机器学习(ML)九之GRU、LSTM、深度神经网络、双向循环神经网络
门控循环单元(GRU)
循环神经网络中的梯度计算方法。当时间步数较大或者时间步较小时,循环神经网络的梯度较容易出现衰减或爆炸。虽然裁剪梯度可以应对梯度爆炸,但无法解决梯度衰减的问题。通常由于这个原因,循环神经网络在实际中较难捕捉时间序列中时间步距离较大的依赖关系。
门控循环神经网络(gated recurrent neural network)的提出,正是为了更好地捕捉时间序列中时间步距离较大的依赖关系。它通过可以学习的门来控制信息的流动。其中,门控循环单元(gated recurrent unit,GRU)是一种常用的门控循环神经网络。
门控循环单元
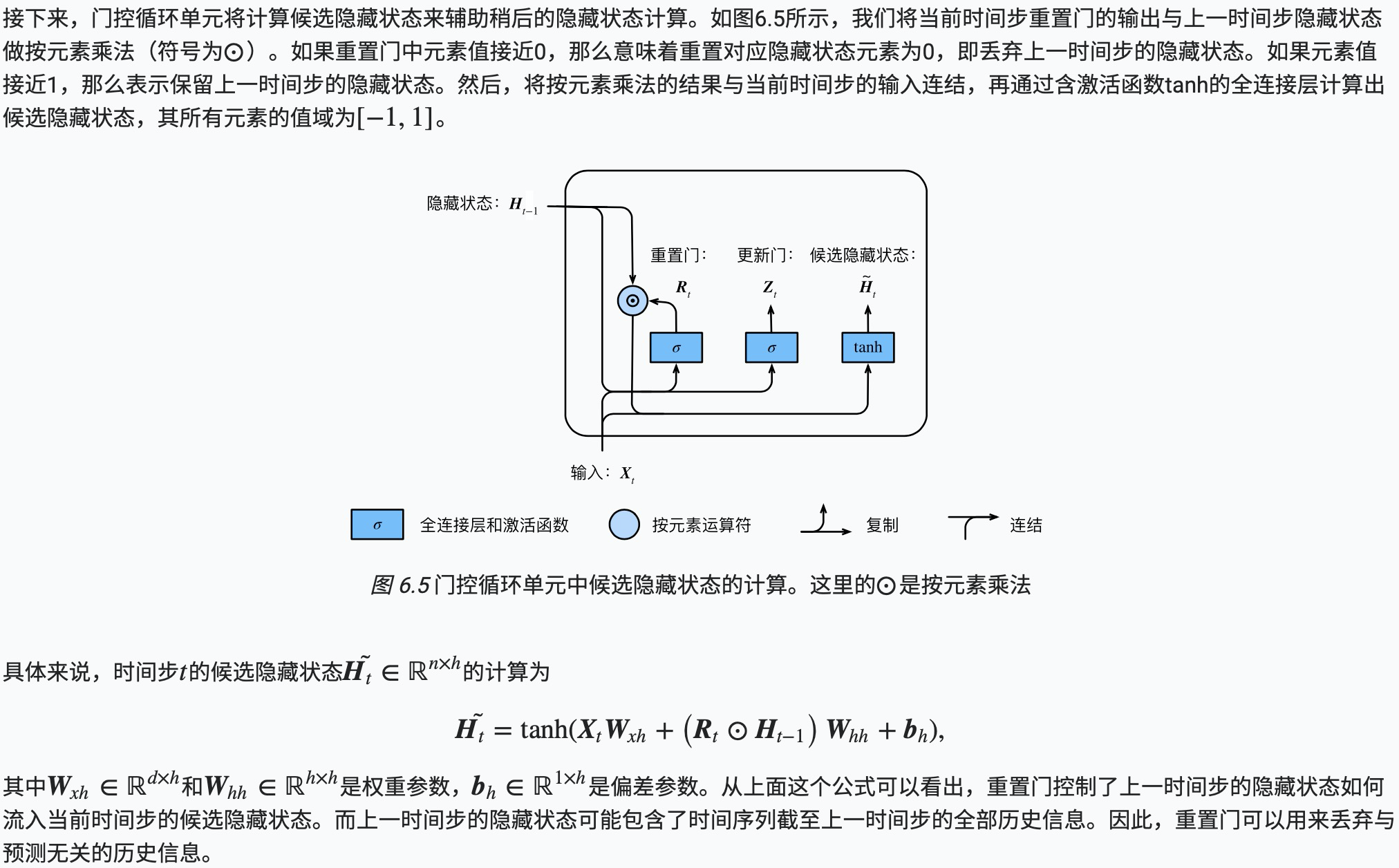
门控循环单元的设计。它引入了重置门(reset gate)和更新门(update gate)的概念,从而修改了循环神经网络中隐藏状态的计算方式。
重置门和更新门
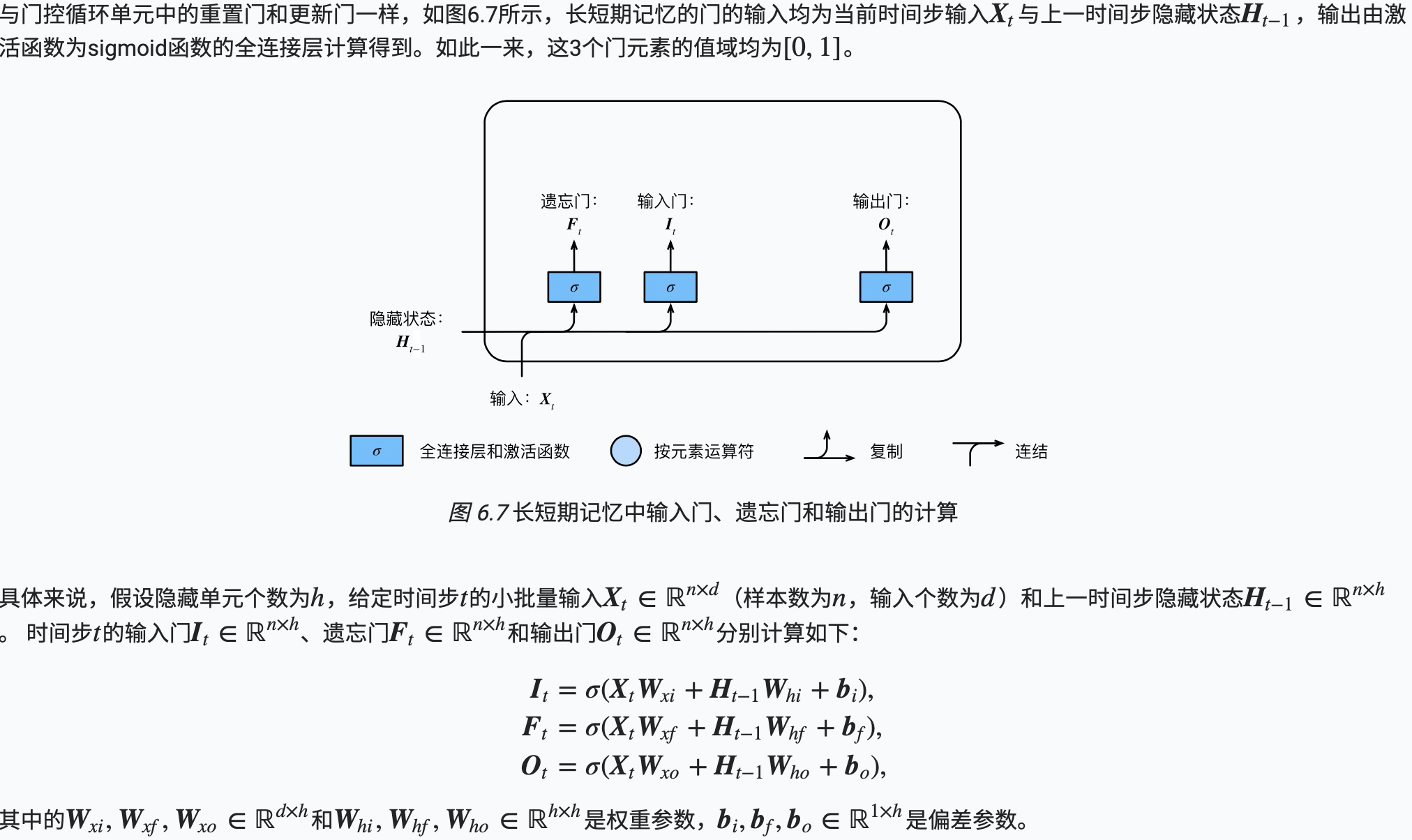
门控循环单元中的重置门和更新门的输入均为当前时间步输入Xt与上一时间步隐藏状态Ht−1,输出由激活函数为sigmoid函数的全连接层计算得到。

候选隐藏状态
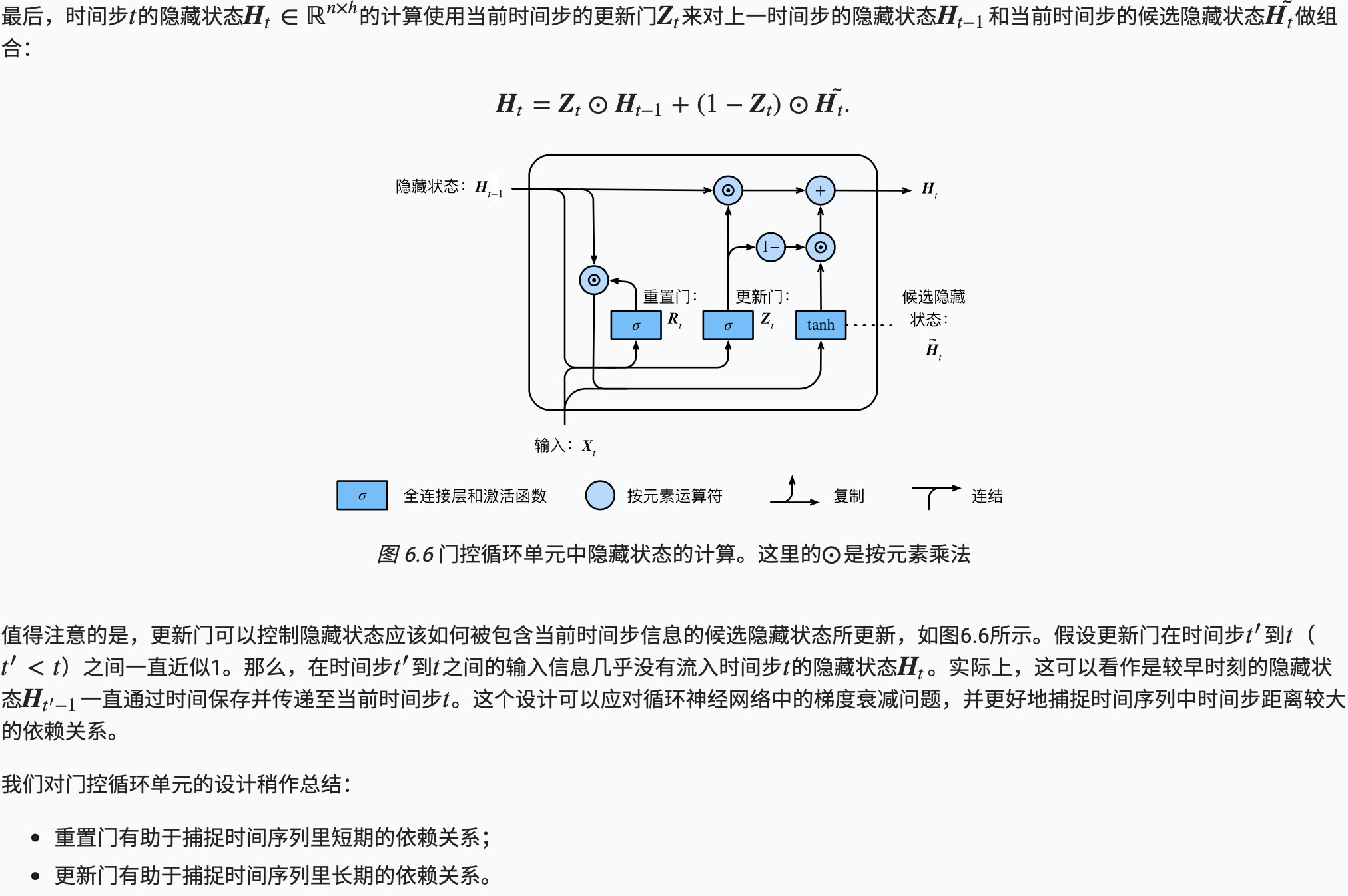
