triton与paddlespeech部署ASR服务的性能对比
一、背景
最近在进行asr部署方案的技术选型工作,主要对比了triton部署与paddle部署两种方案
triton方案链接:https://github.com/wenet-e2e/wenet/tree/main/runtime/gpu
paddlespeech方案链接:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/streaming_asr_server/README_cn.md
二、测试环境
1、硬件环境:GPU下双卡V100,每张卡显存32G
2、测试数据下载: https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/aishell_test.zip
3、软件环境:triton采用docker部署,paddlespeech采用conda环境
a、paddle环境
python 3.8.12
paddle2onnx 1.0.5
paddleaudio 1.1.0
paddlepaddle-gpu 2.4.1
paddlespeech 最新版本
b、triton环境 python 3.8.10
torch 2.0.1
torchaudio 2.0.2
triton 2.0.0
tritionclient 2.34.0
4、模型部署方法:算法是线上双方均使用chunk_conformer模型,其中paddlespeech部署的是动态图,单线程方案无任何改动,多线程方案基于对paddlespeech项目进行修改支持多线程部署,之所以采用动态图部署主要是因为在项目中未找到部署静态图模型的方法,而triton部署的是静态图,同时模型转成了ONNX格式,使用了triton推理加速
三、测试方法与详情
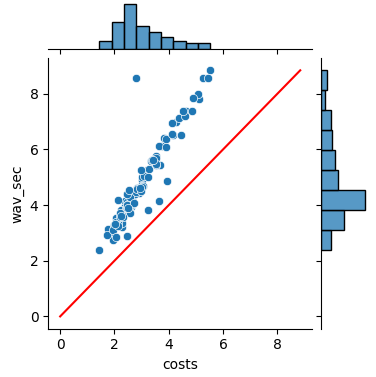
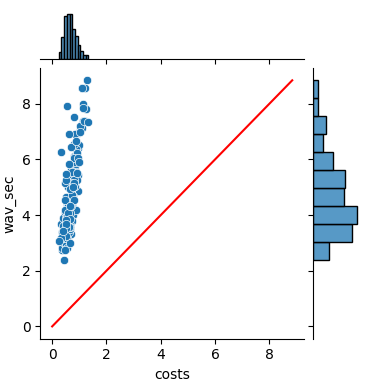
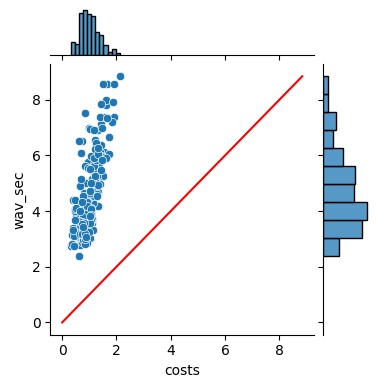
1、paddlespeech 单个服务进程,横坐标为处理语音花费的时间,纵坐标为语音本身的市场,根据paddlespeech 的服务流程,下图只是计算特征提取,encoder,ctcdecoder部分的推理时长,语音终止之后服务端接受到end信号时,运行attention_rescore,该步骤花费的时间大约还需350ms,aishell TOP100语音一共总时长484秒,左图为5个并发请求时的,右图为10个并发时的,推理时间分布,两者耗时均在70s左右左图RTF均小于1,满足实时要求,右图不满足,服务花费大约2G的显存,GPU使用率最高达到18%


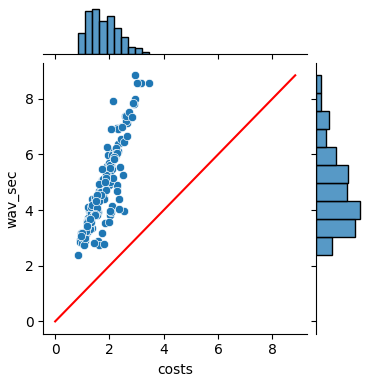
2、当使用GPU双卡,每张卡启动10个进程服务时,客户端分别为20个进程和30个进程时的推理时间分布情况,TOP180语音总时长为855秒,总花费时长均在31秒左右,但是当请求进程数达到30时,存在一些线程的RTF会大于1,不满足实时性能要求,且gpu使用率均达到100%,占用显存存较多,每张卡大约24g显存,可见服务进程数并没有与并发能力有线性关系,具体瓶颈博主还在分析中
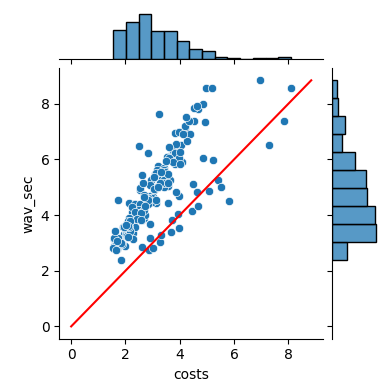
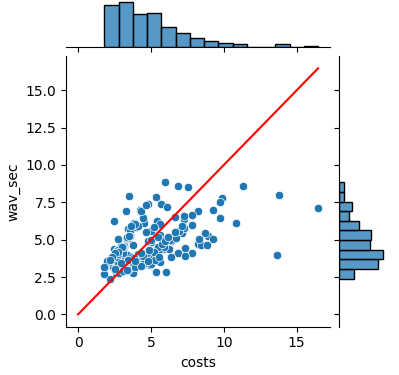
3、使用triton方案部署服务后,以TOP800语音文件,以下分别为60,80,200个进程同时请求的情况下的推理时间分布,均能满足实时要求,推理过程中GPU的使用率大约在60%左右,性能相对较好,静态图相比于动态图推理速度确实快上



 浙公网安备 33010602011771号
浙公网安备 33010602011771号