
【JVM系列1】深入分析Java虚拟机堆和栈及OutOfMemory异常产生原因
前言
JVM系列文章如无特殊说明,一些特性均是基于Hot Spot虚拟机和JDK1.8版本讲述。
下面这张图我想对于每个学习Java的人来说再熟悉不过了,这就是整个JDK的关系图:

从上图我们可以看到,Java Virtual Machine位于最底层,所有的Java应用都是基于JVM来运行的,所以学习JVM对任何一个想要深入了解Java的人是必不可少的。
Java的口号是:Write once,run anywhere(一次编写,到处运行)。之所以能实现这个口号的原因就是因为JVM的存在,JVM帮我们处理好了不同平台的兼容性问题,只要我们安装对应系统的JDK,就可以运行,而无需关心其他问题。
什么是JVM
JVM全称Java Virtual Machine,即Java虚拟机,是一种抽象计算机。与真正的计算机一样,它有一个指令集,并在运行时操作各种内存区域。虚拟机有很多种,不同的厂商提供了不同的实现,只要遵循虚拟机规范即可。目前我们常说的虚拟机一般都指的是Hot Spot。
JVM对Java编程语言一无所知,只知道一种特定的二进制格式,即类文件格式。类文件包含Java虚拟机指令(或字节码)和符号表,以及其他辅助信息。也就是说,我们写好的程序最终交给JVM执行的时候会被编译成为二进制格式。
注意:Java虚拟机只认二进制格式文件,所以,任何语言,只要编译之后的格式符合要求,都可以在Java虚拟机上运行,如Kotlin,Groovy等。
Java程序执行流程
从我们写好的.java文件到最终在JVM上运行时,大致是如下一个流程:
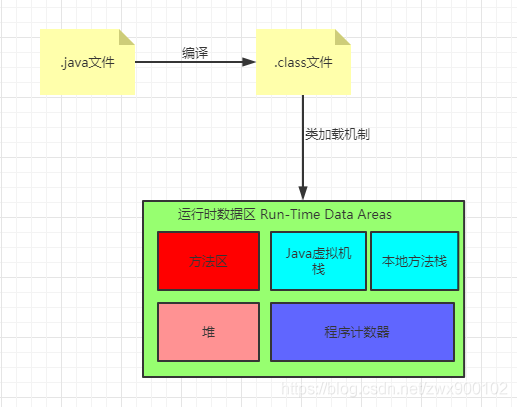
一个java类在经过编译和类加载机制之后,会将加载后得到的数据放到运行时数据区内,这样我们在运行程序的时候直接从JVM内存中读取对应信息就可以了。
运行时数据区
运行时数据区:Run-Time Data Areas。Java虚拟机定义了在程序执行期间使用的各种运行时数据区域。其中一些数据区域是在Java虚拟机启动时创建的,只在Java虚拟机退出时销毁,这些区域是所有线程共享的,所以会有线程不安全的问题发生。而有一些数据区域为每个线程独占的,每个线程独占数据区域在线程创建时创建,在线程退出时销毁,线程独占的数据区就不会有安全性问题。
Run-Time Data Areas主要包括如下部分:pc寄存器,堆,方法区,虚拟机栈,本地方法栈。
PC(program counter) Register(程序计数器)
PC Register是每个线程独占的空间。
Java虚拟机可以支持同时执行多个线程,而在任何一个确定的时刻,一个处理器只会执行一个线程中的一个指令,又因为线程具有随机性,操作系统会一直切换线程去执行不同的指令,所以为了切换线程之后能回到原先执行的位置,每个JVM线程都必须要有自己的pc(程序计数器)寄存器来独立存储执行信息,这样才能继续之前的位置往后运行。
在任何时候,每个Java虚拟机线程都在执行单个方法的代码,即该线程的当前方法。如果该方法不是Native方法,则pc寄存器会记录当前正在执行的Java虚拟机指令的地址。如果线程当前执行的方法是本地的,那么Java虚拟机的pc寄存器的值是Undefined。
Heap(堆)
堆是Java虚拟机所管理内存中最大的一块,在虚拟机启动时创建,被所有线程共享。
堆在虚拟机启动时创建,用于存储所有的对象实例和数组(在某些特殊情况下不是)。
堆中的对象永远不会显式地释放,必须由GC自动回收。所以GC也主要是回收堆中的对象实例,我们平常讨论垃圾回收主要也是回收堆内存。
堆可以处于物理上不连续的内存空间,可以固定大小,也可以动态扩展,通过参数-Xms和Xmx两个参数来控制堆内存的最小和最大值。
堆可能存在如下异常情况:
- 如果计算需要的堆比自动存储管理系统提供的堆多,将抛出OutOfMemoryError错误。
模拟堆内OutOfMemoryError
为了方便模拟,我们把堆固定一下大小,设置为:
-Xms20m -Xmx20m
然后新建一个测试类来测试一下:
package com.zwx.jvm.oom; import java.util.ArrayList; import java.util.List; public class Heap { public static void main(String[] args) { List<Integer> list = new ArrayList<>(); while (true){ list.add(99999); } } }
输出结果为(后面的Java heap space,表示堆空间溢出):
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:3210) at java.util.Arrays.copyOf(Arrays.java:3181)
注意:堆不能设置的太小,太小的话会启动失败,如上我们把参数大小都修改为2m,会出现下面的错误:
Error occurred during initialization of VM
GC triggered before VM initialization completed. Try increasing NewSize, current value 1536K.