隐藏状态
代码实现


1 #!/usr/bin/env python 2 # coding: utf-8 3 4 # In[10]: 5 6 7 import d2lzh as d2l 8 from mxnet import nd 9 from mxnet.gluon import rnn 10 import zipfile 11 12 13 # In[11]: 14 15 16 def load_data_jay_lyrics(file): 17 """Load the Jay Chou lyric data set (available in the Chinese book).""" 18 with zipfile.ZipFile(file) as zin: 19 with zin.open('jaychou_lyrics.txt') as f: 20 corpus_chars = f.read().decode('utf-8') 21 corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ') 22 corpus_chars = corpus_chars[0:10000] 23 idx_to_char = list(set(corpus_chars)) 24 char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)]) 25 vocab_size = len(char_to_idx) 26 corpus_indices = [char_to_idx[char] for char in corpus_chars] 27 return corpus_indices, char_to_idx, idx_to_char, vocab_size 28 29 30 # In[12]: 31 32 33 file ='/Users/James/Documents/dev/test/data/jaychou_lyrics.txt.zip' 34 (corpus_indices, char_to_idx, idx_to_char, vocab_size) = load_data_jay_lyrics(file) 35 36 37 # In[13]: 38 39 40 num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size 41 ctx = d2l.try_gpu() 42 43 def get_params(): 44 def _one(shape): 45 return nd.random.normal(scale=0.01, shape=shape, ctx=ctx) 