基于知识库的智能问答系统搭建
一、问答机器人介绍
智能问答中最重要得到模块就是要理解用户的咨询意图,并给出专业的咨询回复,结合业务知识库或者知识图谱,应用到不同的业务中去,以低成本的智能客服替代人工服务,满足客户咨询诉求,根据对话伦次可分为单轮FAQ问答式机器人,基于业务规则的多轮对话机器人,基于前文理解的多轮对话机器人等,比如很火的chatgpt就是能结合前文信息的生成式问答,生成式问答存在生成内容不可控的问题,这里暂且不表,主要介绍基于知识库的问答,该技术也可用于智能客服、智能催收、智能电销等业务中
二、算法选型
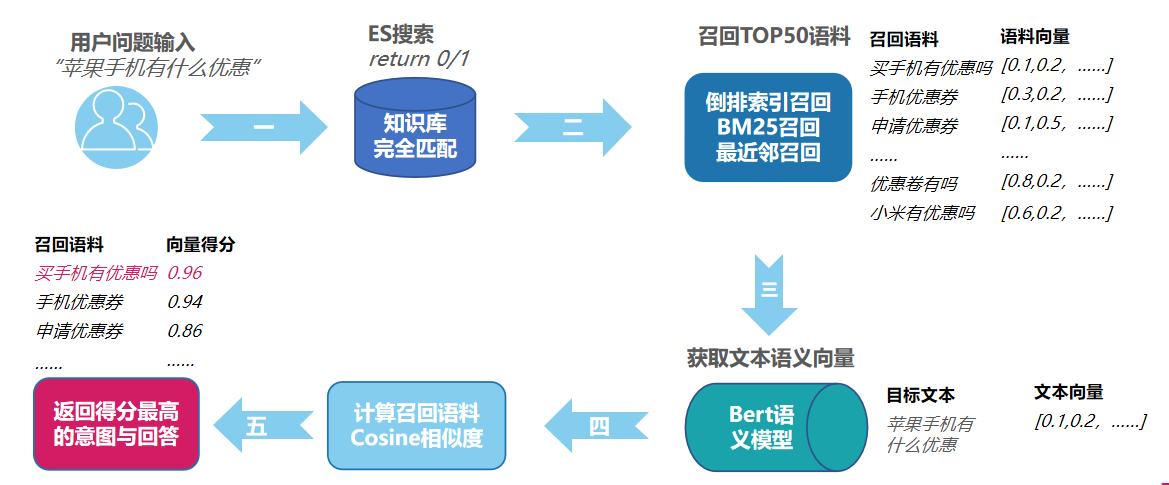
1、要识别用户的意图可以采用分类算法或者相似比对算法,到底采用分类还是比对,分类算法最致命的问题是,模型训练时,训练Y标是定下来的,每次Y标修改,必须重新训练迭代模型,因此基于相似比对算法来做意图识别通常更符合业务诉求,采用比对算法的问题主要是在库需要比对的数据或者文本过于庞大,消耗计算资源过大,通常的做法是先做一层或者多层的召回,再进行精细化的比对,只要召回算法够高效,既可以节约大量计算时间和成本,又不影响整体效果。
2、文本领域常用的有倒排索引召回,TF_IDF召回,annoy语义召回,BM25召回以及混合召回等,基于多次效果和性能上的考量,最终选用了BM25召回,选用它的还有一大好处就是Elasticsearch 7.9.0 版本中,引入了一个名为 "rank_feature" 的字段类型,它使用 BM25 相似性评分模型进行召回,经过BM25召回后,再接入语义比对模型进行精细相似度打分
3、比对模型,在文本领域也叫语义模型,这里通常会使用Siamese网络,基模型可采用textcnn、bert、albert等模型来进行语义模型的训练与比对,基于效果和性能的考量,个人推荐采用bert模型,当然也可以根据数据量与业务场景灵活选择.
4、sentence-bert是对预训练 BERT网络 的一种改进,该网络使用孪生网络或者三元组网络结构,来推导语义上有意义的句子向量表征,语义模型训练与比对模型类似,同类样本交叉可产生正样本对,不同类样本组成负类样本对,当然也可采用三元组样本,只是损失函数需修改为triplet loss,语义模型训练的目标是获取一个鲁棒性够高,在业务数据上AUC够高的模型,为提高性能,可考虑以下几点方案:
a、利用教育中心打磨业务知识库,明确不同意图的语义边界,丰富说法与意图,同时对训练样本进行合理筛选
b、选用一个合适预训练模型,博主目前采用macbertMacbert 是一种改进的BERT,它采用了比较前沿的MLM掩码技术来校正预训练任务,同时采用Synonyms 工具包 来做样本增强。它减轻了预训练和微调的差异,多次实验表明,采用Macbert来做基础模型进行fine-tune,效果比原生Bert更好,鲁棒性更强
c、寻找更多同领域数据,语义模型的训练数据不是越多越好,不同类别之间的正负规范越接近越好,例如金融领域内拿医疗领域样本就不合适,"你是神经病"和"你是精神病"在金融领域可能都是骂人,但在医疗领域是不同的意图
5、意图识别流程设计:
三、技术选型:
Elasticsearch 从版本 7.10.0 开始引入了向量计算的能力。新的向量数据类型(vector data type)和相应的查询语法使得可以在 Elasticsearch 中存储和操作向量数据。这使得可以执行类似于余弦相似度等向量计算。