Method Area(方法区)
方法区是各个线程共享的内存区域,在虚拟机启动时创建。它存储每个类的结构,比如:运行时常量池、属性和方法数据,以及方法和构造函数的代码,包括在类和实例初始化以及接口初始化中使用的特殊方法。
方法区在逻辑上是堆的一部分,但是它却又一个别名叫做Non-Heap(非堆),目的是与Java堆区分开来。
方法区域可以是固定大小,也可以根据计算的需要进行扩展,如果不需要更大的方法区域,则可以收缩。方法区域的内存不需要是连续的。
方法区中可能出现如下异常:
- 如果方法区域中的内存无法满足分配请求时,将抛出OutOfMemoryError错误。
Run-Time Constant Pool(运行时常量池)
运行时常量池是方法区中的一部分,用于存储编译生成的字面量和符号引用。类或接口的运行时常量池是在Java虚拟机创建类或接口时构建的。
字面量
在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法(notation)。几乎所有计算机编程语言都具有对基本值的字面量表示,诸如:整数、浮点数以及字符串等。在Java中常用的字面量就是基本数据类型或者被final修饰的常量或者字符串等。
String字符串去哪了
字符串这里值得拿出来单独解释一下,在jdk1.6以及之前的版本,Java中的字符串就是放在方法区中的运行时常量池内,但是在jdk1.7和jdk1.8版本(jdk1.8之后本人没有深入去了解过,所以不讨论),将字符串常量池拿出来放到了堆(heap)里。
我们来通过一个例子来演示一下区别:
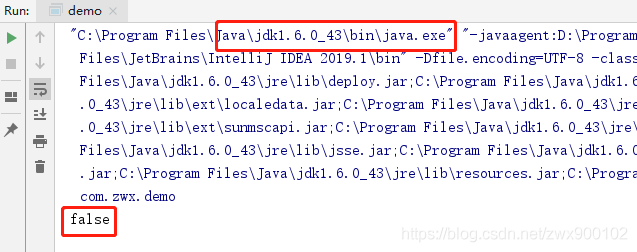
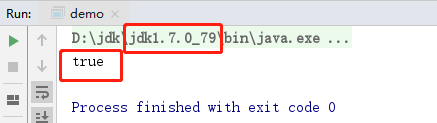
package com.zwx; public class demo { public static void main(String[] args) { String str1 = new String("lonely") + new String("wolf"); System.out.println(str1==str1.intern()); } }
这个语句的运行结果在不同的JDK版本中输出的结果会不一样:
JDK1.6中会输出false:
JDK1.7中输出true:
JDK1.8中也会输出true:

intern()方法
-
jdk1.6及之前的版本中:
调用String.intern()方法,会先去常量池检查是否存在当前字符串,如果不存在,则会在方法区中创建一个字符串,而new String("")方法创建的字符串在堆里面,两个字符串的地址不相等,故而返回false。 -
在jdk1.7及1.8版本中:
字符串常量池从方法区中的运行时常量池移到了堆内存中,而intern()方法也随之做了改变。调用String.intern()方法,首先还是会去常量池中检查是否存在,如果不存在,那么就会创建一个常量,并将引用指向堆,也就是说不会再重新创建一个字符串对象了,两者都会指向堆中的对象,所以返回true。
不过有一点还是需要注意,我们把上面的构造字符串的代码改造一下:String str1 = new String("ja") + new String("va"); System.out.println(str1==str1.intern()); 12
这时候在jdk1.7和jdk1.8中也会返回false。
这个差异在《深入理解Java虚拟机》一书中给出的解释是java这个字符串已经存在常量池了,所以我个人的推测是可能初始化的时候jdk本身需要使用到java字符串,所以常量池中就提前已经创建好了,如果理解错了,还请大家指正,感谢!