46 47 def _three(): 48 return (_one((num_inputs, num_hiddens)), 49 _one((num_hiddens, num_hiddens)), 50 nd.zeros(num_hiddens, ctx=ctx)) 51 52 W_xz, W_hz, b_z = _three() # 更新门参数 53 W_xr, W_hr, b_r = _three() # 重置门参数 54 W_xh, W_hh, b_h = _three() # 候选隐藏状态参数 55 # 输出层参数 56 W_hq = _one((num_hiddens, num_outputs)) 57 b_q = nd.zeros(num_outputs, ctx=ctx) 58 # 附上梯度 59 params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q] 60 for param in params: 61 param.attach_grad() 62 return params 63 64 65 # In[14]: 66 67 68 def init_gru_state(batch_size, num_hiddens, ctx): 69 return (nd.zeros(shape=(batch_size, num_hiddens), ctx=ctx), ) 70 71 72 # In[15]: 73 74 75 def gru(inputs, state, params): 76 W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params 77 H, = state 78 outputs = [] 79 for X in inputs: 80 Z = nd.sigmoid(nd.dot(X, W_xz) + nd.dot(H, W_hz) + b_z) 81 R = nd.sigmoid(nd.dot(X, W_xr) + nd.dot(H, W_hr) + b_r) 82 H_tilda = nd.tanh(nd.dot(X, W_xh) + nd.dot(R * H, W_hh) + b_h) 83 H = Z * H + (1 - Z) * H_tilda 84 Y = nd.dot(H, W_hq) + b_q 85 outputs.append(Y) 86 return outputs, (H,) 87 88 89 # In[16]: 90 91 92 num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2 