

Node.js子进程:你想要知道的一切
如何使用spawn(),exec(),execFile()和fork()
对于单进程而言,Node.js的单线程和非阻塞特性表现地非常好。然而,对于处理功能越来越复杂的应用程序而言,一个单进程的CPU是远远无法满足需要的。
无论你的服务器有多强大,单线程都是远远不够用的。
事实上,Node.js的单线程特性并不意味着我们不能将其运行在多线程或者多服务器的环境中。
使用多进程是扩展Node.js应用程序的最佳实践,Node.js就是为构建具有多个节点的分布式应用程序而设计的,这也是它为什么被命名为Node的原因。可伸缩性已经融入到平台中,而不应该在应用程序开发的后期才开始考虑这部分内容。
在阅读本文之前,你可能需要对Node.js的事件和流有一个很好的理解,推荐阅读下面这两篇文章:
child_process模块
通过使用Node.js的child_process模块,我们可以非常轻松地调用子进程,并在各个子进程之间通过消息系统相互通信。
child_process模块使我们可以通过运行在其中的系统命令来访问操作系统的功能。
我们可以控制子进程的输入流,并监听它的输出流。我们还可以控制传递给底层操作系统的命令的参数,并对这些命令的输出做任何我们想做的事情。例如,我们可以将一个命令的输出作为另一个命令的输入(就像我们在Linux系统中做的那样),因为所有这些命令的输入和输出都可以用Node.js流的形式呈现。
注意,本文中所使用的示例都是基于Linux的。在Windows上,你需要将这些命令转换成Windows上对应的部分。
在Node.js中,有四种不同的方式可以用来创建子进程:spawn(),fork(),exec()和execFile()。
接下来让我们看看这四种方法之间的区别以及何时使用它们。
产生一个子进程
spawn函数会创建一个子进程,并在其中执行一个命令,我们可以通过它向该命令传递任何参数。例如,下面的代码创建了一个新的进程并在其中执行pwd命令。
const { spawn } = require('child_process');
const child = spawn('pwd');
我们只需要引入child_process模块,并使用其中的spawn函数,将命令作为第一个参数传入即可执行该命令。
spawn函数(上面代码中的child对象)会返回ChildProcess的一个实例,该实例实现了EventEmitter API,这意味着我们可以直接在它上面注册事件处理程序。例如,我们可以为其注册一个事件,当子进程退出时执行某些操作。
child.on('exit', function (code, signal) {
console.log('child process exited with ' +
`code ${code} and signal ${signal}`);
});
上面的代码提供了子进程退出或者终止时的code和signal。只有当子进程正常退出时,参数signal的值才是null。
