种简单有效地将arguments对象转换成数组的方式变得很流行:Array.prototype.slice.call(arguments). 调用数组的slice方法并将arguments对象作为该方法的this上下文传入,该方法会将整个arguments对象作为一个数组来分割。
但是当一个函数的隐式arguments对象从上下文中被暴露出来时(例如,当它从函数返回或者通过Array.prototype.slice.call(arguments)传递给另一个函数时),通常会导致性能下降。现在是时候来挑战这个假设了。
在下一个微基准测试中,我们测试了四个V8版本中的两个相互关联的问题:即暴露arguments参数所产生的开销,以及将arguments参数复制到数组中的开销(随后可以从函数内部访问该数组,从而替代暴露arguments对象)。
下面是具体的测试用例:
- 将arguments对象暴露给另一个函数——没有数组转换(leaky arguments)
- 使用Array.prototype.slice方式拷贝arguments对象的副本(Array.prototype.slice arguments)
- 使用for循环复制arguments中的每一个值到数组中(for loop copy arguments)
- 使用EcmaScript 2015的展开运算符将输入的参数列表赋值给一个数组(spread operator)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/arguments.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() function leakyArguments () { return other(arguments) } function copyArgs () { var array = new Array(arguments.length) for (var i = 0; i < array.length; i++) { array[i] = arguments[i] } return other(array) } function sliceArguments () { var array = Array.prototype.slice.apply(arguments) return other(array) } function spreadOp(...args) { return other(args) } function other (toSum) { var total = 0 for (var i = 0; i < toSum.length; i++) { total += toSum[i] } return total } suite.add('leaky arguments', () => { leakyArguments(1, 2, 3) }) suite.add('Array.prototype.slice arguments', () => { sliceArguments(1, 2, 3) }) suite.add('for loop copy arguments', () => { copyArgs(1, 2, 3) }) suite.add('spread operator', () => { spreadOp(1, 2, 3) }) suite.on('complete', require('./print')) suite.run()

让我们来看看对应的折线图,以着重观察性能特征的变化:
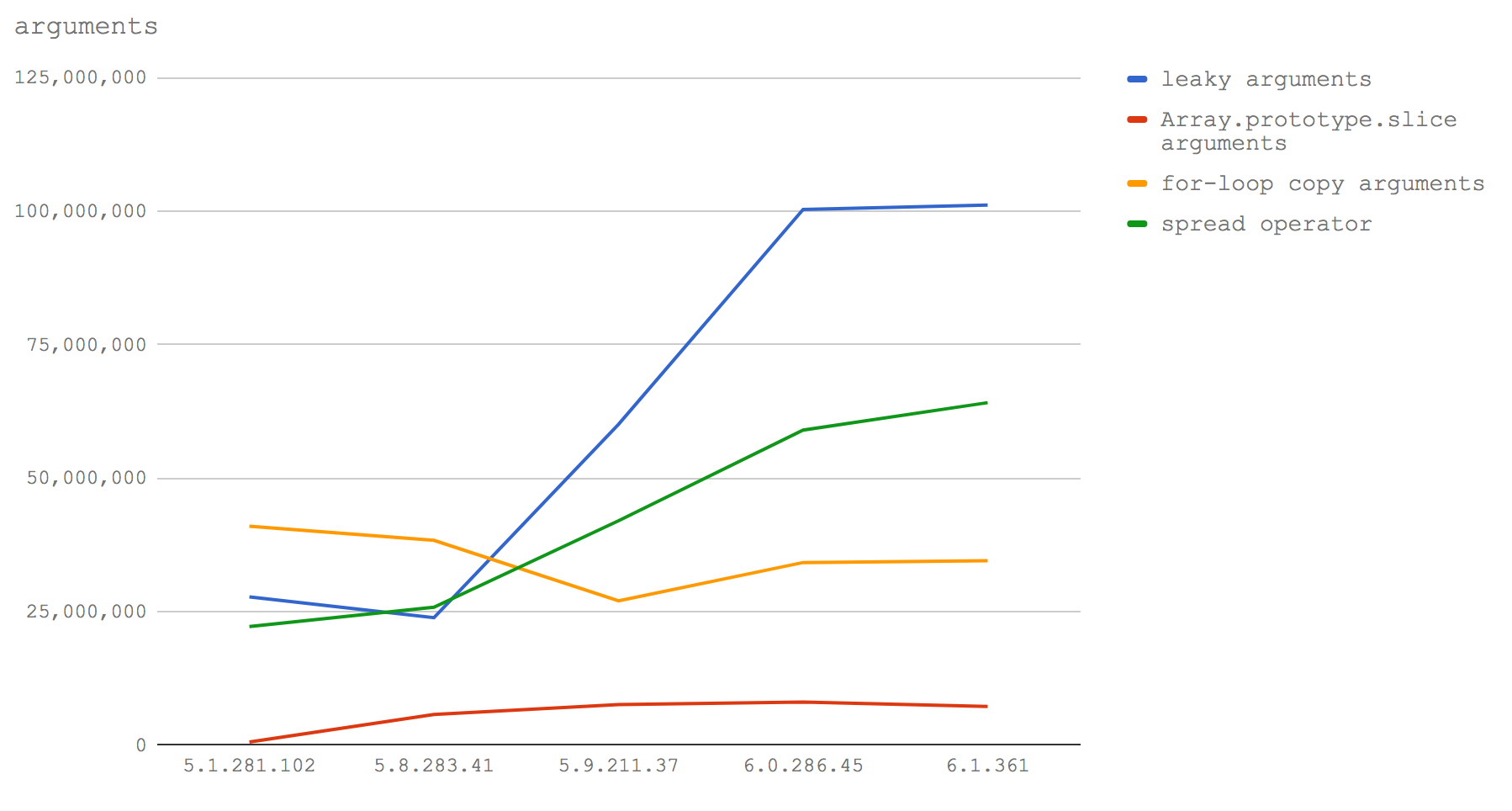
重点是:将函数的输入处理成一个数组,如果想要提高性能的话(依据我的经验这个需求应该很常见),在Node 8.3及以上版本中我们应当使用扩展运算符。而在Node 8.2及以下版本中,应当使用for循环将arguments中的每一个值复制到新(预分配的)数组中(详情可见代码)。
更进一步,在Node 8.3+中,将arguments暴露给其它函数不会引起任何问题,因此当我们不需要一个完整的数组并处理类数组结构时,性能还可能有进一步的提升。
偏函数应用(柯里化)和函数绑定
例如:
function add (a, b) { return a + b } const add10 = function (n) { return add(10, n) } console.log(add10(20))
在函数add中,参数a被函数add10部分地设置成了10。
在EcmaScript 5中,偏函数应用可以通过bind方法来实现:
function add (a, b) { return a + b } const add10 = add.bind(null, 10) console.log(add10(20))
但是我们通常不会使用bind,因为它比使用闭包要慢。
这个基准测试使用函数的直接调用比较了bind和闭包在目标V8版本中的区别。
