
zookeper实现分布式锁
引入依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.8.0</version>
</dependency>
zookeeper流程
-
客户端连接上zookeeper,并在指定节点(locks)下创建临时顺序节点node_n
-
客户端获取locks目录下所有children节点
-
客户端对子节点按节点自增序号从小到大排序,并判断自己创建的节点是不是序号最小的,若是则获取锁;若不是,则监听比该节点小的那个节点的删除事件
-
获得子节点变更通知后重复此步骤直至获得锁;
-
执行业务代码,完成业务流程后,删除对应的子节点释放锁。
部分问题
步骤1中为什么创建临时节点?
zk临时节点的特性是,当客户端与zk服务器的连接中断时,客户端创建的临时节点将自动删除;所以创建临时节点是为了保证在发生故障的情况下锁也能被释放,比如场景1:假如客户端a获得锁之后客户端所在机器宕机了,客户端没有主动删除子节点;如果创建的是永久的节点,那么这个锁永远不会释放,导致死锁;而如果创建的是临时节点,客户端宕机后,心跳检测时zookeeper没有收到客户端的心跳包就会判断该会话已失效,并且将临时节点删除从而释放锁。
步骤3中为什么不是监听locks目录,而仅监听比自己小的那一个节点?
如果每个客户端都监听locks目录,那么当某个客户端释放锁删除子节点时,其他所有的客户端都会收到监听事件,产生羊群效应,并且zookeeper在通知所有客户端时会阻塞其他的操作,最好的情况应该只唤醒新的最小节点对应的客户端。应该怎么做呢?在设置事件监听时,每个客户端应该对刚好在它之前的子节点设置事件监听,例如子节点列表为/lock/lock-0000000000、/lock/lock-0000000001、/lock/lock-0000000002,序号为1的客户端监听序号为0的子节点删除消息,序号为2的监听序号为1的子节点删除消息。
实现
这里讲的的是Shared Reentrant Lock(共享可重入锁,推荐使用,Curator还封装了其他类型的锁:共享不可重入锁之类的):全局同步的、公平的分布式共享重入式锁,可保证在任意同一时刻,只有一个客户端持有锁。使用到的类是InterProcessMutex
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.api.BackgroundCallback;
import org.apache.curator.framework.api.CuratorEvent;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* 类描述:Curator实现的分布式锁
* 创建人:simonsfan
*/
public class DistributedLock {
private static CuratorFramework curatorFramework;
private static InterProcessMutex interProcessMutex;
private static final String connectString = "localhost:2181";
private static final String root = "/root";
private static ExecutorService executorService;
private String lockName;
public String getLockName() {
return lockName;
}
public void setLockName(String lockName) {
this.lockName = lockName;
}
static {
curatorFramework = CuratorFrameworkFactory.builder().connectString(connectString).connectionTimeoutMs(5000).sessionTimeoutMs(5000).retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
executorService = Executors.newCachedThreadPool();
curatorFramework.start();
}
public DistributedLock(String lockName) {
this.lockName = lockName;
interProcessMutex = new InterProcessMutex(curatorFramework, root.concat(lockName));
}
/*上锁*/
public boolean tryLock() {
int count = 0;
try {
while (!interProcessMutex.acquire(1, TimeUnit.SECONDS)) {
count++;
if (count > 3) {
TimeUnit.SECONDS.sleep(1);
return false;
}
}
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
/*释放*/
public void releaseLock() {
try {
if (interProcessMutex != null) {
interProcessMutex.release();
}
curatorFramework.delete().inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework curatorFramework, CuratorEvent curatorEvent) throws Exception {
}
}, executorService).forPath(root.concat(lockName));
} catch (Exception e) {
e.printStackTrace();
}
}
}
自己测试
自己写个main方法测试了一波是没问题的:
public static void main(String[] args) throws Exception {
DistributedLock distributedLock = new DistributedLock("aaa");
for (int i = 0; i < 10; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"启动");
while (!distributedLock.tryLock()) {
try {
System.out.println(Thread.currentThread().getName()+"尝试获取锁");
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
System.out.println(Thread.currentThread().getName()+"获得了锁,睡眠");
TimeUnit.SECONDS.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"释放锁");
distributedLock.releaseLock();
}).start();
}
}
获取锁和释放锁都是十次,尝试的就很多了…


可以看到都在/rootaaa创建节点
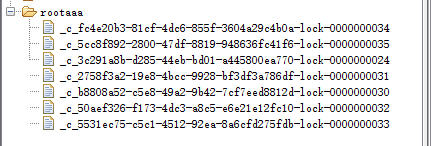
大约过一秒,获取锁的超时时间1s,就只剩下0了
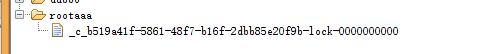
什么原因呢?
在描述算法流程之前,先看下zookeeper中几个关于节点的有趣的性质:
-
有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号,也就是说如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
-
临时节点:客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
-
事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:1)节点创建;2)节点删除;3)节点数据修改;4)子节点变更。
下面描述使用zookeeper实现分布式锁的算法流程,假设锁空间的根节点为/lock: -
客户端连接zookeeper,并在/lock下创建 临时的 且 有序的 子节点,第一个客户端对应的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推。
客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中 序号最小 的子节点,如果是则认为获得锁,否则监听/lock的子节点变更消息,获得子节点变 - 更通知后重复此步骤直至获得锁; -
执行业务代码;
-
完成业务流程后,删除对应的子节点释放锁。
获取锁的代码

有个超时时间,按照上面讲的,如果我的超时时间很长,远大于所有线程执行完成的时间的话,那我执行获取锁的顺序应该是有序的,因为当0被删除后,监听0的是1新增1节点的.所以,就变成新增1节点的线程获取锁了,同理,那节点应该是有序的递增
测试一波,将获取锁时间改为100,获取锁之后睡眠3秒,我们查看节点的变化;

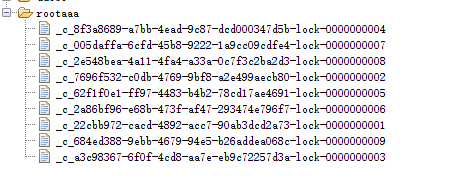


等等…

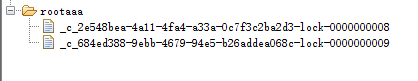
临时节点删减的顺序是有序的,我们分析的没错…是不是就像一个队列.
其实zk实现队列也是差不多的,只不过是将临时节点换成持久化节点,然后节点存需要消费的信息.而已,用的不多,不想看.
转:
curator的使用:
https://blog.csdn.net/u012129558/article/details/81076487
分布式锁:
https://blog.csdn.net/fanrenxiang/article/details/83013218
https://blog.csdn.net/u010028869/article/details/84034261
源码分析:https://www.cnblogs.com/a-du/p/9876314.html
