


大数据-Storm
Storm是实时的,分布式,高容错的计算系统。java+cljoure
Storm常驻内存,数据在内存中处理不经过磁盘,数据通过网络传输。
底层java+cljoure构成,阿里使用java重构Storm构建Jstorm。
数据处理分类
-
流式处理(异步)
-
客户端提交数据进行结算,不会等待计算结果
-
数据追条处理:数据清洗或分析
-
例:在数据统计分析中:数据存入队列,storm从MQ获取数据,storm将结果存入存储层
-
-
实时请求应答(同步)
-
客户端提交请求后立即计算并将结果返回给客户端
-
图片特征提取: 客户端向Storm的drpc发送请求,客户端等待Storm响应结果
-
Storm与MR的比较
-
Storm流式处理,毫秒级响应,常驻内存
-
MR批处理TB级数据,分钟级响应,反复启停
优势
高可靠:异常处理;消息可靠性保障机制
可维护性:提供UI监控接口
架构模型
-
Nimbus:接收请求,接收jar包并解析,任务分配,资源分配
-
zookeeper:存储Nimbus分配的子任务,存储任务数据,用于解耦架构
-
Supervisor:从zk中获取子任务,启动worker任务,启停所管理的worker
-
Worker:执行具体任务(每个worker对应一个Topology的子集),分为spout任务和bolt任务,启动executor,一个executor对应一个线程,默认一个executor执行一个task任务。任务所需数据从zookeeper中获取。
| storm与MR比对 | MR | Storm |
|---|---|---|
| 主节点 | ResourceManager | Nimbus |
| 从节点 | NodeManager | Supervisor |
| 应用程序 | Job | Topology |
| 工作进程 | Child | Worker |
| 计算模型 | Map/Reduce | Spout/Bolt |
编程模型
DAG有向无环图,拓扑结构图,作为实时计算逻辑的封装。一旦启动会一直在系统中运行直到手动kill
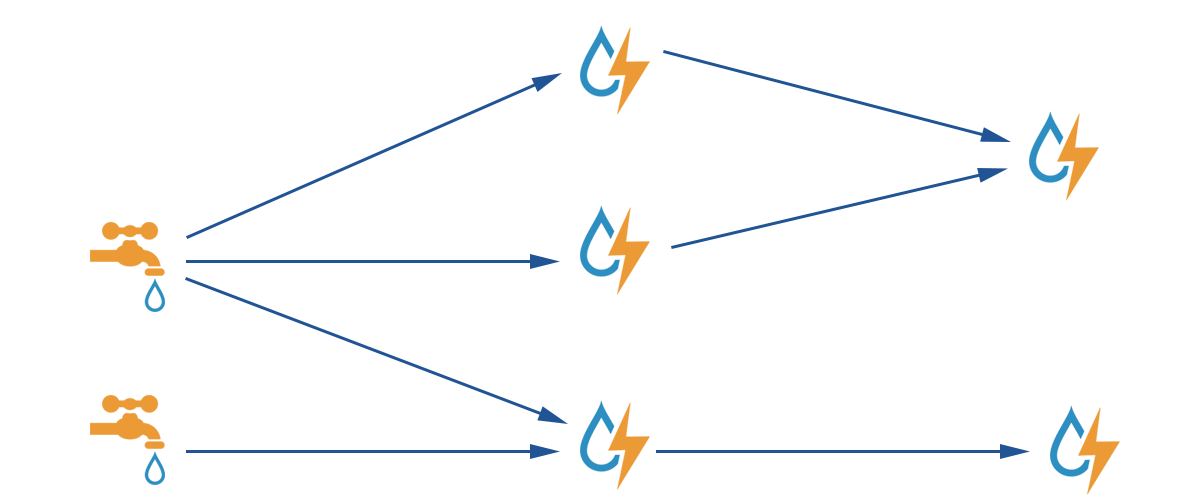
Spout 数据源节点
-
从外部读取原始数据
-
定义数据流,可定义多个数据流向不同Bolt 发数据,读取外部数据源
-
nextTuple:被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成Tuple,发送给之后的Bolt计算
Bolt 计算节点
-
execute:该方法接收到一个Tuple数据,真正业务逻辑
-
定义数据流,将结果数据发出去
API
以wordcount为例:Spout 获取原始行数据,将行数据Tuple作为发给bolt1,bolt1解析行数据为单词数据,bolt1将单词数据转为Tuple发给bolt2,bolt2对单词数据进行计数,将计数结果发送到存储层。
Topology类
指定计算任务的各节点及节点关联,提交任务
-
topologyBuilder的setSpout方法和setBolt方法构建各节点
-
方法参数为:id值,bolt类,并发度(线程),task数,数据来源节点,数据流,分组字段
-
shuffleGrouping是随机分配数据
-
多并发度
-
-
fieldsGrouping是根据指定的若干字段分组到不同的线程
-
-
-
Config对象传入配置参数
-
超时时间 秒:conf.setMessageTimeoutSecs(3);
-
-
LocalCluster本地执行,对象提交任务名,参数对象,拓扑对象,最终执行任务
public class MyTopology {
public static void main(String[] args) {
//创建拓扑构建对象
TopologyBuilder topologyBuilder=new TopologyBuilder();
/**
* 指定各节点,线程数量,上下游关联
* 对于多线程,注意上游的结果会随机发给各个线程
*/
//设置spout节点,指定(id值,spout类,并发度)
topologyBuilder.setSpout("s1",new CountSpout(),1);
//设置bolt节点,指定 (id值,bolt类,并发度,数据来源节点,分组字段)