我们还可以为ChildProcess实例注册其它事件:disconnect、error、close和message。
- 当在父进程中手动调用child.disconnect函数时,disconnect事件被触发。
- 如果无法创建或终止子进程,error事件被触发。
- 当子进程的stdio流被关闭时,close事件被触发。
- message事件是最重要的一个事件。当子进程使用process.send()函数发送消息时,该事件被触发。父进程和子进程之间通过这种方式相互通信。下面我们会通过一个示例来讲解这部分内容。
每一个子进程都可以通过child.stdin,child.stdout和child.stderr来获取三个标准的stdoi流。
当这些流被关闭时,使用它们的子进程会触发close事件。close事件与exit事件有所不同,因为多个不同的子进程之间可以共享同一个stdio流,所以一个子进程的退出并不意味着其它的流已经关闭。
由于所有的流都是事件发射器,因此我们可以对附加在每个子进程上的stdio流监听不同的事件。但是这与普通的进程不同,在子进程中,stdout/stderr流是可读流,而stdin流是可写流。这与我们在主进程中所遇到的情况正好相反。我们可以为这些流使用的事件都是标准事件。最重要的是,我们可以对可读流监听data事件,其中包含命令的输出或者执行命令时遇到的错误:
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`);
});
child.stderr.on('data', (data) => {
console.error(`child stderr:\n${data}`);
});
上面的两个处理程序将这两种情况的结果记录到主进程的stdout和stderr中。当我们执行上面的spawn函数时,pwd命令的执行结构会被打印出来,然后子进程退出,code的值是0,意思是没有发生任何错误。
我们可以将执行命令时的参数作为调用spawn函数的第二个参数,该参数是一个数组,因此可以将执行命令时的所有参数作为数组的元素传递给spawn函数。例如,要在当前目录中执行find命令(仅列出文件),并使用-type f参数,我们可以这样:
const child = spawn('find', ['.', '-type', 'f']);
如果在执行命令时发生错误,例如上面的例子中如果当前路径无效,则child.stderr data事件将会被触发,同时也会触发exit事件,此时code的值为1,表示有错误发生。错误的值实际上取决于主机操作系统和错误的类型。
子进程stdin是可写流。我们可以使用它向命令发送一些数据。与任何其它的可写流一样,我们可以简单地通过pipe函数来使用它。我们只需要简单地将可读流pipe到可写流。由于主进程stdin是可读流,因此我们可以将其pipe到子进程stdin流中。例如:
const { spawn } = require('child_process');
const child = spawn('wc');
process.stdin.pipe(child.stdin)
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`);
});
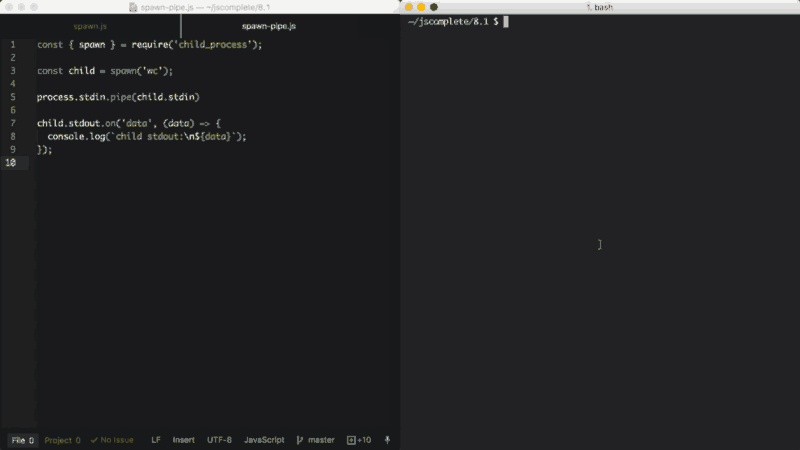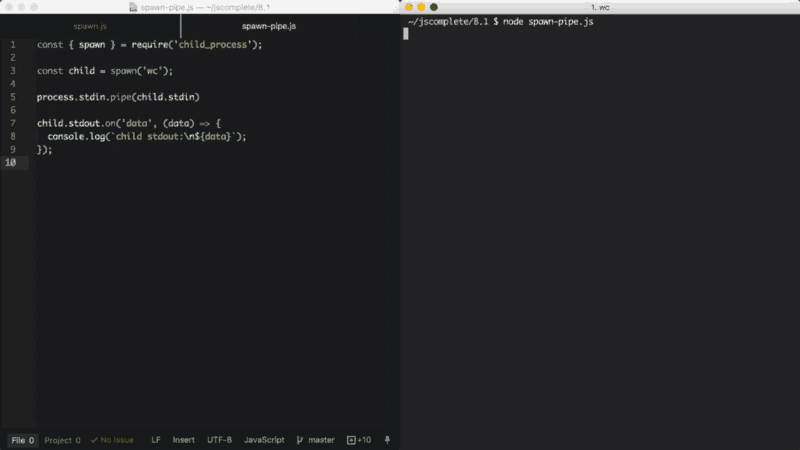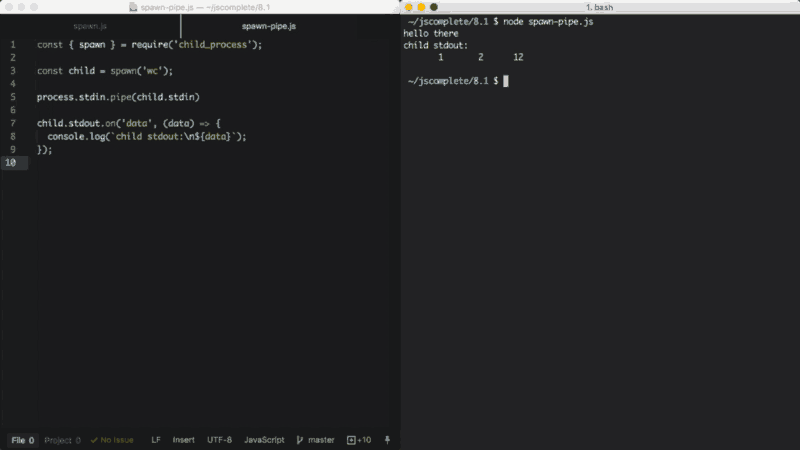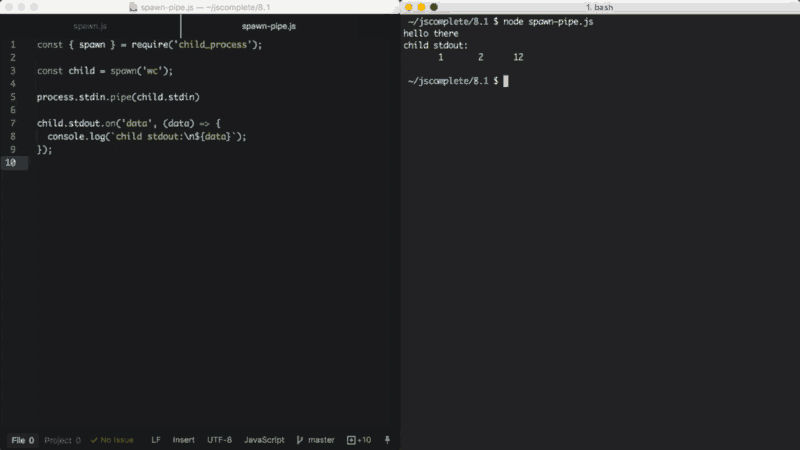
在上面的示例中,子进程调用了wc命令,在Linux中该命令用来计算行数、单词数和字符数。然后,我们将主进程stdio(可读流)pipe到子进程stdin(可写流)中。通过这样的操作,我们可以得到一种标准的输入模式,我们可以输入内容然后通过Ctrl+D将内容传递给wc命令。
我们也可以在多个进程的标准输入/输出流之间使用pipe函数,就像我们在Linux命令行中所使用的那样。例如,我们可以将find命令的stdout通过pipe传给wc命令的stdin,用来对当前目录中的文件进行计数:
const { spawn } = require('child_process');
const find = spawn('find', ['.', '-type', 'f']);
const wc = spawn('wc', ['-l']);
find.stdout.pipe(wc.stdin);
wc.stdout.on('data', (data) => {
console.log(`Number of files ${data}`);
});
我在wc命令后面添加了-l参数,确保只计算文件中内容的行数。运行之后,上述代码将对当前目录下的所有文件进行计数。
Shell语法和exec函数
默认情况下,spawn函数不会创建一个shell来执行我们传给它的命令。这使得它比exec函数效率更高,exec函数会创建shell。与spawn相比,exec函数还有另一个区别,它会缓冲命令的输出,并将整个结果传递给回调函数(而spawn函数则使用流来传递命令的结果)。
下面是我们用exec函数实现的前面find | wc命令的例子。
const { exec } = require('child_process');
exec('find . -type f | wc -l', (err, stdout, stderr) => {
if (err) {
console.error(`exec error: ${err}`);
return;
}
console.log(`Number of files ${stdout}`);
});
因为exec函数使用shell来执行命令,因此我们可以直接在其中使用shell语法pipe来连接两个命令。