下面是我们的四个测试用例:
- 一个函数通过柯里化的方式调用另一个函数(curry)
- 箭头函数“=>”通过柯里化的方式调用另一个函数(fat arrow curry)
- 通过bind创建的函数以柯里化的方式调用另一个函数(bind)
- 不用柯里化的方式直接调用一个函数(direct call)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/currying.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() function sum (base, max) { var total = 0 for (var i = base; i < max; i++) { total += i } } var bind = sum.bind(null, 0) var curry = function (max) { return sum(0, max) } var fatCurry = (max) => sum(0, max) suite.add('curry', function smallSum () { var max = 65535 curry(max) }) suite.add('fat arrow curry', function bigSum () { var max = 65535 fatCurry(max) }) suite.add('bind', function smallSum () { var max = 65535 bind(max) }) suite.add('direct call', function bigSum () { var base = 0 var max = 65535 sum(base, max) }) suite.on('complete', require('./print')) suite.run()
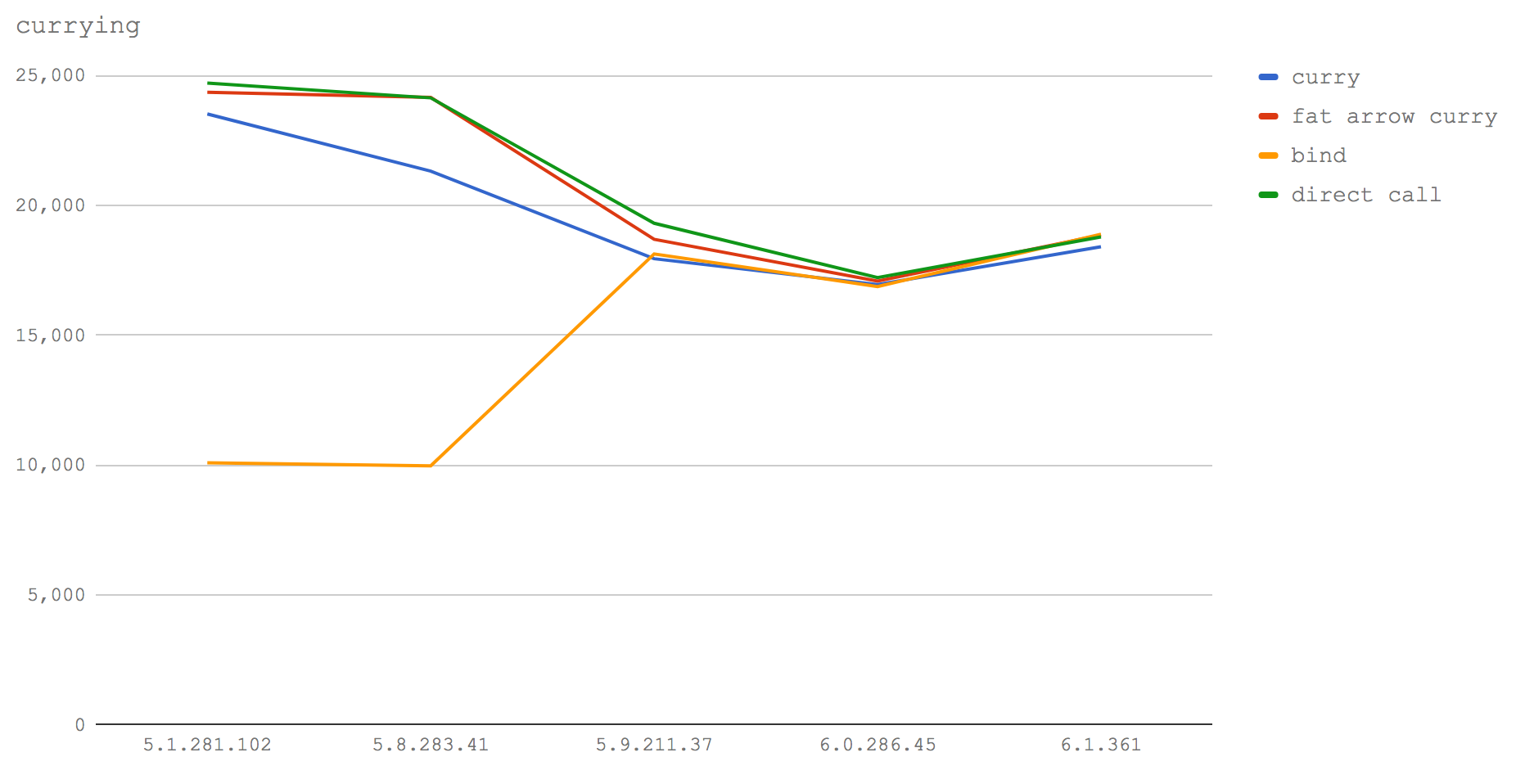
这个基准测试的折线图可视化结果清楚地说明了这些方法在V8的更高版本中是如何融合的。有意思的是,使用箭头函数的偏函数应用要比正常函数快得多(至少在我们的微基准测试中是这样的)。事实上它完全可以媲美函数直接调用。对比来看在V8 5.1(Node 6)和5.8(Node 8.0-8.2)中bind方法是很慢的,显然在偏函数应用中箭头函数是最快的选择。不过,从V8 5.9(Node 8.3+)开始,在未来的6.1版本中,bind的速度提高了一个数量级,成了最快的方法(几乎可以忽略不计)。
在所有的版本中,柯里化最快的方法是使用箭头函数。在后来的版本中使用箭头函数的代码将尽可能地接近使用bind方法的代码,而目前它是比普通函数最快的方法。但需要说明的一点是,我们可能需要用不同的数据结构来测试更多类型的偏函数应用,以获得更全面的了解。
函数字符数
函数的大小,包括签名、空格甚至注释都会影响函数是否可以使用V8内联。是的,给函数添加注释可能会导致性能降低10%。Turbofan会改变这个吗?让我们来看看。
在这个基准测试中我们查看了以下三种情况:
- 调用一个小函数(sum small function)
- 调用一个内联代码的小函数,其中填充了注释(long all together)
- 调用一个用注释填充的大函数(sum long function)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/function-size.js
'use strict' // inlining example, v8 inlines sum() but cannot inline longSum because it is too long // Use --trace_inlining to show this // Output: "Did not inline longSum called from long (target text too big)." var benchmark = require('benchmark') var suite = new benchmark.Suite() function sum (base, max) { var total = 0 for (var i = base; i < max; i++) { total += i } } function longSum (base, max) { // Lorem ipsum dolor sit amet, consectetur adipiscing elit. // Vestibulum vel interdum odio. Curabitur euismod lacinia ipsum non congue. // Suspendisse vitae rutrum massa. Class aptent taciti sociosqu ad litora torquent // per conubia nostra, per inceptos himenaeos. Morbi mattis quam ut erat vestibulum, // at laoreet magna pharetra. Cras quis augue suscipit, pulvinar dolor a, mollis est. // Suspendisse potenti. Pellentesque egestas finibus pulvinar. // Vestibulum eu rhoncus ante, id viverra eros. Nunc eget tempus augue. var total = 0 for (var i = base; i < max; i++) { total += i } } suite.add('sum small function', function short () { var base = 0 var max = 65535 sum(base, max) }) suite.add('long all together', function long () { var base = 0 var max = 65535 // Lorem ipsum dolor sit amet, consectetur adipiscing elit. // Vestibulum vel interdum odio. Curabitur euismod lacinia ipsum non congue. // Suspendisse vitae rutrum massa. Class aptent taciti sociosqu ad litora torquent // per conubia nostra, per inceptos himenaeos. Morbi mattis quam ut erat vestibulum, // at laoreet magna pharetra. Cras quis augue suscipit, pulvinar dolor a, mollis est. // Suspendisse potenti. Pellentesque egestas finibus pulvinar. // Vestibulum eu rhoncus ante, id viverra eros. Nunc eget tempus augue. var total = 0 for (var i = base; i < max; i++) { total += i } }) suite.add('sum long function', function long () { var base = 0 var max = 65535 longSum(base, max) }) suite.on('complete', require('./print')) suite.run()
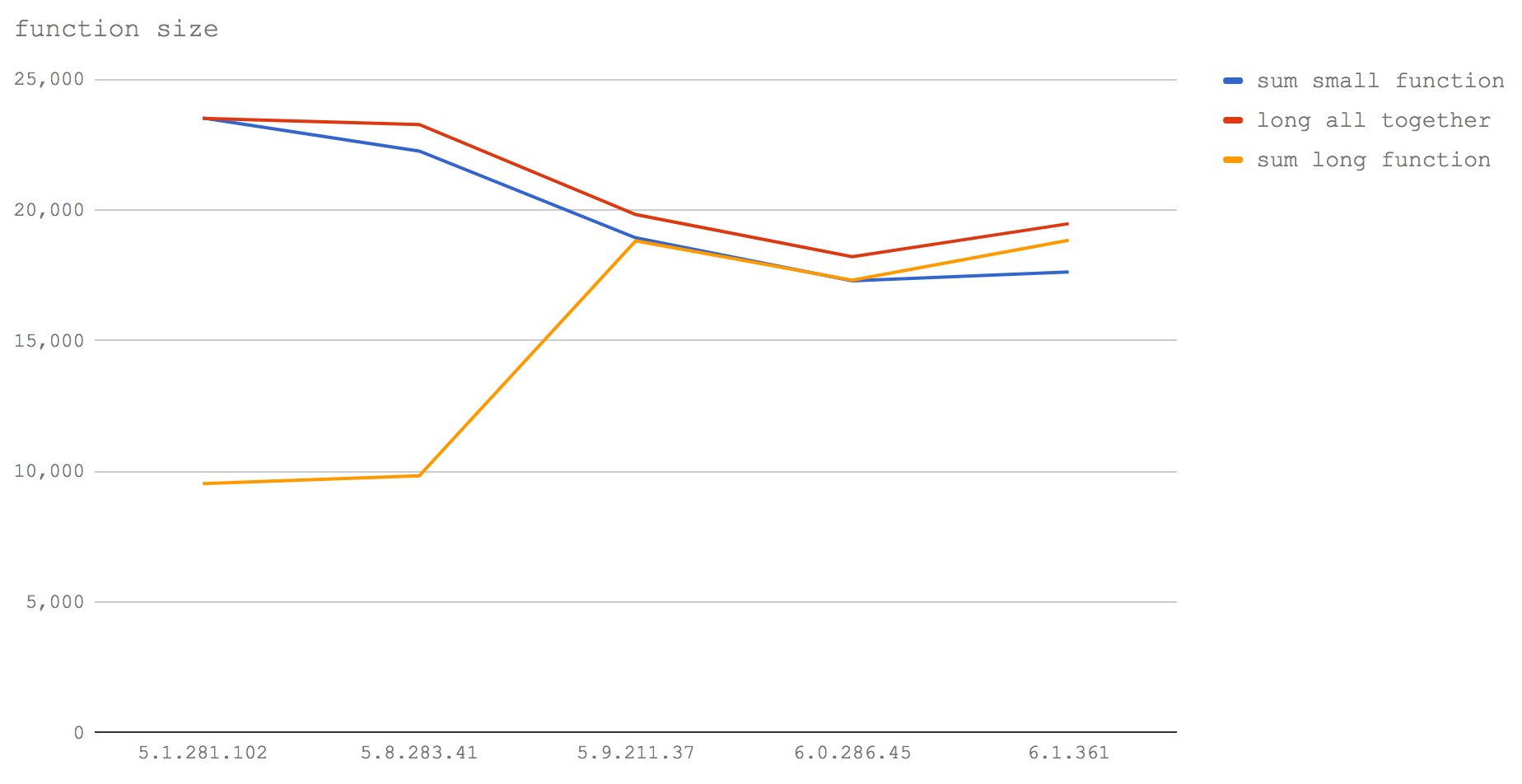
在V8 5.1(Node 6)中sum small function和long all together是相同的。这足以说明内联代码是如何工作的。当我们调用这个小函数时,就如同V8将它的内容写入到被调用的地方。因此当我们编写一个函数时(即使有额外的注释填充),实际上我们已经手动将这些内容写入到调用的函数内联中,所以这两者的性能是相同的。另外我们在V8 5.1(Node 6)中也看到,调用一个填充了大量注释的函数会导致执行速度慢很多。
在Node 8.0-8.2(V8 5.8)中,除了调用小函数的开销明显增大之外,其它几乎没有变化。这可能是由于Crankshaft和Turbofan同时作用产生的碰撞,当一个函数在Crankshaft中时另一个可能在Turbofan中,从而导致内联代码的分离(即在一组连续的内联函数中产生跳跃)。
在5.9及更高版本(Node 8.3+)中,任何由不相关的字符例如空格或注释引起的大小都不会对函数性能产生影响。这是因为Turbofan使用了AST(抽象语法树Abstract Syntax Tree)来确定函数的大小,而不是像在Crankshaft中是通过字符数来计算的。它考虑函数的有效代码,而不是检查函数的字节数。因此从V8 5.9(Node 8.3+)开始,空格,变量名的字符数,函数的签名以及注释都不再作为函数是否内联的因素。
值得注意的是,我们再次看到函数的整体性能在下降。
要点是应该依然保持小函数。目前我们仍然需要避免在函数内部添加大量的注释(甚至是空白)。另外,如果你想要绝对的快速,手动内联(去掉函数调用)是最快的方法。当然,这得在函数内联与函数大小(实际可执行代码)之间找到平衡,因此将其它函数的代码复制到自己的函数中有可能会引起性能问题。也就是说,手动内联也存在潜在的风险。在大多数情况下,最好把内联的工作留给编译器。
32位整数与double类型的整数
众所周知,JavaScript仅有一个数字类型:Number.