topologyBuilder.setBolt("b1",new CountBolt1(),2).setNumTasks(4).shuffleGrouping("s1");
topologyBuilder.setBolt("b2",new CountBolt2(),1).fieldsGrouping("b1",new Fields("word"));
//构建拓扑对象
StormTopology stormTopology=topologyBuilder.createTopology();
//设置配置信息,该对象实际是个map,向其中设置各种参数
Config config=new Config();
config.setNumWorkers(3);
config.put("xxx","xxx");
//获取本地执行集群对象
LocalCluster lc=new LocalCluster();
//本地执行:向集群提交任务,任务名,参数,拓扑节点
lc.submitTopology("job-count",config,stormTopology);
}
}
Spout类(自定义)
继承BaseRichSpout类,实际实现了IRichSpout接口,主要重写以下方法
-
open()——初始化,参数为:配置参数, 上下文,输出对象
-
nextTuple()——业务代码
-
declareOutputFields()——定义输出结果
-
关于数据输出
将SpoutOutputCollector输出对象转为全局变量,通过SpoutOutputCollector输出数据
使用Values对象,存入多个结果(相当于一个list)
通过OutputFieldsDeclarer对象,依次定义每个结果的字段名(相当于给list字段命名,形成类似map的有序集合)
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class CountSpout extends BaseRichSpout {
/** 将输出对象转为全局属性,支持数据输出 */
private SpoutOutputCollector collector;
//初始化
Bolt类(自定义)
继承BaseRichBolt类,实际实现了IRichBolt接口,主要重写以下方法
-
prepare()——初始化
-
execute()——业务代码
-
declareOutputFields()——定义输出字段
-
关于输出数据,与spout相同
-
关于输入数据:通过input的各种方法获取对应类型的数据,支持通过字段所在索引下标或字段名获取指定位置的值
public class CountBolt1 extends BaseRichBolt {
/** 将输出对象转为全局属性,支持数据输出 */
private OutputCollector collector;
分组策略
-
Shuffle Grouping:轮询的方式,随机派发tuple,每个线程接收到数量大致相同。
-
Fields Grouping:按指定的字段分组,指定字段的值相同tuple,分配相同的task(处于同一个线程中)
-
以下方式了解
-
All Grouping:广播发送,所有下游的bolt线程都会收到。还是task
-
Global Grouping:全局分组, 将tuple分配给 id最低的task,这个id是用户指定的id值。
-
None Grouping:随机分组
-
Direct Grouping:指向型分组
-
local or shuffle grouping:若目标bolt task与源bolt task在同一工作进程中,则tuple随机分配给同进程中的tasks。否则普通的Shuffle分配 Grouping行为一致
-
customGrouping:自定义
-
分布式搭建
环境搭建
-
安装
tar -zxvf apache-storm-0.10.0.tar.gz
mv apache-storm-0.10.0 storm-0.10.0
-
修改配置
vim /opt/sxt/storm-0.10.0/conf/storm.yaml
#指定zk地址
storm.zookeeper.servers:
- "node1"
- "node2"
- "node3"
#指定nimbus的节点
nimbus.host: "node1"
#指定开放的端口(默认以下4个)
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703 -