注意,如果我们使用从外部动态输入的字符串作为shell语法来执行命令,则可能会带来安全风险。用户可以简单地使用shell语法字符对命令进行注入攻击,例如command + '; rm -rf ~'(这将会删除当前目录下的所有文件)。
exec函数缓冲命令的输出,并将其作为stdout参数传递给回调函数(exec的第二个参数),我们使用该参数打印命令的输出结果。
如果你希望在命令中使用shell语法,并且命令返回的结果数据量很小,那么exec函数是个不错的选择。(请记住,exec在返回结果之前会将整个数据缓冲在内存中。)
当命令返回的结果数据量比较大时,最好使用spawn函数,因为数据将与标准IO对象一起被传递。
如果需要的话,我们可以使产生的子进程继承自父进程的标准IO对象,但更重要的是,我们也可以在spawn函数中使用shell语法。下面是在spawn函数中使用find | wc命令:
const child = spawn('find . -type f | wc -l', {
stdio: 'inherit',
shell: true
});
由于上面代码中的stdio: 'inherit'选项,当我们运行时,子进程会继承主进程的stdin,stdout和stderr。这将导致在主进程的stdout流中触发子进程的数据事件处理程序,从而使脚本立即输出结果。
另外由于上面代码中的shell: true选项,我们可以在传入的命令中使用shell语法,就像我们在exec函数中所做的那样。除此之外,我们仍然能够使用spawn函数数据流的优势。这真是两全其美。
除了shell和stdio这两个选项之外,child_process函数还有一些其它不错的选项。例如,我们可以使用cwd选项来指定当前脚本的工作目录。下面这个例子使用spawn函数对我的用户目录下的Downloads文件夹中的所有文件进行计数。这里的cwd选项指定脚本要计算的文件所在的目录为~/Downloads:
const child = spawn('find . -type f | wc -l', {
stdio: 'inherit',
shell: true,
cwd: '/Users/samer/Downloads'
});
我们可以使用的另一个选项是env,它用来为新产生的子进程指定可用的环境变量。此选项默认为process.env,任何命令都可以访问当前进程的环境变量。如果想要改写环境变量的值,我们可以简单地将一个空对象传递给env选项,或者指定一个新的值作为一个唯一的环境变量:
const child = spawn('echo $ANSWER', {
stdio: 'inherit',
shell: true,
env: { ANSWER: 42 },
});
上面代码中的echo命令无法访问父进程的环境变量。例如,它无法访问$HOME,但是它可以访问$ANSWER,因为我们将$ANSWER通过env选项指定为自定义的环境变量。