但是,V8是用C++实现的,因此对于JavaScript数字来说,必须在底层进行类型选择。
对整数而言(在JS中即没有小数的数字),V8假定所有的数字都适合32位,除非不是。这看起来似乎是一个公平的选择,因为大部分情况下数字都是在-2147483648和2147483647之间。假如一个JavaScript整数超过2147483647,JIT编译器会动态地将数字的底层类型改成double(双精度浮点数)——这可能也会对其它的优化产生潜在的影响。
这个基准测试包含了下面三个用例:
- 处理32位以内数字的函数(sum small)
- 处理32位和double类型数字的函数(from small to big)
- 处理double类型数字的函数(all big)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/numbers.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() function sum (base, max) { var total = base for (var i = base + 1; i < max; i++) { total += i } return total } suite.add('sum small', function smallSum () { var base = 0 var max = 65535 // 0 + 1 + ... + 65535 = 2147450880 < 2147483647 sum(base, max) }) suite.add('from small to big', function bigSum () { var base = 32768 var max = 98303 // 32768 + 32769 + ... + 98303 = 4294934528 > 2147483647 sum(base, max) }) suite.add('all big', function bigSum () { var base = 2147483648 var max = 2147549183 // 2147483648 > 2147483647 sum(base, max) }) suite.on('complete', require('./print')) suite.run()
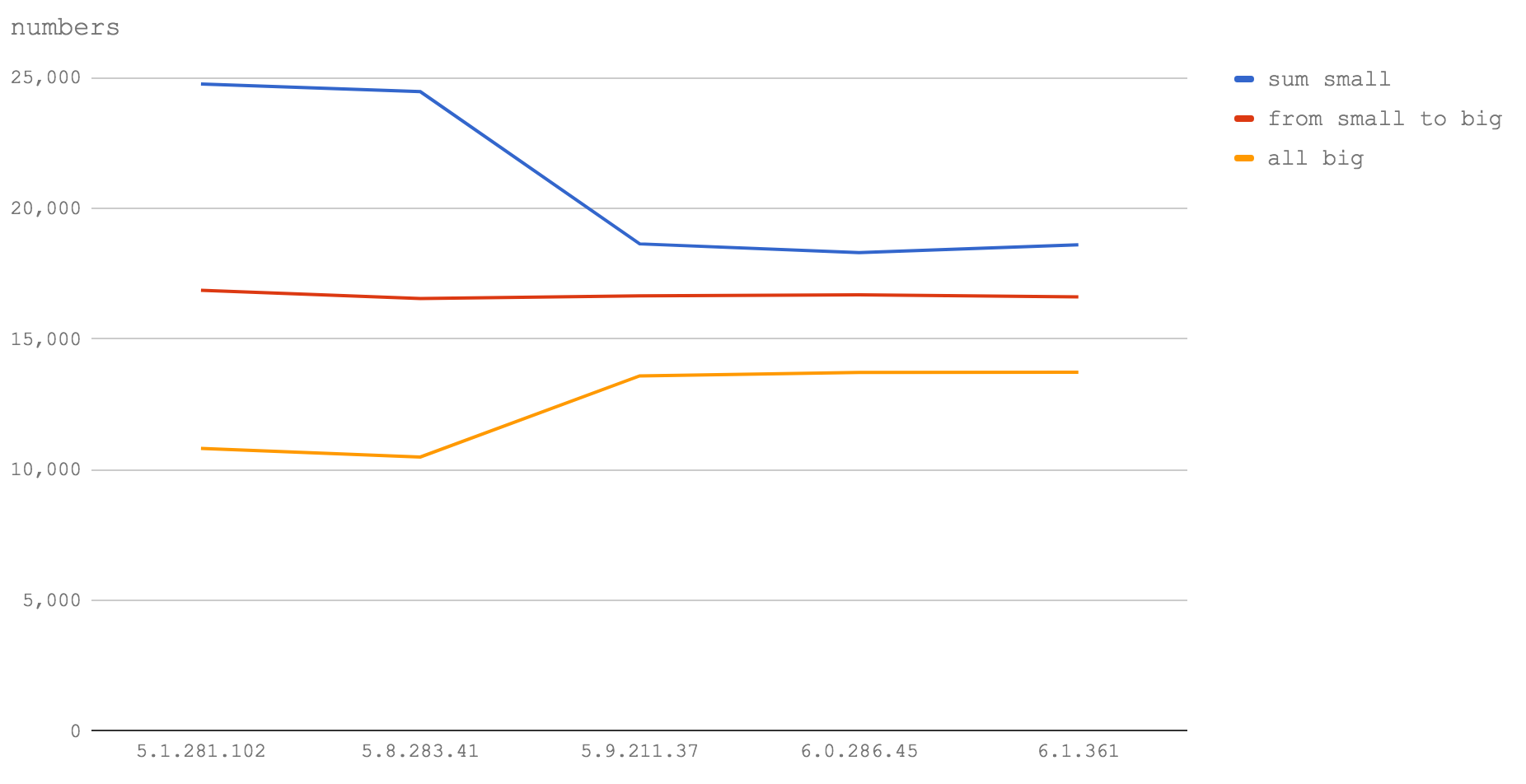
从图中我们可以看到,无论是Node 6(V8 5.1)还是Node 8(V8 5.8),甚至是将来的Node版本,该测试结果都是成立的。操作大于2147483647的整数将导致函数的运行速度为1/2~2/3。所以,如果你有一个很长的数字ID,将它们放到字符串中。
同样值得注意的是,对32位以内的数字操作,在Node 6(V8 5.1)和Node 8.1(V8 5.8)之间速度增加,但在Node 8.3+(V8 5.9+)中速度明显变慢。但是,对于double类型数字的操作在Node 8.3+ (V8 5.9+)中变得更快。这很可能是32位的数字处理速度变慢,而不是与函数调用的速度或者循环(在测试代码中使用的)有关。
修正:感谢Jakob Kummerow和Yang Guo以及V8团队给出了精确的测量结果。
对象的迭代
获取一个对象的所有值并进行相关的操作十分常见,而且有很多方法可以实现。让我们来看看在V8(和Node)版本中哪个是最快的。
这个基准测试针对所有的V8版本包含了以下四个用例:
- 在for-in循环中通过hasOwnProperty方法检查以获取对象的值(for in)
- 使用Object.keys以及Array的reduce方法来遍历所有的key,然后获取迭代器函数内部reduce方法提供的对象值(Object.keys functional)
- 与上面的方法类似,只不过将迭代器函数提供的reduce方法换成了箭头函数(Object.keys functional with arrow)
- 使用for循环遍历从Object.keys返回的数组,在循环中获取对象的值(Object.keys with for loop)
我们还对V8 5.8,5.9和6.1做了另外的三个测试:
- 使用Object.values以及Array的reduce方法来遍历所有的值(Object.values functional)
- 与上面的方法类似,只不过将迭代器函数提供的reduce方法换成了箭头函数(Object.values functional with arrow)
- 使用for循环遍历从Object.values返回的数组(Object.values with for loop)
我们没有在V8 5.1(Node 6)中跑这些测试用例,因为不支持原生的EcmaScript 2017 Object.values方法。
