机器学习(ML)十二之编码解码器、束搜索与注意力机制
编码器—解码器(seq2seq)
在自然语言处理的很多应用中,输入和输出都可以是不定长序列。以机器翻译为例,输入可以是一段不定长的英语文本序列,输出可以是一段不定长的法语文本序列,例如
英语输入:“They”、“are”、“watching”、“.”
法语输出:“Ils”、“regardent”、“.”
当输入和输出都是不定长序列时,我们可以使用编码器—解码器(encoder-decoder)或者seq2seq模型。这两个模型本质上都用到了两个循环神经网络,分别叫做编码器和解码器。编码器用来分析输入序列,解码器用来生成输出序列。用编码器—解码器将上述英语句子翻译成法语句子的一种方法。在训练数据集中,我们可以在每个句子后附上特殊符号“<eos>”(end of sequence)以表示序列的终止。编码器每个时间步的输入依次为英语句子中的单词、标点和特殊符号“<eos>”。下图中使用了编码器在最终时间步的隐藏状态作为输入句子的表征或编码信息。解码器在各个时间步中使用输入句子的编码信息和上个时间步的输出以及隐藏状态作为输入。 我们希望解码器在各个时间步能正确依次输出翻译后的法语单词、标点和特殊符号“<eos>”。 需要注意的是,解码器在最初时间步的输入用到了一个表示序列开始的特殊符号“<bos>”(beginning of sequence)。