93 pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开'] 94 95 96 # In[ ]: 97 98 99 d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens, 100 vocab_size, ctx, corpus_indices, idx_to_char, 101 char_to_idx, False, num_epochs, num_steps, lr, 102 clipping_theta, batch_size, pred_period, pred_len, 103 prefixes)
长短期记忆(LSTM)
常用的门控循环神经网络:长短期记忆(long short-term memory,LSTM)。它比门控循环单元的结构稍微复杂一点。
长短期记忆
LSTM 中引入了3个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态形状相同的记忆细胞(某些文献把记忆细胞当成一种特殊的隐藏状态),从而记录额外的信息。
输入门、遗忘门和输出门
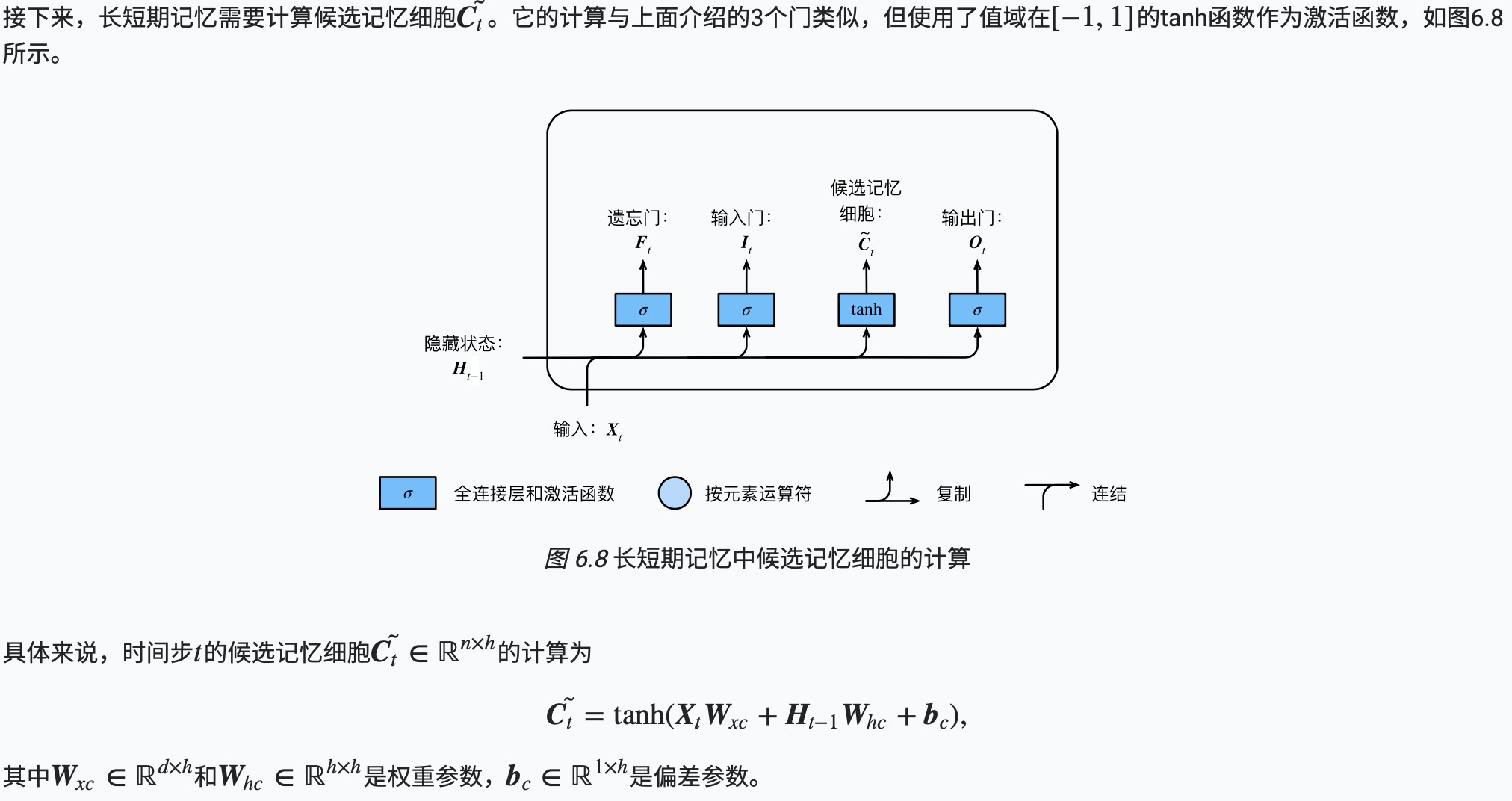
候选记忆细胞