最后一个重要的选项是detached,它使子进程独立于父进程运行。
假设我们有一个timer.js文件,它在事件循环中保持运行:
setTimeout(() => { // keep the event loop busy }, 20000);
我们可以使用detached选项让它在后台运行:
const { spawn } = require('child_process');
const child = spawn('node', ['timer.js'], {
detached: true,
stdio: 'ignore'
});
child.unref();
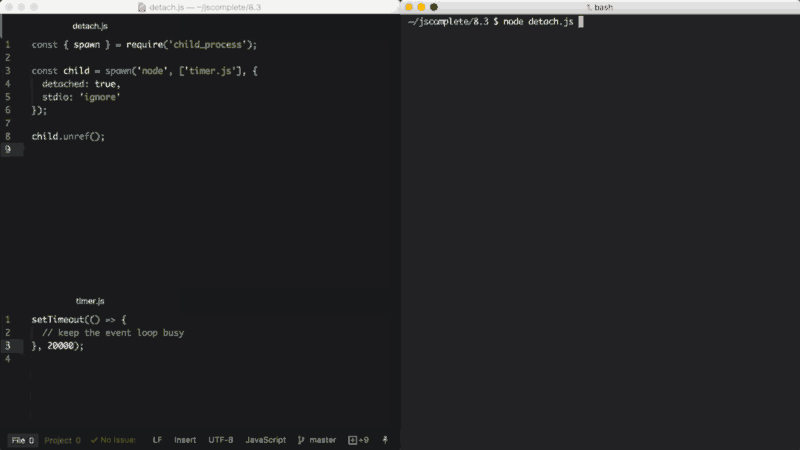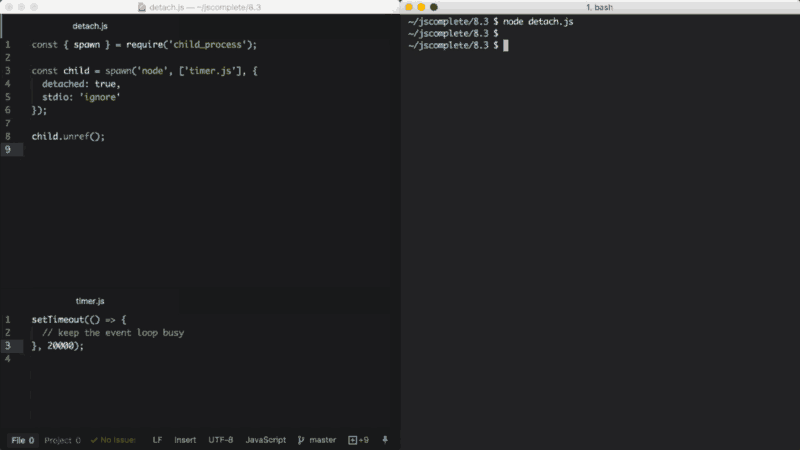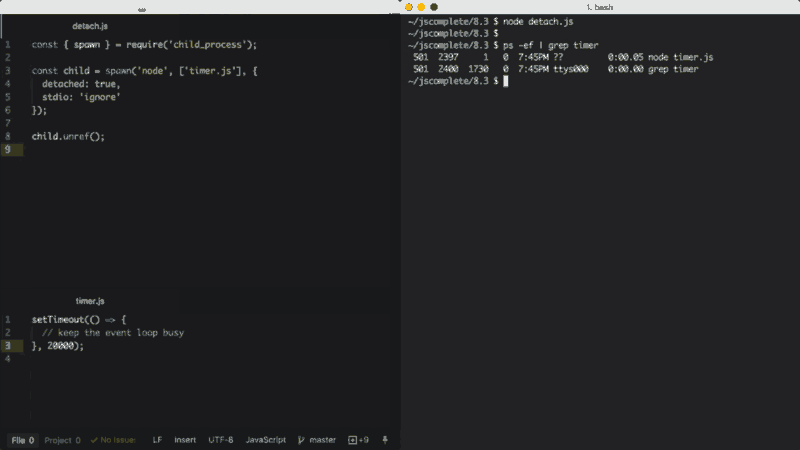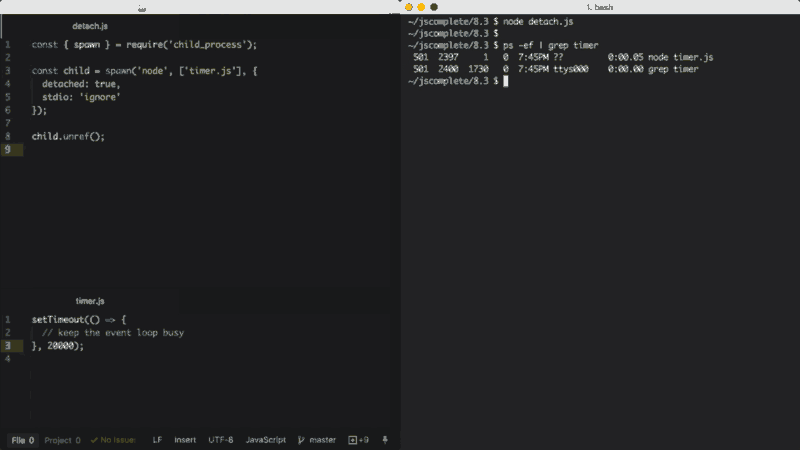
从父进程分离子进程的具体行为取决于操作系统。在Windows中,分离的子进程具有自己独立的的控制台窗口,而在Linux中,分离的子进程会创建一个新的进程组和会话标签。
如果在分离的子进程上调用了unref函数,则父进程可以独立于子进程退出。如果子进程正在执行一个时间比较长的任务,这个功能会很有用。要让子进程在后台保持运行,我们还需要将子进程的stdio选项也配置为独立于父进程。
上面的示例通过分离的子进程在后台执行一个Node脚本(timer.js),并且忽略了父进程的stdio文件描述符,这样当父进程被终止时,子进程仍然可以在后台保持运行。
execFile函数
如果你想在不使用shell的情况下执行一个文件,可以使用execFile函数。它与exec函数的行为完全相同,只是不使用shell,这使得execFile函数的执行效率更高。在Windows中,某些文件无法单独执行,例如.bat或.cmd文件。这些文件不能使用execFile函数执行,不过可以使用exec或spawn函数并将shell选项设置为true来执行它们。
*Sync函数
child_process模块中的spawn,exec和execFile函数都有对应的同步版本,当调用这些函数时,它会阻塞当前程序的执行直到子进程退出才会继续下一步。
const {
spawnSync,
execSync,
execFileSync,
} = require('child_process');
如果你试图简化脚本编写或者执行任何脚本任务,这些同步版本可能会很有用,但应该尽量避免使用它们。
fork()函数
fork函数是spawn函数的变体,它用来产生一个node进程。spawn和fork之间的最大区别在于,当使用fork时,子进程的通信信道会被建立,因此我们可以在子进程中使用send函数与全局对象process一起在父进程和子进程之间交换信息。我们通过EventEmitter模块接口来实现这一操作。下面是具体的例子:
文件parent.js:
const { fork } = require('child_process');
const forked = fork('child.js');
forked.on('message', (msg) => {
console.log('Message from child', msg);
});
forked.send({ hello: 'world' });
文件child.js:
process.on('message', (msg) => {
console.log('Message from parent:', msg);
});
let counter = 0;
setInterval(() => {
process.send({ counter: counter++ });
}, 1000);
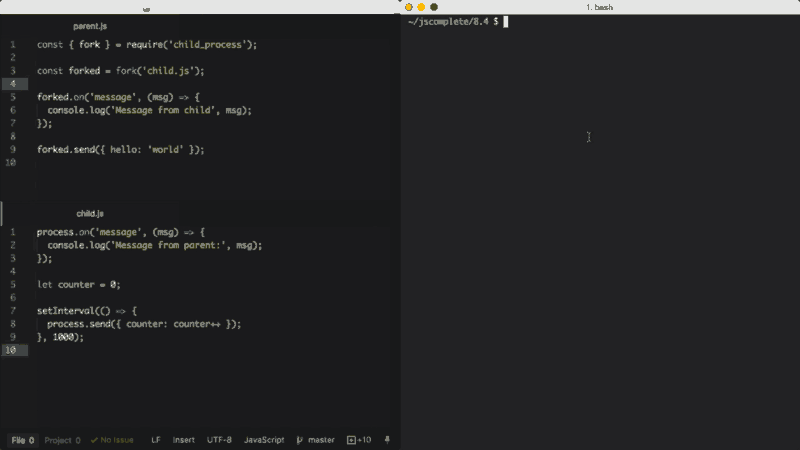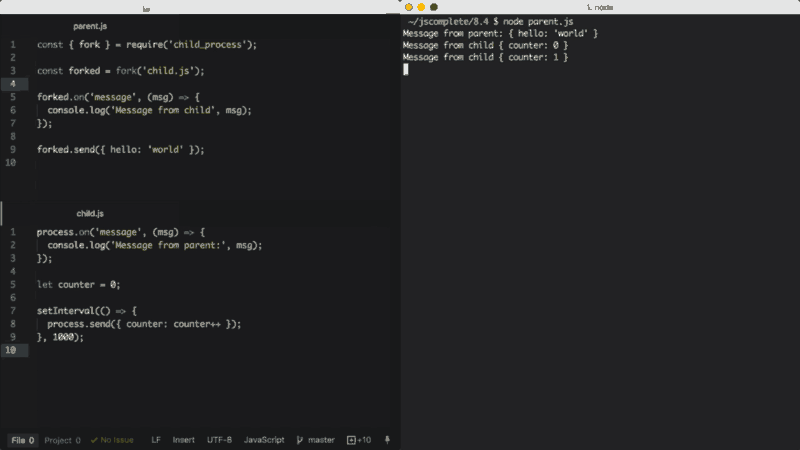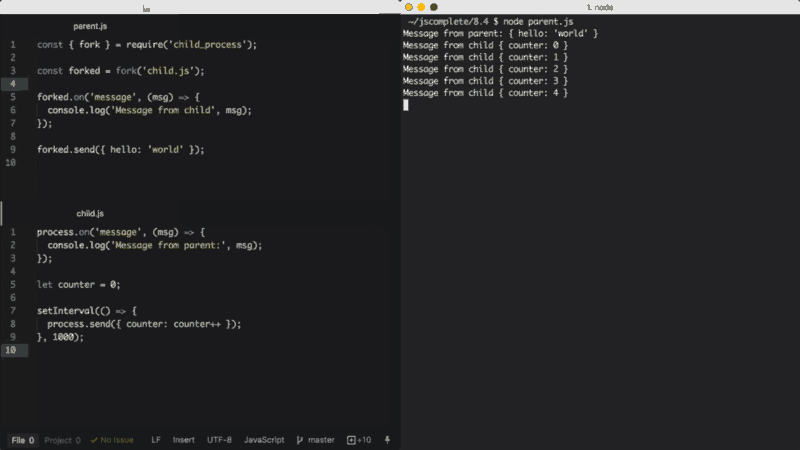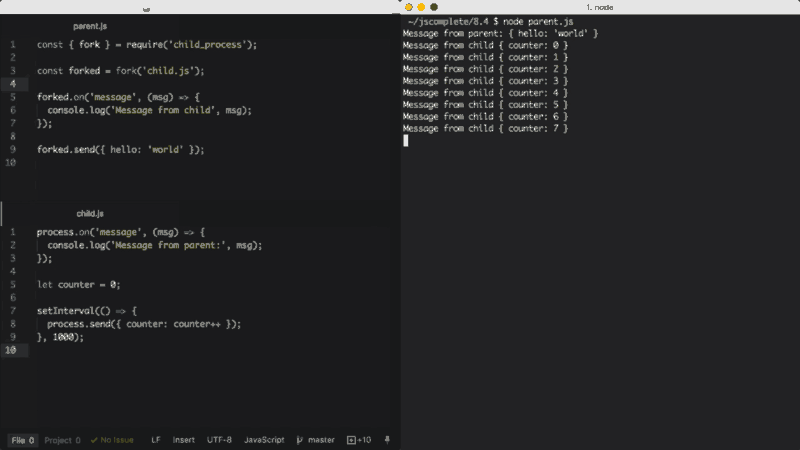
在上面的parent.js文件中,我们fork了child.js(这将使用node命令执行该文件),然后监听message事件。每当child.js使用process.send发送数据时,message事件都会被触发。在child.js中,每隔一秒都会调用process.send方法。
要将消息从parent传递给child,我们可以在对象forked上执行send函数,然后在child.js中,我们监听全局对象process的message事件。
当执行上面程序中的parent.js文件时,它首先向下发送{ hello: 'world' }对象,forked的子进程打印一个消息(Message from parent: { hello: 'world' }),然后child.js将每秒发送一个递增的数值给父进程打印消息(Message from child{ counter: 0 })。
下面让我们来一个有关fork函数的更实际的例子。
假设我们有一个http服务器,用来处理两个endpoint。其中一个endpoint(/compute)耗时较长,它需要几秒钟才能响应。我们可以使用一个长的for循环来模拟它:
const http = require('http');
const longComputation = () => {
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
};
return sum;
};
const server = http.createServer();
server.on('request', (req, res) => {