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/object-iteration.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() suite.add('for-in', function forIn () { var obj = { x: 1, y: 1, z: 1 } var total = 0 for (var prop in obj) { if (obj.hasOwnProperty(prop)) { total += obj[prop] } } }) suite.add('Object.keys functional', function forIn () { var obj = { x: 1, y: 1, z: 1 } var total = Object.keys(obj).reduce(function (acc, key) { return acc + obj[key] }, 0) }) suite.add('Object.keys functional with arrow', function forIn () { var obj = { x: 1, y: 1, z: 1 } var total = Object.keys(obj).reduce((acc, key) => { return acc + obj[key] }, 0) }) suite.add('Object.keys with for loop', function forIn () { var obj = { x: 1, y: 1, z: 1 } var keys = Object.keys(obj) var total = 0 for (var i = 0; i < keys.length; i++) { total += obj[keys[i]] } }) if (process.versions.node[0] >= 8) { suite.add('Object.values functional', function forIn () { var obj = { x: 1, y: 1, z: 1 } var total = Object.values(obj).reduce(function (acc, val) { return acc + val }, 0) }) suite.add('Object.values functional with arrow', function forIn () { var obj = { x: 1, y: 1, z: 1 } var total = Object.values(obj).reduce((acc, val) => { return acc + val }, 0) }) suite.add('Object.values with for loop', function forIn () { var obj = { x: 1, y: 1, z: 1 } var vals = Object.values(obj) var total = 0 for (var i = 0; i < vals.length; i++) { total += vals[i] } }) } suite.on('complete', require('./print')) suite.run()
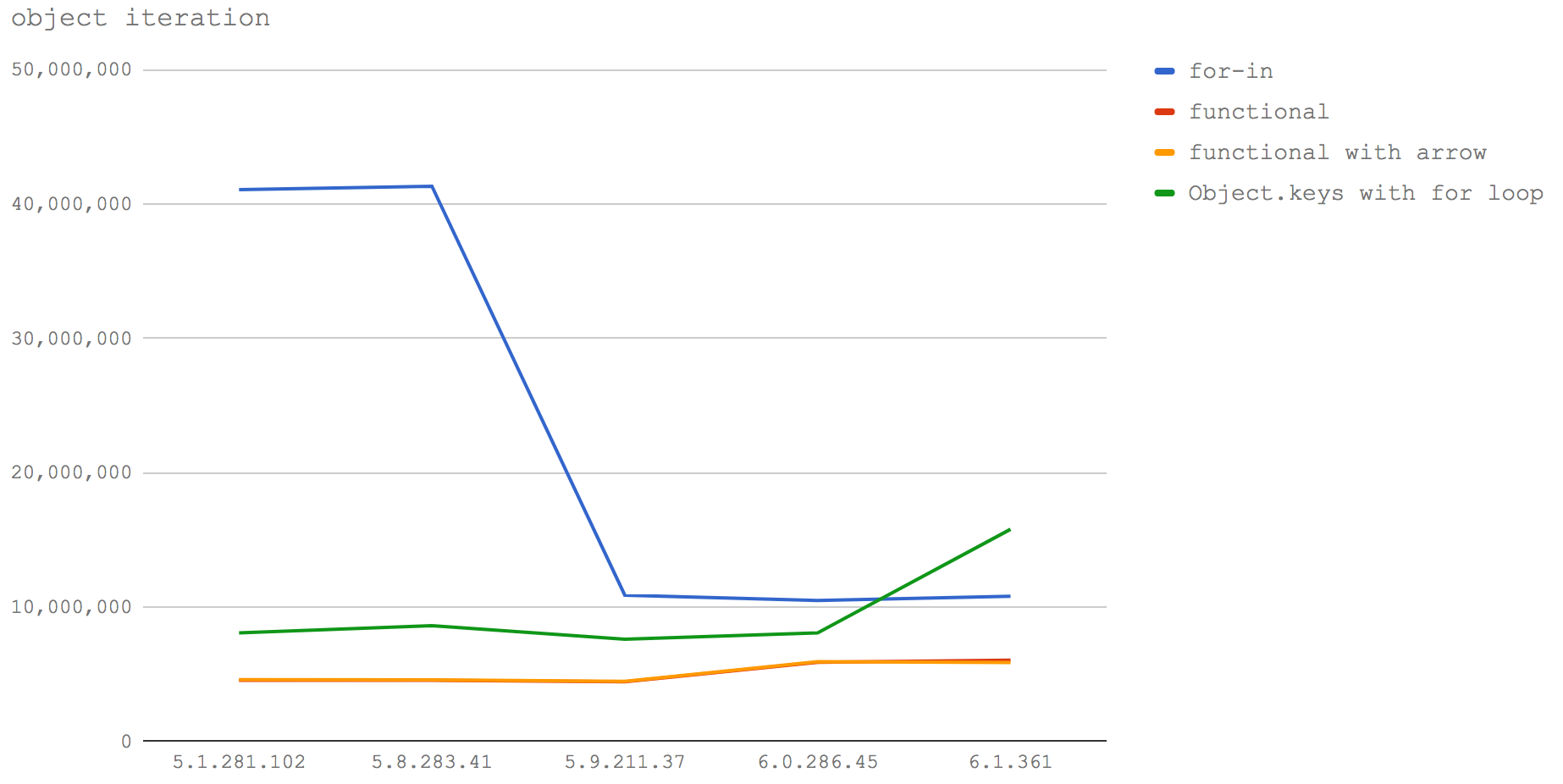
在Node 6(V8 5.1)和Node 8.0-8.2(V8 5.8)中,使用for-in循环来遍历对象的key和value是迄今为止最快的方法。每秒大约操作4千万次,比排第二位的Object.keys方法快5倍,后者每秒大约操作800万次。
在V8 6.0(Node 8.3)中,for-in循环有时候会出现一些问题,导致其性能会降到之前版本的1/4,但仍比其它方法都快。
在V8 6.1(未来的Node版本)中,Object.keys的速度有了一个飞跃,变得比for-in循环还要快。但在V8 5.1和5.8(Node 6,Node 8.0-8.2)中速度没有接近for-in循环。
可见Turbofan背后的工作原理是对最直观的编码行为进行优化。即优化对开发人员来说最熟悉的代码。
使用Object.values直接获取值比用Object.keys遍历对象的key然后再获取值要慢。重要的是,程序循环比函数式编程要快。因此在对象迭代过程中可能会做很多事情。
还有,对于那些使用for-in循环来提高程序性能的人而言,如果速度受到影响而又没有任何可用的替代方法时,那将会非常痛苦。
注解:在V8中for-in循环的性能问题已经被修复,更多细节请参见http://benediktmeurer.de/2017/09/07/restoring-for-in-peak-performance/。这个修改将会被整合进Node 9中。
对象分配
对象的分配是无可避免的,所以这是一个重要的测试部分。
我们将查看以下三个测试用例:
- 通过对象的迭代进行对象分配(literal)
- 使用EcmaScript 2015的Class进行对象分配(class)