拷贝到其他节点
cd /opt/sxt
scp -r storm-0.10.0/ node3:`pwd`
启动+命令
启动集群
-
启动zookeeper集群
zkServer.sh start
-
启动nimbus节点 cd /opt/sxt/storm-0.10.0
-
各节点创建logs目录:mkdir logs
-
主节点启动:
-
启动nimbus
nohup ./bin/storm nimbus >> logs/nimbus.out 2>&1 &
-
启动监控ui
nohup ./bin/storm ui >> logs/ui.out 2>&1 &
-
-
从节点启动supervisor
-
nohup ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
-
注:项目的日志也就存放中logs目录下的各文件中
可以远程查看:例如文件wc-1-1571317142-worker-6700.log
http://node1:8080/topology.html?wc-1-1571317142-worker-6700.log
-
-
网页登录设置在主节点上的UI监控地址 http://node1:8080
关闭集群
#关闭nimbus
kill `ps aux | egrep '(daemon.nimbus)|(storm.ui.core)' | fgrep -v egrep | awk '{print $2}'`
#关闭supervisor
kill `ps aux | fgrep storm | fgrep -v 'fgrep' | awk '{print $2}'`
#关闭zk
zkServer.sh stop
运行项目
从IDE中导出项目jar文件(field标签 > project structure > 指定主类创建jar配置 > bulid标签 > build project > 从项目目录中找到jar文件) 导入到/opt/sxt下
载入项目命令:./bin/storm jar /opt/sxt/wc.jar com.shsxt.storm.wordcount.WordCountTP wc
依次指定jar文件目录,主类,topology名
停止项目命令:./bin/storm kill wc (注意指定topology)
内部文件结构
-
本地目录
/opt/sxt/storm-0.10.0/storm-local 目录下存放项目执行时的数据
内部为一个目录树结构
-
zookeeper目录
进入zk客户端 zkCli.sh
查看storm的目录 ls /storm 内部时一个目录树
查看指定的数据 get /xxx/xxx
并发机制
-
worker进程
-
具体执行任务的进程
-
一个topology包含若干个worker执行,worker执行topology的子集
-
一个worker需要绑定一个网络端口,默认一个节点最多运行4个worker,通过配置多于4个端口开放更多worker
-
-
Executor线程
-
execute是由worker进程创建的线程,worker包含至少一个executor线程
-
一个线程中能够执行一个或多个task任务,默认一个线程执行一个task
-
spout / boltk 与线程是一对多的关系,一个spout 可以包含多个线程,但线程只对应一个spout,监控线程除外。
-
-
task
-
数据处理的最小单元
-
每个task对应spout或bolt的一个并发度
-
关于再平衡热rebalance
-
在topology生命周期中,worker与executor的数量可变,task的数量不可变
-
多个线程无法同时执行一个task,只能一个线程执行一个task,因此线程数应该小于task数,设置多的线程是无效的。
-
注意:系统对每个worker都会设置一个监控线程,监控线程数量与worker相同
-
命令修改
./bin/storm/rebalance wc -n 5 -e blue-spout=3 -e yellow-bolt=10
(调整wc任务 5个worker 3个spout线程 10个bolt线程 )
-
api设置
-
worker数
通过配置文件制定worker数量
config.setNumWorkers(3);
-
executor数与task数量
线程数设置 setBolt(String id, IRichBolt bolt, Number 线程数);和setSpout()方法
