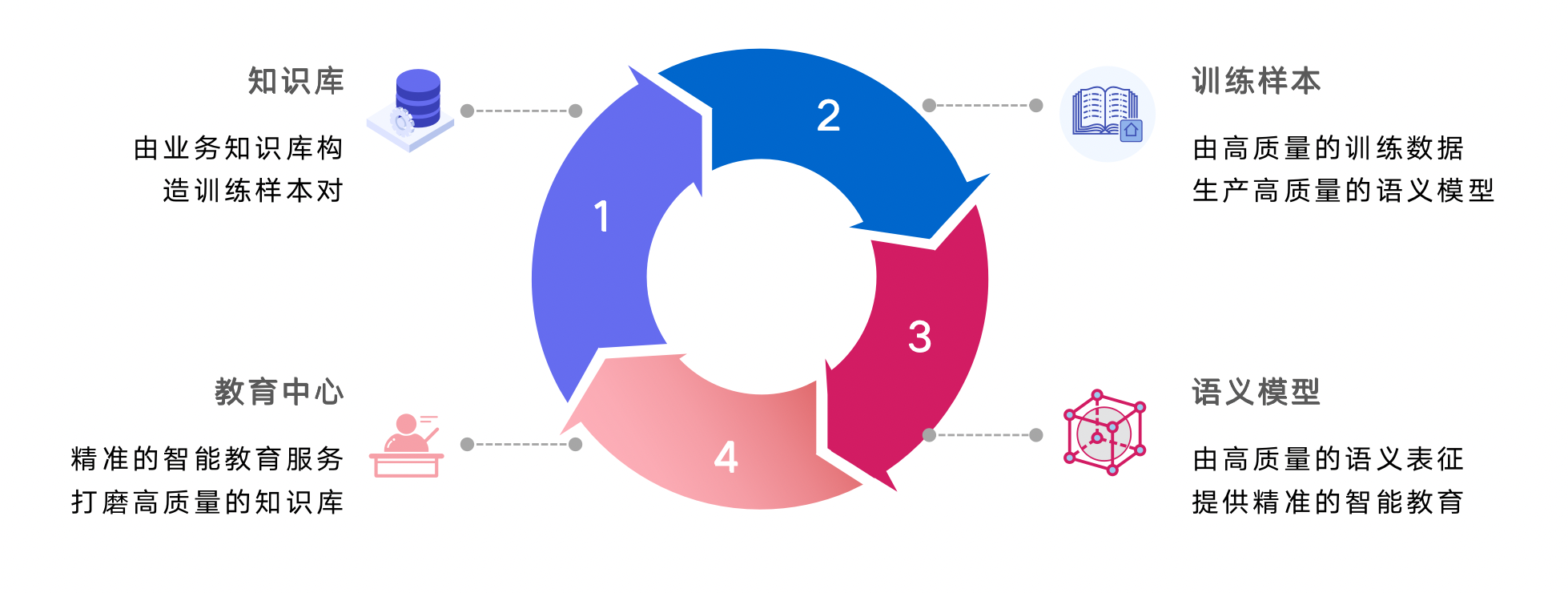
知识库教育中心搭建
一、知识库简介
知识库是QA问答的核心,那知识库的质量怎么保证呢,如下面两幅图所示,该图采用tsne对知识库语意向量降维所得,一种颜色代表一种意图,距离代表相似度,从左图可看出,存在部分意图与其他意图的语意边界混乱的情况,也存在部分意图相似问分布明显可分成两个簇,还有些意图存在大量的相似问与类中心过远,而右图各意图之间分布较为明朗,只存在极少数非同类的说法与相似问距离过近的情况


二、那什么样的知识库是高质量的知识库呢?我认为至少有以下5点要求:
1、知识内容正确,问题的说法表达的意思是该问题,如果某个问题存在不属于该问题的说法,用户问与该说法相似的问题时容易导致误判为该问题,进而错误识别用户意图
2、知识点丰富, 在库问题丰富,尽量覆盖所有日常用户问题 ,尤其是高频问题,如果用户问的问题是在库没有的问题,用户意图要么识别错误,机器人回复答非所问,要么进入兜底逻辑,要么进入猜你想问,给出问题列表,推荐列表可能还是没有用户想问的问题,最终用户诉求都得不到满足
3、知识点内容丰富,相似问丰富,一类问题的问法尽可能全面 ,如果某个问题的问法是在库没有的,或者该问题在库说法太少,同样会导致应该判为该意图的说法误判为其他意图
4、知识边界清晰,不同问题间的说法边界清晰,如果两个问题的说法不够清晰,也不存在判断优先级,当用户问法处在语义边界时,同样容易导致误判,机器人回答不够有针对性
5、知识粒度细腻 ,问题本身得够具体,问题答案要有针对性,知识库创建过程中通常需要对问题进行归类。然后对大类进行细化分类,否则将导致回答需要进行分类且概括所有情况举个例子,而对于用户问的比较笼统的说法,可以用多轮交互的方式确定用户真实的意图
三、如何保障知识库质量呢?我们可针对以上5种要求进行算法开发;
1、知识内容正确:开发语料清洗功能,定期对问题的相似问清洗,找出两种离群点,第一种是与类中心过远的相似问。第二种是与其他意图相似问更近的相似问
2、知识点丰富:对于与在库所有意图相似度都不够高的说法进行聚类,挖掘新类别,聚类特征可以是字词特征if_idf,bm25或者其他度量特征,也可以用语意向量进行相似度聚类,或者用混合特征,聚类算法demo可参考https://www.cnblogs.com/jax-/p/17664998.html
3、知识点内容丰富:对于用户根据相似度判为某意图的相似问,如果不在库,根据相似度进行推荐增加至知识库中,相似度不宜过高或者过低,对于相似问过少或新增的意图需重点处理
4、知识边界清晰:找出在库非同类意图但是相似度过近的相似问,推荐给专家进行处理,可进行相似问转移、相似问删除、意图合并、意图确认等操作,需根据歧义度口径进行设计
5、知识粒度细腻:找出说法过多且聚类后质心距离较大,而类间距比较小的意图,推荐给专家进行研判是否分裂意图,这里可用轮廓系数来度量
知识库建设是QA问答领域核心的问题,教育中心除了可以辅助建设知识库提升知识库质量以外,知识库又可以生成训练样本用以模型训练,训练后的模型又能重新用于教育中心,是相辅相成的关系