机器学习(ML)十六之目标检测基础
目标检测和边界框
在图像分类任务里,我们假设图像里只有一个主体目标,并关注如何识别该目标的类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。
目标检测在多个领域中被广泛使用。例如,在无人驾驶里,我们需要通过识别拍摄到的视频图像里的车辆、行人、道路和障碍的位置来规划行进线路。机器人也常通过该任务来检测感兴趣的目标。安防领域则需要检测异常目标,如歹徒或者炸弹。
边界框
在目标检测里,我们通常使用边界框(bounding box)来描述目标位置。边界框是一个矩形框,可以由矩形左上角的x和y轴坐标与右下角的x和y轴坐标确定。我们根据坐标信息来定义图中物体的边界框。图中的坐标原点在图像的左上角,原点往右和往下分别为x轴和y轴的正方向。
- 在目标检测里不仅需要找出图像里面所有感兴趣的目标,而且要知道它们的位置。位置一般由矩形边界框来表示。
锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。我们将在后面基于锚框实践目标检测。
生成多个锚框

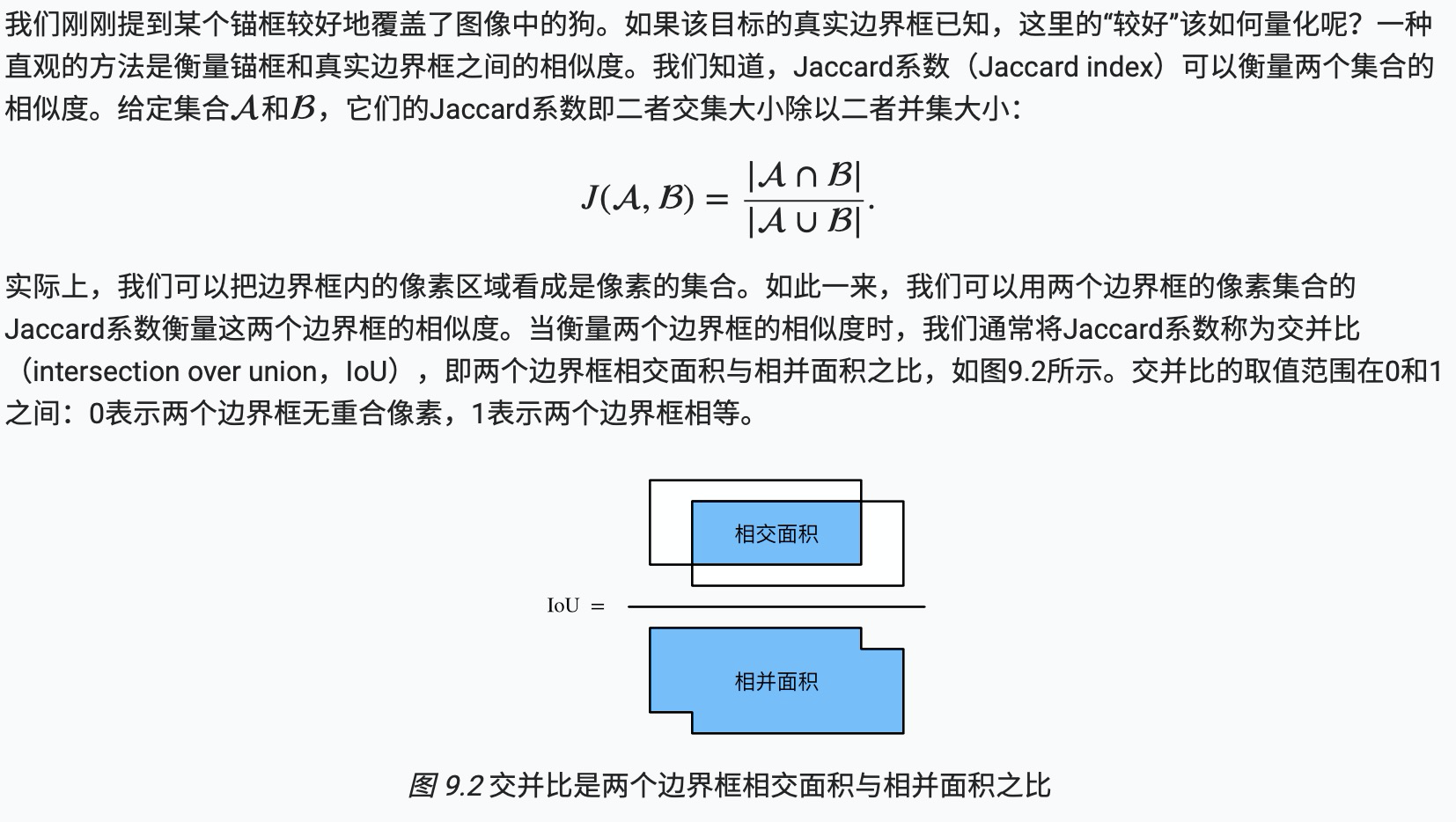
交并比
标注训练集的锚框

输出预测边界框
在模型预测阶段,我们先为图像生成多个锚框,并为这些锚框一一预测类别和偏移量。随后,我们根据锚框及其预测偏移量得到预测边界框。当锚框数量较多时,同一个目标上可能会输出较多相似的预测边界框。为了使结果更加简洁,我们可以移除相似的预测边界框。常用的方法叫作非极大值抑制(non-maximum suppression,NMS)。
我们来描述一下非极大值抑制的工作原理。对于一个预测边界框B,模型会计算各个类别的预测概率。设其中最大的预测概率为p,该概率所对应的类别即B的预测类别。我们也将p称为预测边界框B的置信度。在同一图像上,我们将预测类别非背景的预测边界框按置信度从高到低排序,得到列表L。从L中选取置信度最高的预测边界框B1作为基准,将所有与B1的交并比大于某阈值的非基准预测边界框从L中移除。这里的阈值是预先设定的超参数。此时,L保留了置信度最高的预测边界框并移除了与其相似的其他预测边界框。 接下来,从L中选取置信度第二高的预测边界框B2作为基准,将所有与B2的交并比大于某阈值的非基准预测边界框从L中移除。重复这一过程,直到L中所有的预测边界框都曾作为基准。此时LL中任意一对预测边界框的交并比都小于阈值。最终,输出列表L中的所有预测边界框。
实践中,我们可以在执行非极大值抑制前将置信度较低的预测边界框移除,从而减小非极大值抑制的计算量。我们还可以筛选非极大值抑制的输出,例如,只保留其中置信度较高的结果作为最终输出。
- 以每个像素为中心,生成多个大小和宽高比不同的锚框。
- 交并比是两个边界框相交面积与相并面积之比。
- 在训练集中,为每个锚框标注两类标签:一是锚框所含目标的类别;二是真实边界框相对锚框的偏移量。
- 预测时,可以使用非极大值抑制来移除相似的预测边界框,从而令结果简洁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号