该特性使得采用Elasticsearch比mysql多了相似度计算能力, 比milvus多了文本召回能力,比采用内存存储如annoy索引树又多了可热更新与持久化的能力,所以存储方案上,采用Elasticsearch 成了最优的选择
,采用Elasticsearch还可以进行BM25参数的调整、向量点积的计算,大幅降低机器人代码耦合度与逻辑计算量,还可以按需进行多条件的筛选,通过向量冗余存储,还可以灵活调整所需要的语义模型版本,实现业务无感知的模型迭代,同时可以通过API实现业务知识库的热更新
1、服务解耦:经过服务解耦设计,智能客服核心的服务组件可拆成ES服务、bert embedding服务、机器人服务,教育中心服务,监控服务四大模型,各服务模块采用
a、ES服务:ES服务主要用于存储知识库、文本召回、向量点积计算、知识库更新、数据匹配等,是智能客服中的核心组件,服务搭建部署可参考:https://www.cnblogs.com/jax-/p/17647888.html
b、embedding服务:主要用于快速计算query文本的embedding,用于文本召回后的点积计算:服务搭建部署可参考:https://www.cnblogs.com/jax-/p/17647991.html
c、机器人服务:机器人逻辑主服务,可实现机器人选择,语义模型选择,不同业务机器人规则筛选等
d、教育中心服务:教育中心服务是用于提升知识库质量的一系列推荐服务,旨在提升知识库完善度与质量
e、监控服务:监控服务主要用于监控各模块服务是否正常,性能是否已到瓶颈,异常时发出告警等
2、部署方案:经过不同技术框架的比对选型,结合业务数据分析,最终采用了容器化部署方案,采用docker或者docker-composer容器,容器化部署有以下几点优势
a、轻量化和可移植性:容器化将应用程序及其依赖项打包为独立的容器,使其在不同的环境中可以轻松部署和运行。容器是轻量级的,与宿主操作系统共享内核,因此更加高效,并且可以在不同的平台上运行,提供了高度的可移植性。
b、快速部署和扩展:容器可以快速启动和停止,使得应用程序的部署和扩展变得更加简单和迅速。容器化应用程序可以根据需求进行水平扩展,即增加或减少容器的数量,以适应流量的变化,实现更好的弹性和灵活性。
c、隔离和安全性:每个容器都是相互隔离的运行单元,具有自己的文件系统、进程和网络空间。这种隔离能力提供了更高的安全性,因为容器之间无法直接访问彼此的资源,减少了潜在的攻击面。
d、简化依赖管理:通过容器化,可以将应用程序及其所有依赖项打包在一起。这样,开发人员可以轻松地管理和维护应用程序所需的特定版本的库、工具和配置,减少了依赖冲突和环境配置问题。
e、可重复部署:使用容器镜像可以确保在不同的环境中以相同的方式部署应用程序,消除了部署过程中的配置差异和兼容性问题。这种可重复性简化了开发、测试和生产环境之间的迁移和部署。
f、简化持续集成和交付:容器化使得实现持续集成和持续交付(CI/CD)变得更加容易。通过将容器作为构建和交付的基本单位,可以快速构建、测试和部署应用程序,并且容器的可移植性和隔离性使得持续集成和交付流程更加稳定和可靠
四、模型上线与迭代
基于知识库的意图识别效果严重依赖知识库的质量,成熟的知识库能拦截90%以上的访问流量,既用户的query进入规则层后与在库说法完全匹配的概率超过90%,同时bert模型的训练通常需要一天以上,所以优化工作的重心之一是打磨知识库
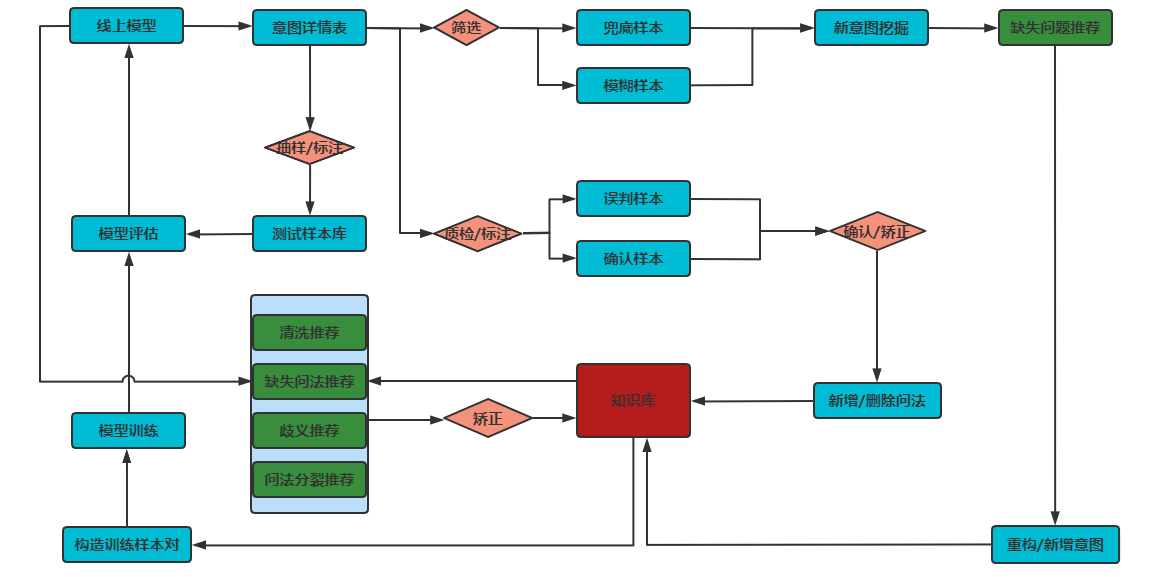
基于此,开发了智能教育模块用于辅助优化知识库,总体设计方案如下图所示,具体详情可参考连接:https://www.cnblogs.com/jax-/p/17681932.html