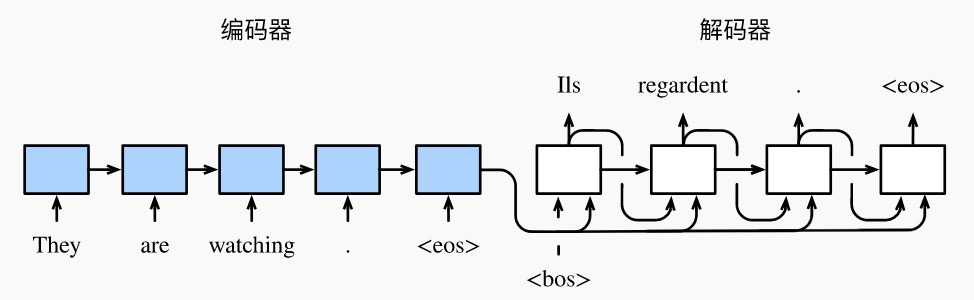
编码器

解码器

训练模型

在模型训练中,所有输出序列损失的均值通常作为需要最小化的损失函数。在上图所描述的模型预测中,我们需要将解码器在上一个时间步的输出作为当前时间步的输入。与此不同,在训练中我们也可以将标签序列(训练集的真实输出序列)在上一个时间步的标签作为解码器在当前时间步的输入。这叫作强制教学(teacher forcing)。
- 编码器-解码器(seq2seq)可以输入并输出不定长的序列。
- 编码器—解码器使用了两个循环神经网络。
- 在编码器—解码器的训练中,可以采用强制教学。
束搜索
在准备训练数据集时,我们通常会在样本的输入序列和输出序列后面分别附上一个特殊符号“<eos>”表示序列的终止。我们在接下来的讨论中也将沿用上一节的全部数学符号。为了便于讨论,假设解码器的输出是一段文本序列。设输出文本词典y包含特殊符号“<eos>”)的大小为|y|,输出序列的最大长度为T',所有可能的输出序列一共有O(|Y|T′)种。这些输出序列中所有特殊符号“<eos>”后面的子序列将被舍弃。
贪婪搜索

穷举搜索

束搜索
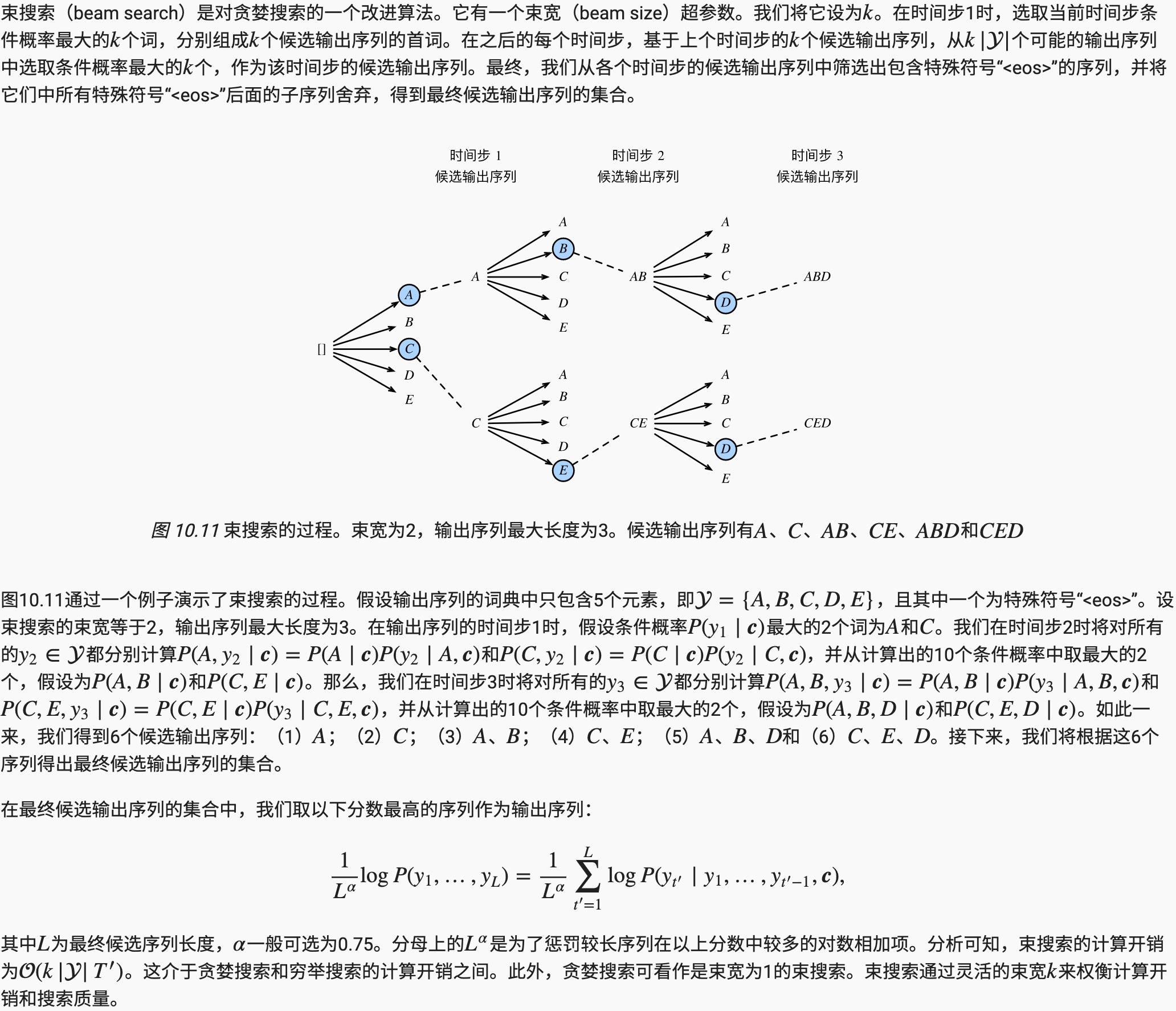
- 预测不定长序列的方法包括贪婪搜索、穷举搜索和束搜索。
- 束搜索通过灵活的束宽来权衡计算开销和搜索质量。
注意力机制