if (req.url === '/compute') {
const sum = longComputation();
return res.end(`Sum is ${sum}`);
} else {
res.end('Ok')
}
});
server.listen(3000);
这个程序有一个很大的问题。当请求/compute时,由于事件循环忙于处理那个长的for循环操作,因此服务器将无法处理其它的请求。
有几种方法可以解决此问题,不过有一种解决办法适用于所有的操作,我们可以使用fork将计算移至另一个进程中。
首先,我们将整个longComputation函数移至一个新的文件中,并通过主进程的消息来调用该函数:
文件computer.js:
const longComputation = () => { let sum = 0; for (let i = 0; i < 1e9; i++) { sum += i; }; return sum; }; process.on('message', (msg) => { const sum = longComputation(); process.send(sum); });
现在,我们不需要在主进程的事件循环中进行一个很费时的操作,我们可以fork文件compute.js,并使用message接口在服务器和fork的进程之间传递消息。
const http = require('http');
const { fork } = require('child_process');
const server = http.createServer();
server.on('request', (req, res) => {
if (req.url === '/compute') {
const compute = fork('compute.js');
compute.send('start');
compute.on('message', sum => {
res.end(`Sum is ${sum}`);
});
} else {
res.end('Ok')
}
});
server.listen(3000);
当使用上述代码请求/compute时,我们只需要简单地向fork的进程发送一条消息即可执行那个很费时的操作,而主进程的事件循环不会被阻塞。
一旦fork的进程完成了那个很费时的操作,它可以通过process.send将结果发送给主进程。
在父进程中,我们监听fork的进程的message事件。当该事件被触发后,我们获取到sum值,然后通过http返回给请求者。
当然,上面的代码中,我们可以fork的进程的数量是受限制的,但是当我们执行它并通过http请求一个耗时较长的endpoint时,主服务器不会被阻塞从而可以继续响应其它的请求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号