- 通过构造函数进行对象分配(constructor)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/object-creation.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() var runs = 0 // the for loop is needed otherwise V8 // can optimize the allocation of the object // away var max = 10000 class MyClass { constructor (x) { this.x = x } } function MyCtor (x) { this.x = x } suite.add('noop', function noop () {}) suite.add('literal', function literalObj () { var obj = null for (var i = 0; i < max; i++) { obj = { x: 1 } } return obj }) suite.add('class', function classObj () { var obj = null for (var i = 0; i < max; i++) { obj = new MyClass(1) } return obj }) suite.add('constructor', function constructorObj () { var obj = null for (var i = 0; i < max; i++) { obj = new MyCtor(1) } return obj }) suite.on('cycle', () => runs = 0) suite.on('complete', require('./print')) suite.run()
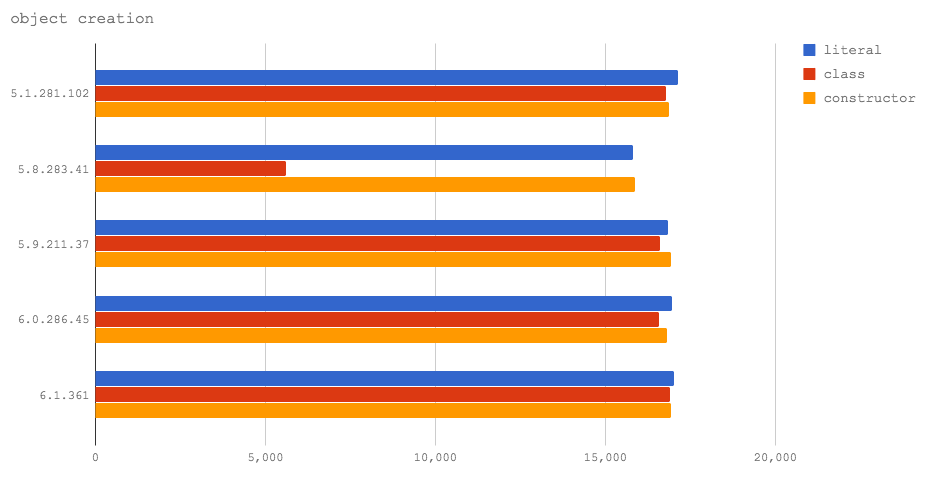
对象分配在所有V8版本的测试中都有相同的结果,除了Node 8.2(V8 5.8)中的class,它比其它的方式都慢。这是由于V8 5.8中的混合Crankshaft/Turbofan特性所致,在包含V8 6.0的Node 8.3中将解决这个问题。
修正:Jakob Kummerow在http://disq.us/p/1kvomfk中指出,在特定的微基准测试中Turbofan可以优化对象分配,从而导致不正确的测试结果,所以本文做了相应的调整。
对象分配的清除
在对本文的结果进行整理时,我们发现Turbofan会始终对某一类对象分配进行优化。起初我们还一直以为这个优化会针对所有的对象分配,感谢V8团队的加入,使得我们能够更好地理解该优化所涉及的部分。
在之前的对象分配微基准测试中,我们分配了一个变量,将值设置为null,然后多次重新分配该变量,以避免触发我们现在要查看的特殊优化操作。
与上面一样,这里的微基准测试也包含以下三个测试用例:
- 通过对象的迭代进行对象分配(literal)
- 使用EcmaScript 2015的Class进行对象分配(class)
- 通过构造函数进行对象分配(constructor)
不同之处在于,对象的引用不会被其它对象的分配所覆盖,而是将该对象传递给另一个操作该对象的函数。
我们来看看测试结果!
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/object-creation-inlining.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() var runs = 0 class MyClass { constructor (x) { this.x = x } } function MyCtor (x) { this.x = x } var res = 0 function doSomething (obj) { res = obj.x } suite.add('literal', function base () { var obj = { x: 1 } doSomething(obj) }) suite.add('class', function allNums () { var obj = new MyClass(1) doSomething(obj) }) suite.add('constructor', function allNums () { var obj = new MyCtor(1) doSomething(obj) }) suite.add('create', function allNums () { var obj = Object.create(Object.prototype) obj.x = 1 doSomething(obj) }) suite.on('cycle', () => runs = 0) suite.on('complete', require('./print')) suite.run()
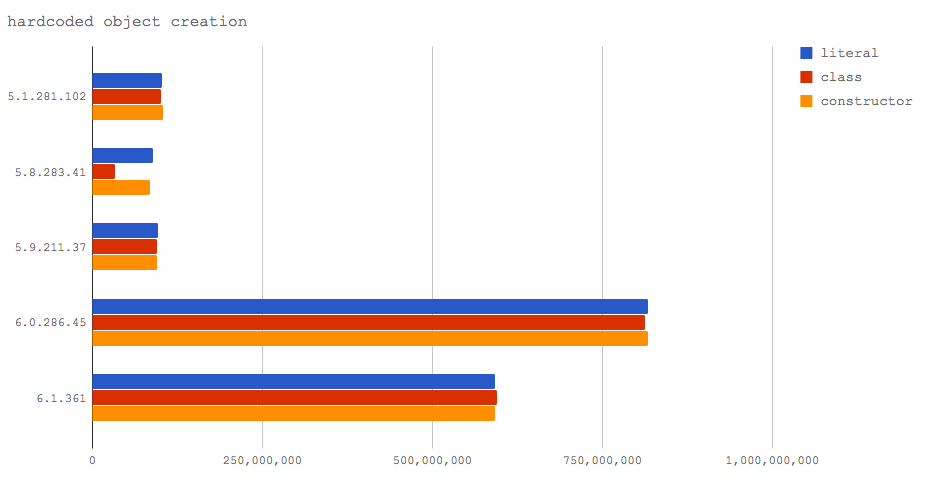
我们注意到在这个微基准测试中V8 6.0(Node 8.3)和6.1(Node 9)的速度大大提高,每秒超过5亿次,主要因为一旦Turbofan应用优化,没有其它任何额外的代码需要执行。在这种特殊情况下,Turbofan能够优化对象分配,因为它不需要对象实际存在就能够确定后续的逻辑可以被执行。
微基准测试的代码仍然没有完全说明如何触发这个优化,而且这个优化应用的条件非常复杂。