在“编码器—解码器(seq2seq)”里,解码器在各个时间步依赖相同的背景变量来获取输入序列信息。当编码器为循环神经网络时,背景变量来自它最终时间步的隐藏状态。
让我们再次思考那一节提到的翻译例子:输入为英语序列“They”“are”“watching”“.”,输出为法语序列“Ils”“regardent”“.”。不难想到,解码器在生成输出序列中的每一个词时可能只需利用输入序列某一部分的信息。例如,在输出序列的时间步1,解码器可以主要依赖“They”“are”的信息来生成“Ils”,在时间步2则主要使用来自“watching”的编码信息生成“regardent”,最后在时间步3则直接映射句号“.”。这看上去就像是在解码器的每一时间步对输入序列中不同时间步的表征或编码信息分配不同的注意力一样。这也是注意力机制的由来。
仍然以循环神经网络为例,注意力机制通过对编码器所有时间步的隐藏状态做加权平均来得到背景变量。解码器在每一时间步调整这些权重,即注意力权重,从而能够在不同时间步分别关注输入序列中的不同部分并编码进相应时间步的背景变量。
计算背景变量
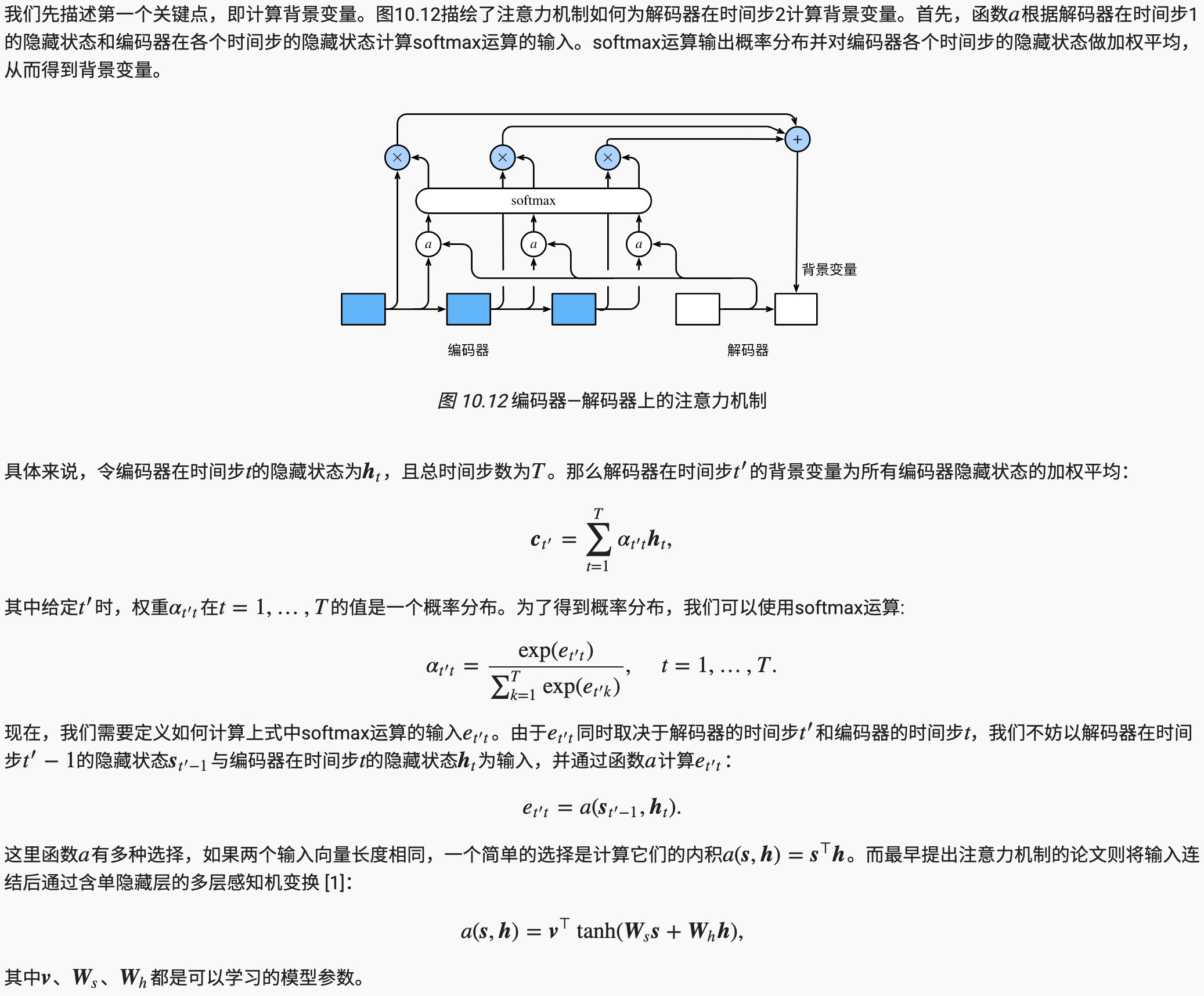
矢量化计算

更新隐藏状态
现在我们描述第二个关键点,即更新隐藏状态。以门控循环单元为例,在解码器中我们可以对“门控循环单元(GRU)”一节中门控循环单元的设计稍作修改,从而变换上一时间步t′−1的输出yt′−1、隐藏状态st′−1和当前时间步t′的含注意力机制的背景变量ct′。解码器在时间步:math:t’的隐藏状态为