设置任务数 setNumTasks(task数)
topologyBuilder.setBolt("wcSplit",new WordCountSplit(),2).setNumTasks(4).shuffleGrouping("wcSpout");
-
数据传输
-
worker之间数据传输使用Netty架构
-
接收线程监听tcp端口,并将数据存入缓冲区域
-
发送线程使用传输队列发送数据
-
-
worker的内部通讯采用Disruptor的队列处理机制
数据从缓冲区读取经过:接收队列——工作线程——发送队列——发送线程
-
tuple 在Storm中的数据的传输单元
-
Stream 数据连通的管道,多个管道时需要指定Stream的id
线程数包括:spout线程数,blot线程数,acker(每个work1个监控线程)
容错机制
宕机机制
-
nimbus宕机
-
无状态策略,所有的状态信息都存放在Zookeeper中来管理,worker正常运行,只是无法提交新的topology
-
快速失败策略:自检到异常后自毁并重启
-
-
supervisor宕机
-
无状态策略,supervisor的所有的状态信息都存放在Zookeeper中来管理
-
快速失败策略:自检到异常后自毁并重启
-
节点故障状态下,若所有该节点上的任务超时,nimbus会将该节点的task分配给其他的节点
-
-
worker宕机
-
supervisor会重启worker进程
-
若worker多次失败且无法向nimbus发送心跳,nimbus会将该worker的分配到其他supervisor上执行。
-
数据跟踪acker
消息完整性
spout中发出的tuple及其由tuple产生的子tuple,构成一个树形结构,只有当数中的所有消息都被正确处理,才能保证数据的完整性。
为了保证数据的完整性,对于处理失败的tuple需要请求上游的spout重发数据。
消息重发的机制:at least(至少一次),oncely (有且只有一次)
acker机制
acker跟踪每个spout发出的tuple。
acker记录每个trulp的id,数据处理后,通过亦或算法清空id,若id未清空则表明这条数据没有处理完成。
-
自定义acker类,对数据进行监控
-
在topology中添加具备acker功能的spout作为acker类
topologyBuilder.setSpout("myack",new MyAckSpout());
-
定义acker类
-
实现IRichSpout接口,重写ack(成功)和fail(失败)方法,对发出的数据进程缓存
-
设置全局缓存,数据发送时存入缓存,处理成功删除缓存,处理失败,从缓存取数据重发
public class MyAckSpout implements IRichSpout {
SpoutOutputCollector collector;
//数据缓存
Map<Object,String> map = new HashMap<>();
//设置全局缓存id
long id = 0;
-
-
-
bolt 中代码响应,execute方法中
-
方法末尾添加数据处理的响应
处理成功:collection.ack(input)
处理失败:collection.fail(input) 注意:超时也数据失败
-
向下游发送数据时,指定acker是否继续跟踪下游数据
跟踪:collector.emit(input,new Values(split[i]));
不跟踪:collector.emit(new Values(split[i]));
public void execute(Tuple input) {
String xxx = input.getStringByField("aaa");
//结束跟踪
collector.emit(new Values(xxx));
//继续collector.emit(new Values(xxx));
//处理成功
collector.ack(input);
//处理失败,collector.fail(input);
}
-
实时计算整合
采集层(flume):实现日志收集,使用负载均衡策略
消息队列(kafka):作用是解耦及不同速度系统缓冲
实时处理单元(Storm):用Storm来进行数据处理,最终数据流入DB中
展示单元(DB+web):数据可视化,使用WEB框架展示
整合kafka