但是我们知道的其中一个条件是绝对不会让对象被Turbofan优化掉的:
对象不能超出创建它的函数。意思是说,在堆栈中的每个函数完成之后,不应该再出现对该对象的引用。对象可以传递给其它函数,但是如果我们将该对象添加到this上下文中,或者将其分配给一个外部变量,又或者在堆栈完成之后将其添加到另一个对象,则无法应用优化。
这个影响很酷,但是很难预测这种优化发生的所有条件。尽管如此,当复杂的条件得到满足时,它有可能会产生加速。
修正:感谢Jakob Kummerow和V8团队的其他成员帮助我们发现此特定行为的根本原因。作为这项研究的一部分,我们发现了在V8新GC中的性能回归,Orinoco,如果你对此有兴趣可以查看https://v8project.blogspot.it/2016/04/jank-busters-part-two-orinoco.html and https://bugs.chromium.org/p/v8/issues/detail?id=6663
多态与单态代码
当我们总是将同一类型的参数传递给一个函数时(比如总是传递一个string),我们就是以单态的方式使用这个函数。
有一些函数被写成是多态的。我们可以把多态函数想象成这样一个函数,它在同一参数位置上可以接受不同类型的值。例如,一个函数的第一个参数可以接受一个字符串或者一个对象。不过,这里我们所说的“类型”不是指string,number和object,而是指对象的形状(虽然JavaScript的类型实际上也算作不同的对象形状)。
一个对象的形状由其属性和值来定义。例如,在下面的代码片段中,obj1和obj2是相同的形状,但obj3和obj4与其余的形状不同:
const obj1 = { a: 1 }
const obj2 = { a: 5 }
const obj3 = { a: 1, b: 2 }
const obj4 = { b: 2 }
用同一段代码来处理不同形状的对象,在某些情况下这是非常不错的代码接口,但是往往会影响程序性能。
让我们来看看在我们的微基准测试中单态与多态的测试用例。
这里我们测试以下两种情况:
- 一个处理具有不同属性对象的函数(polymorphic)
- 一个处理具有相同属性对象的函数(monomorphic)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/polymorphic.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() var runs = 0 suite.add('polymorphic', function polymorphic() { var objects = [{a:1}, {b:1, a:2}, {c:1, b:2, a:3}, {d:1, c:2, b:3, a:4}]; var sum = 0; for (var i = 0; i < 10000; i++) { var o = objects[i & 3]; sum += o.a; } return sum; }) suite.add('monomorphic', function monomorphic() { var objects = [{a:1}, {a:2}, {a:3}, {a:4}]; var sum = 0; for (var i = 0; i < 10000; i++) { var o = objects[i & 3]; sum += o.a; } return sum; }) suite.on('complete', require('./print')) suite.run()

上图的可视化数据明确地显示出,在所有测试的V8版本中,单态函数的性能要优于多态函数。不过,从V8 5.9+开始(也就是从使用V8 6.0的Node 8.3开始),多态函数的性能有了一定的改进。
在Node.js的代码中,多态函数十分普遍,它们以APIs的形式提供了很大的灵活性。由于对多态交互的这种改进,我们可以看到在更复杂的Node.js应用程序中的性能有所提升。
如果我们正在编写的代码需要优化,函数需要被多次调用,那么我们应该调用具有相同“形状”参数的函数。另一方面,如果一个函数只被调用一两次,例如instantiating function或者setup function,那么就可以选择一个多态的API。
修正:感谢Jakob Kummerow提供了这个微基准测试的可靠版本。
Debugger关键字
最后,让我们来讨论一下debugger关键字。
确保将debugger语句从你的代码中去掉。多余的debugger语句会影响程序的性能。
我们来看以下两个测试用例:
- 一个包含debugger关键字的函数(with debugger)
- 一个不包含debugger关键字的函数(without debugger)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/debugger.js