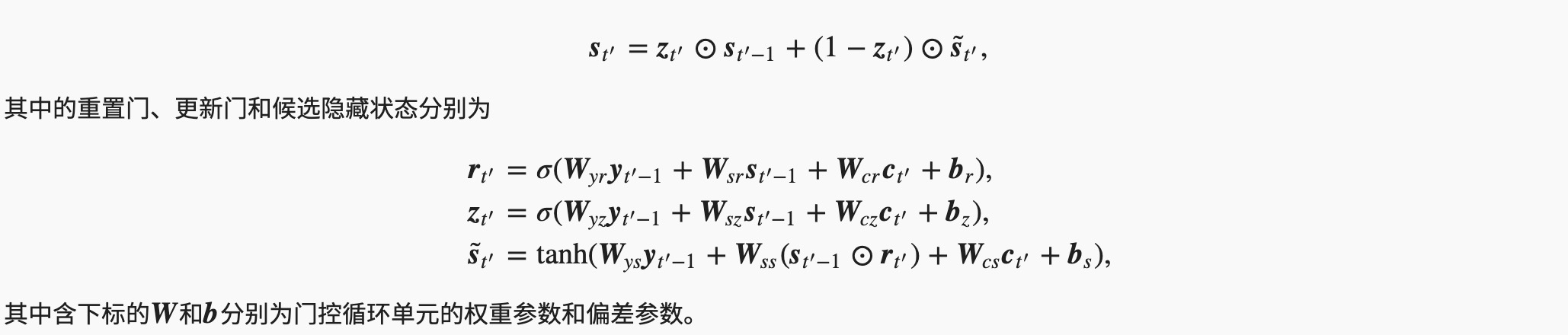
发展
本质上,注意力机制能够为表征中较有价值的部分分配较多的计算资源。这个有趣的想法自提出后得到了快速发展,特别是启发了依靠注意力机制来编码输入序列并解码出输出序列的变换器(Transformer)模型的设计。变换器抛弃了卷积神经网络和循环神经网络的架构。它在计算效率上比基于循环神经网络的编码器—解码器模型通常更具明显优势。含注意力机制的变换器的编码结构在后来的BERT预训练模型中得以应用并令后者大放异彩:微调后的模型在多达11项自然语言处理任务中取得了当时最先进的结果。不久后,同样是基于变换器设计的GPT-2模型于新收集的语料数据集预训练后,在7个未参与训练的语言模型数据集上均取得了当时最先进的结果 [4]。除了自然语言处理领域,注意力机制还被广泛用于图像分类、自动图像描述、唇语解读以及语音识别。
- 可以在解码器的每个时间步使用不同的背景变量,并对输入序列中不同时间步编码的信息分配不同的注意力。
- 广义上,注意力机制的输入包括查询项以及一一对应的键项和值项。
- 注意力机制可以采用更为高效的矢量化计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号