记忆细胞
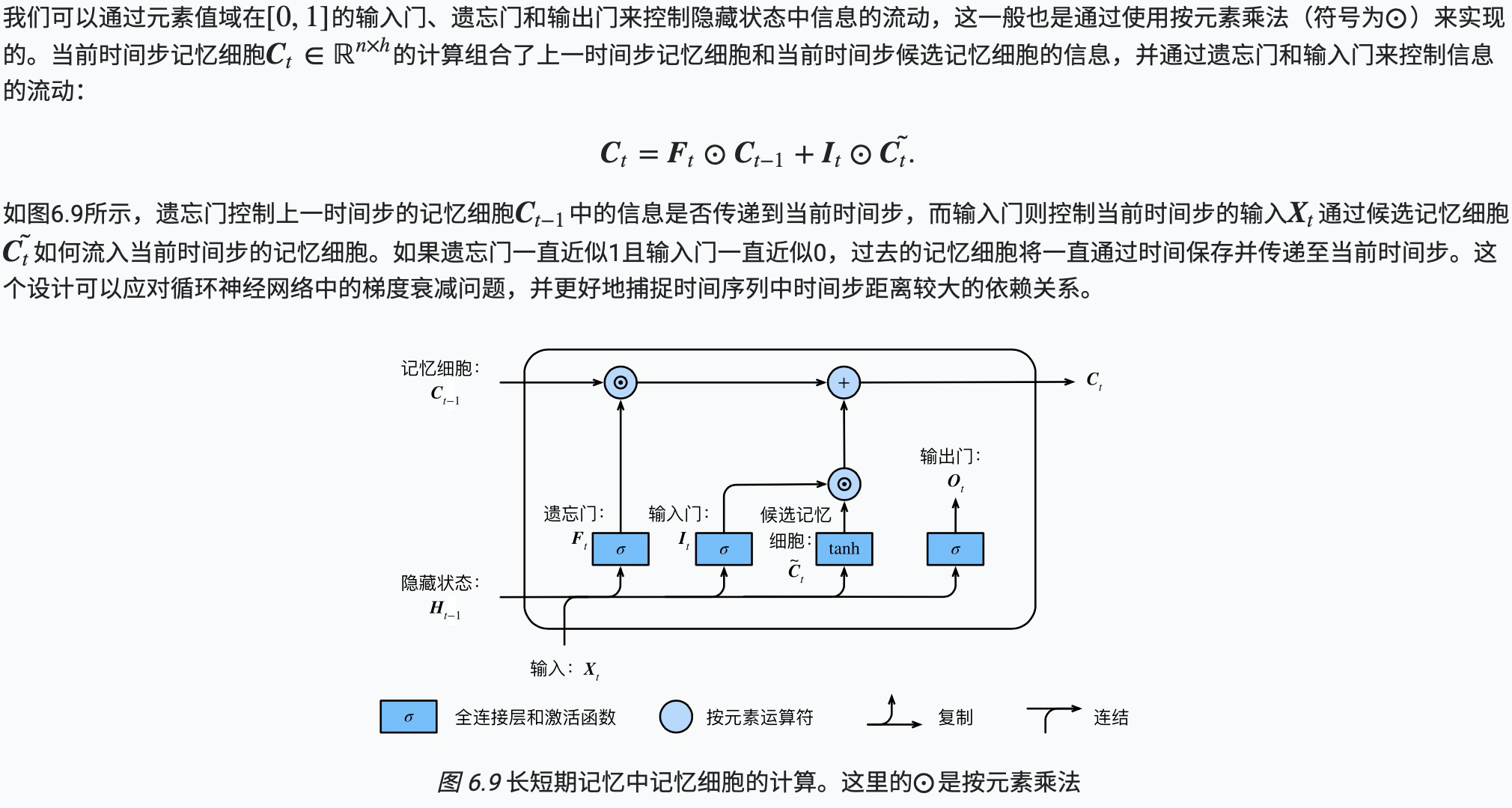
隐藏状态
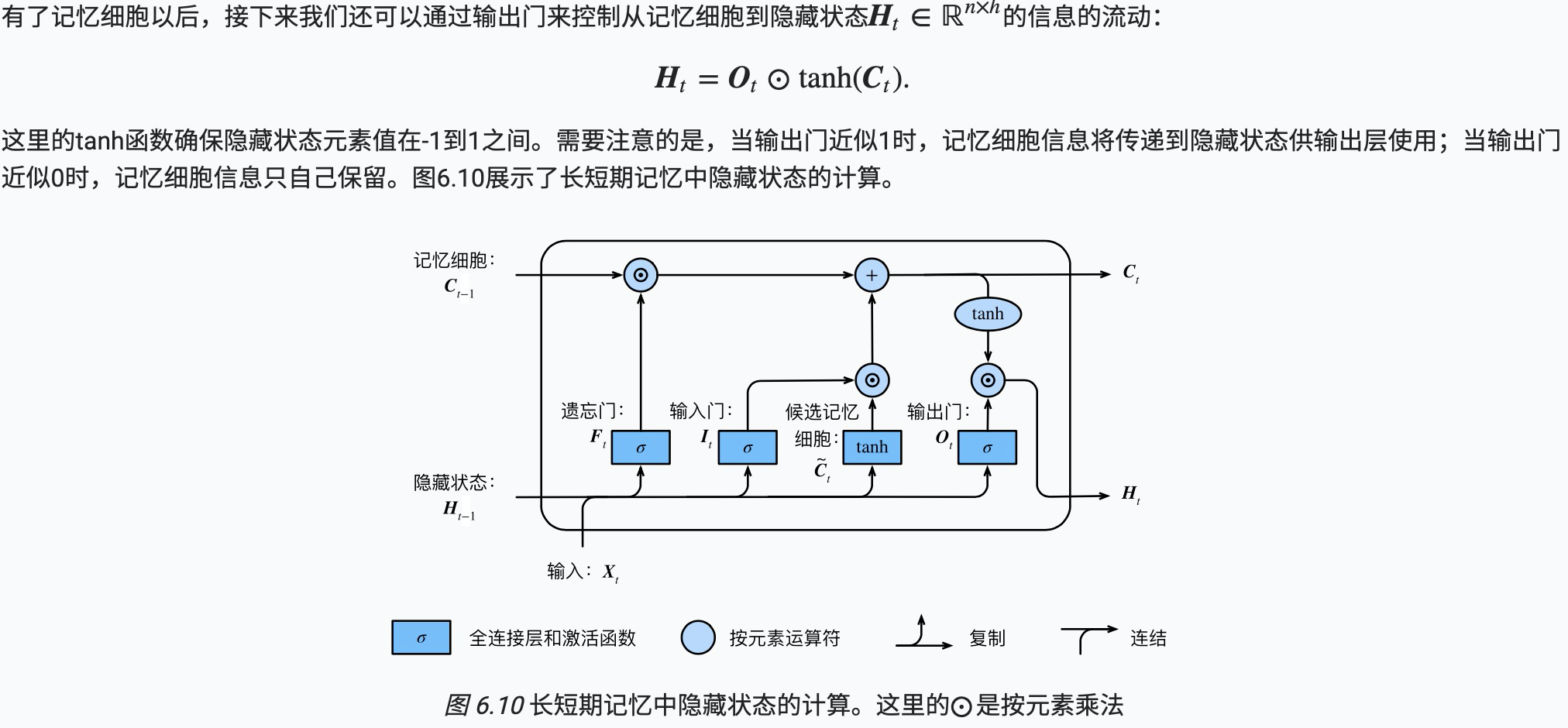
代码实现
1 #LSTM 初始化参数 2 num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size 3 ctx = d2l.try_gpu() 4 5 def get_params(): 6 def _one(shape): 7 return nd.random.normal(scale=0.01, shape=shape, ctx=ctx) 8 9 def _three(): 10 return (_one((num_inputs, num_hiddens)), 11 _one((num_hiddens, num_hiddens)), 12 nd.zeros(num_hiddens, ctx=ctx)) 13 14 W_xi, W_hi, b_i = _three() # 输入门参数 15 W_xf, W_hf, b_f = _three() # 遗忘门参数 16 W_xo, W_ho, b_o = _three() # 输出门参数 17 W_xc, W_hc, b_c = _three() # 候选记忆细胞参数 18 # 输出层参数 19 W_hq = _one((num_hiddens, num_outputs)) 20 b_q = nd.zeros(num_outputs, ctx=ctx) 21 # 附上梯度 22 params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, 23 b_c, W_hq, b_q] 24 for param in params: 25 param.attach_grad() 26 return params 27 28 29 # In[19]: 30 31 32 def init_lstm_state(batch_size, num_hiddens, ctx): 33 return (nd.zeros(shape=(batch_size, num_hiddens), ctx=ctx), 34 nd.zeros(shape=(batch_size, num_hiddens), ctx=ctx))
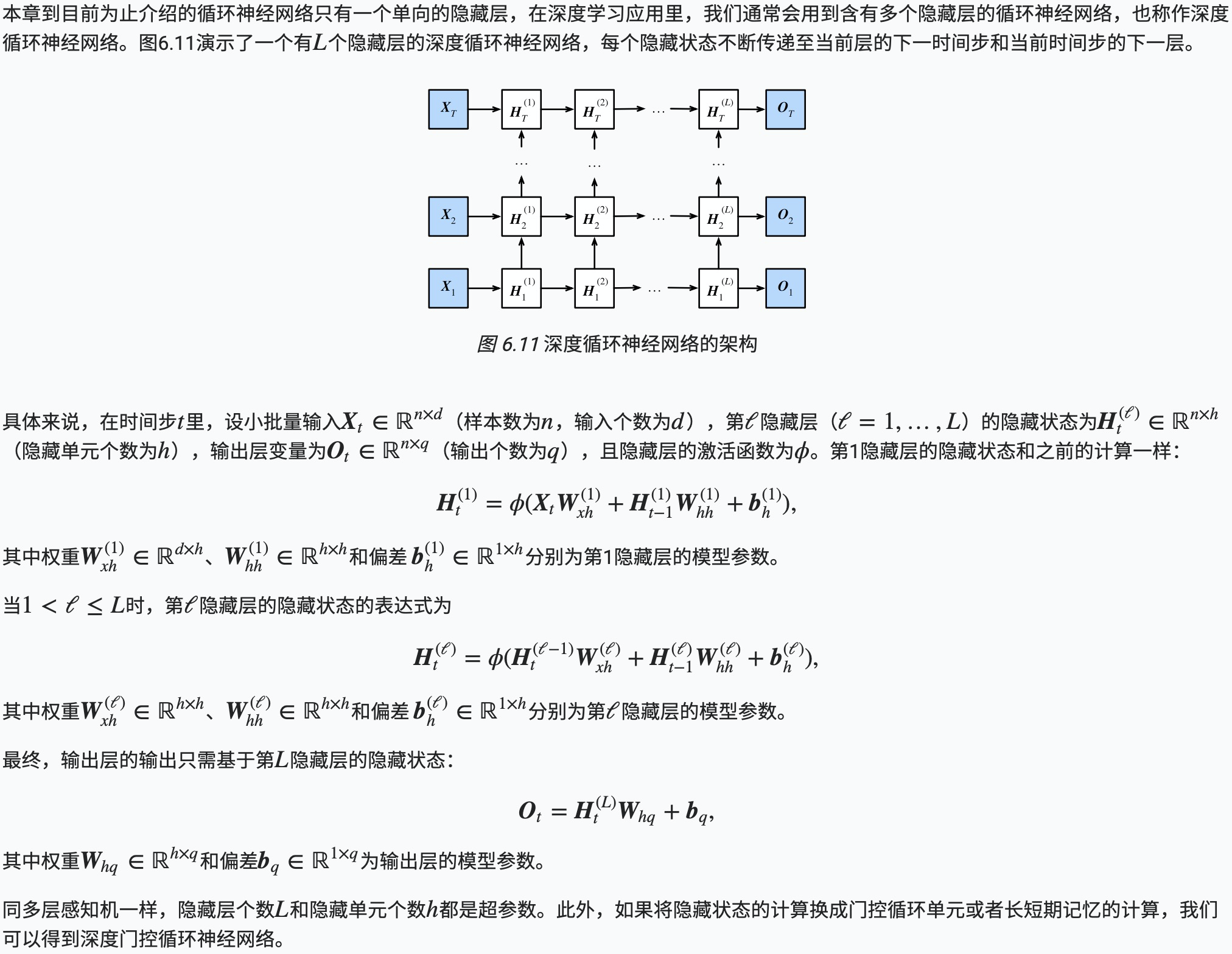
深度循环神经网络
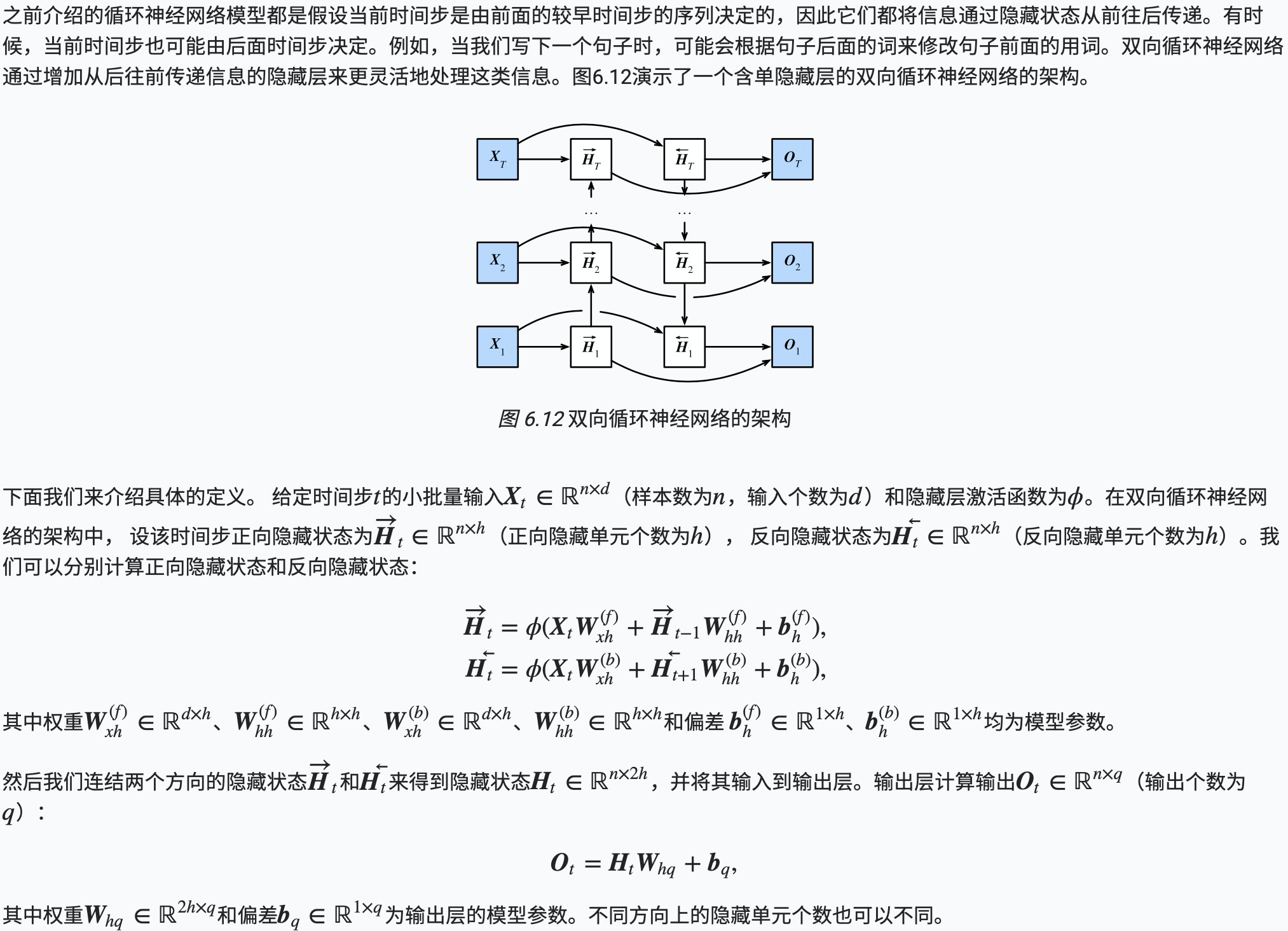
双向循环神经网络

 浙公网安备 33010602011771号
浙公网安备 33010602011771号