'use strict' var benchmark = require('benchmark') var suite = new benchmark.Suite() // node --trace_opt --trace_deopt --trace_inlining --code-comments --trace_opt_verbose debugger.js > out // look for [disabled optimization for 0x34e65f73db01 <SharedFunctionInfo withDebugger>, reason: DebuggerStatement] suite.add('with debugger', function withDebugger () { var base = 0 var max = 65535 var total = 0 for (var i = base; i < max; i++) { debugger total += i } }) suite.add('without debugger', function withoutDebugger () { var base = 0 var max = 65535 var total = 0 for (var i = base; i < max; i++) { total += i } }) suite.on('complete', require('./print')) suite.run()
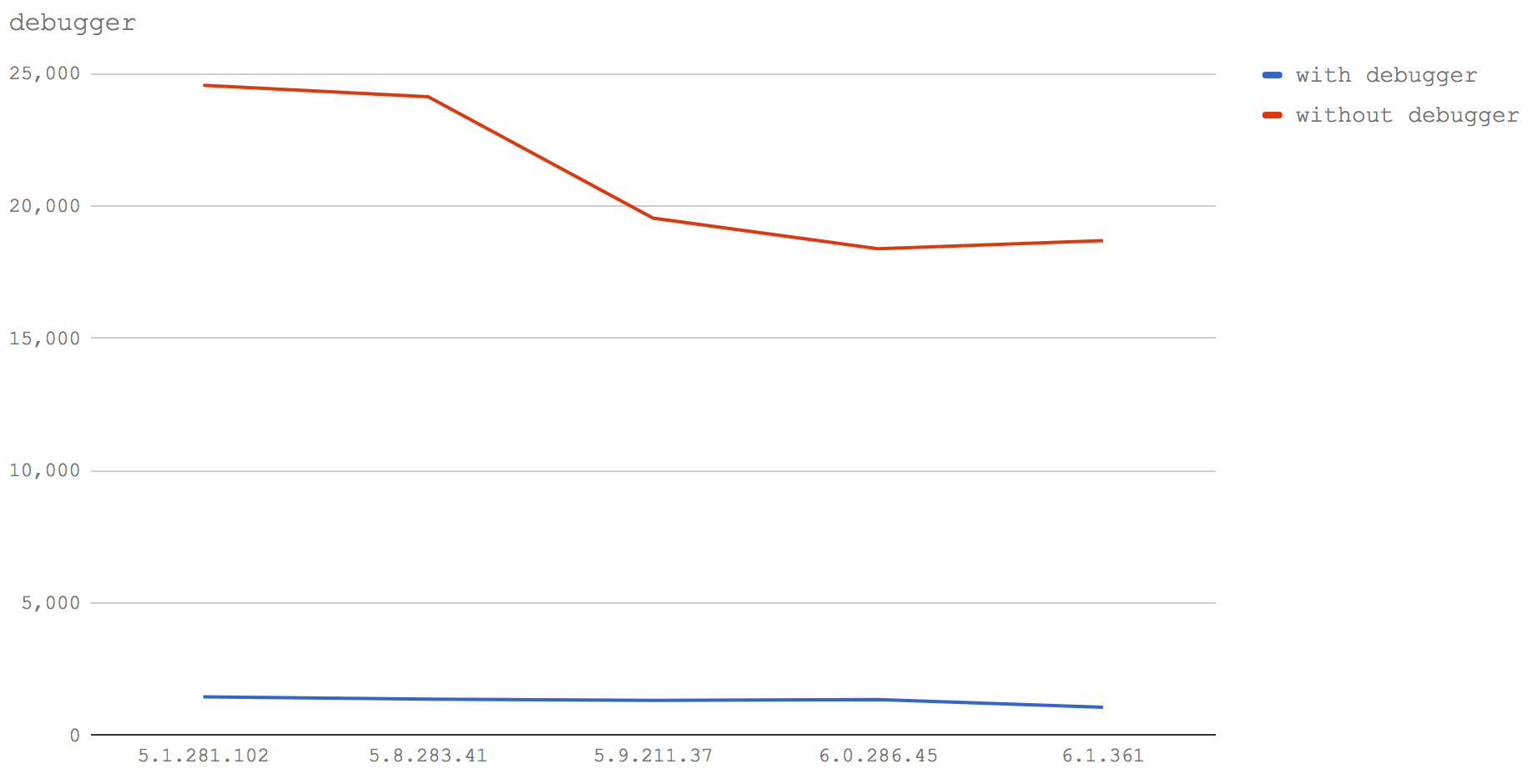
是的 ,只要debugger关键字出现,在所有测试的V8版本中,性能都会严重受到影响。
对于没有debugger关键字的情况,性能出现了连续的下降,我们将在结论一节讨论这个问题。
一个真实的基准测试:Logger的比较
除了我们的微基准测试外,我们还可以通过使用Mattero和我在创建Pino时放在一起的最流行的Node.js的logger作为基准测试来查看V8版本的整体效果。
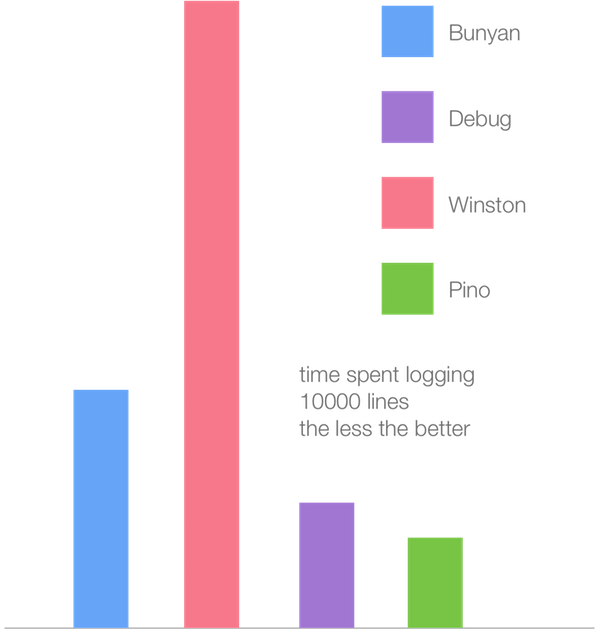
下面的条形图记录了在Node.js 6.11(Crankshaft)中使用最流行的logger记录一万行日志所花的时间(越少越好):
而下面是使用V8 6.1(Turbofan)的测试结果:
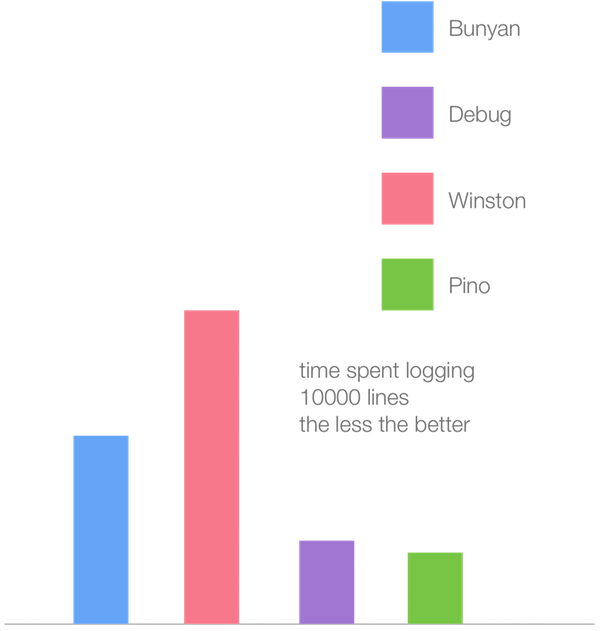
尽管所有的logger基准测试的速度都有所提高(大约是2倍),但是在新的Turbofan JIT编译器中Winston logger的性能提升最明显。这似乎论证了在我们的微基准测试中,从各种不同的方法所看到的速度趋同性:在Crankshaft中速度较慢的方法在Turbofan中明显变快,而在Crankshaft中速度较快的方法在Turbofan中趋近于缓慢。Winston是最慢的,可能在Crankshaft中使用的方法要慢而在Turbofan中则要快一些,而在Crankshaft的方法中Pino被优化为最快。另外我们观察到Pino的速度有提高,但是不明显。
总结
一些基准测试表明,V8 5.1, V8 5.8和5.9中缓慢的情况随着V8 6.0和V8 6.1中Turbofan的全面启用而变得更快,而速度较快的方法其增长速度也会减慢,这通常与缓慢情况的增长速度相匹配。
其中很大一部分是取决于Turbofan(V8 6.0及以上)中函数调用的成本。Turbofan的做法是优化那些常见的场景并消除“V8杀手”。这为浏览器(Chrome)和服务器应用程序(Node)带来了很大的好处。这种权衡(至少在一开始)是在性能最好的情况下会降低速度。我们的logger基准测试对比显示出,Turbofan特性的总体净效应即使在代码基数明显不同的情况下(例如Winston与Pino)也可以全面改善性能。
如果你已经关注JavaScript性能一段时间了,并且为了适应底层引擎的怪异而对编码行为做了调整,那么差不多是时候要去了解一些新的技术了。 如果你专注于最佳实践,希望编写出优秀的JavaScript代码,则要感谢V8团队的不懈努力,对于性能方面的改善即将到来。
本文由David Mark Clements和Matteo Collina撰写,并由V8团队的Franziska Hinkelmann和Benedikt Meurer进行了审阅。
本文的所有源代码以及副本可以查看https://github.com/davidmarkclements/v8-perf
本文的原始数据可以在这里找到:https://docs.google.com/spreadsheets/d/1mDt4jDpN_Am7uckBbnxltjROI9hSu6crf9tOa2YnSog/edit?usp=sharing
大部分微基准测试的运行环境为Macbook Pro 2016,3.3 GHz Intel Core i7,16 GB 2133 MHz LPDDR3,其它如numbers,对象属性移除,多态性,对象创建等部分的微基准测试的运行环境为MacBook Pro 2014,在不同Node.js版本之间的测试是在同一台机器上进行的。 我们很谨慎以确保没有其它程序的干扰。
原文地址:GET READY: A NEW V8 IS COMING, NODE.JS PERFORMANCE IS CHANGING.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号