new String(“lonely”)创建了几个对象
上面的例子中我用了两个new String(“lonely”)和new String(“wolf”)相加,而如果去掉其中一个new String()语句的话,那么实际上jdk1.7和jdk1.8中返回的也会是false,而不是true。
这是为什么?看下面(
):
- 只执行一个new String(“lonely”)会产生2个对象,1个在堆,1个在字符串常量池
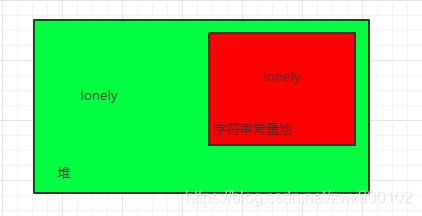
这时候执行了String.intern()方法,String.intern()会去检查字符串常量池,发现字符串常量池存在longly字符串,所以会直接返回,不管是jdk1.6还是jdk1.7和jdk1.8都是检查到字符串存在就会直接返回,所以str1==str1.intern()得到的结果就是都是false,因为一个在堆,一个在字符串常量池。
- 执行new String(“lonely”)+new String(“wolf”)会产生5个对象,3个在堆,2个在字符串常量池
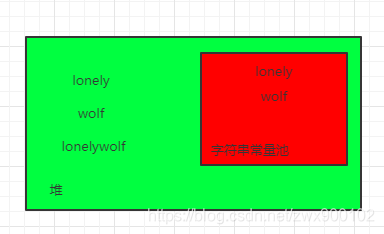
好了,这时候执行String.intern()方法会怎么样呢,如果在jdk1.7和jdk1.8会去检查字符串常量池,发现没有lonelywolf字符串,所以会创建一个指向堆中的字符串放到字符串常量池:
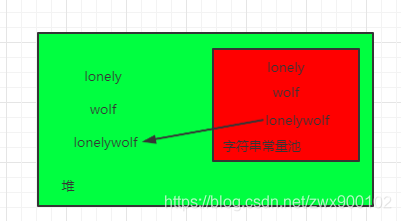
而如果是jdk1.6中,不会指向堆,会重新创建一个lonelywolf字符串放到字符串常量池,所以才会产生不同的运行结果。
注意:+号的底层执行的是new StringBuild().append()语句,所以我们再看下面一个例子:
String s1 = new StringBuilder("aa").toString(); System.out.println(s1==s1.intern()); String s2 = new StringBuilder("aa").append("bb").toString(); System.out.println(s2==s2.intern());//1.6返回false,1.7和1.8返回true
这个在jdk1.6版本全部返回false,而在jdk1.7和jdk1.8中一个返回false,一个返回true。多了一个append相当于上面的多了一个+号,原理是一样的。
符号引用
符号引用在下篇讲述类加载机制的时候会进行解释,这里暂不做解释,
。
jdk1.7和1.8的实现方法区的差异
方法区是Java虚拟机规范中的规范,但是具体如何实现并没有规定,所以虚拟机厂商完全可以采用不同的方式实现方法区的。
在HotSpot虚拟机中:
- jdk1.7及之前版本
方法区采用永久代(Permanent Generation)的方式来实现,方法区的大小我们可以通过参数-XX:PermSize和-XX:MaxPermSize来控制方法区的大小和所能允许最大值。
- jdk1.8版本
移除了永久代,采用元空间(Metaspace)来实现方法区,所以在jdk1.8中关于永久代的参数-XX:PermSize和-XX:MaxPermSize已经被废弃却代之的是参数-XX:MetaspaceSize和-XX:MaxMetaspaceSize。元空间和永久代的一个很大的区别就是元空间已经不在jvm内存在,而是直接存储到了本地内存中。
如下,我们再jdk1.8中设置-XX:PermSize和-XX:MaxPermSize会给出警告:
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize1m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize1m; support was removed in 8.0
模拟方法区OutOfMemoryError
jdk1.7及之前版本
因为jdk1.7及之前都是永久代来实现方法区,所以我们可以通过设置永久代参数来模拟内存溢出:
设置永久代最大为2M:
-XX:PermSize=2m -XX:MaxPermSize=2m

然后执行如下代码:
package com.zwx; import java.util.ArrayList; import java.util.List; public class demo { public static void main(String[] args) { List<String> list = new ArrayList<>(); int i = 0; while (true){ list.add(String.valueOf(i++).intern()); } } }
最后报错OOM:PermGen space(永久代溢出)。
Error occurred during initialization of VM java.lang.OutOfMemoryError: PermGen space at sun.misc.Launcher$ExtClassLoader.getExtClassLoader(Launcher.java:141) at sun.misc.Launcher.<init>(Launcher.java:71) at sun.misc.Launcher.<clinit>(Launcher.java:57)
jdk1.8
jdk1.8版本,因为永久代被取消了,所以模拟方式会不一样。
首先引入asm字节码框架依赖(前面介绍动态代理的时候提到cglib动态代理也是利用了asm框架来生成字节码,所以也可以直接cglib的api来生成):
<dependency>
<groupId>asm</groupId>
<artifactId>asm</artifactId>
<version>3.3.1</version>
</dependency>
创建一个工具类去生成class文件:
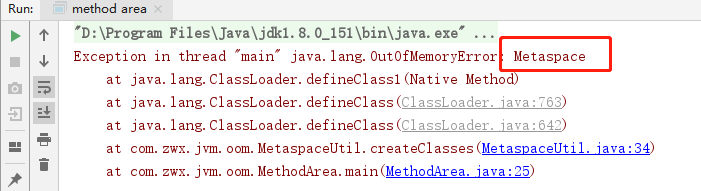
package com.zwx.jvm.oom; import jdk.internal.org.objectweb.asm.ClassWriter; import jdk.internal.org.objectweb.asm.MethodVisitor; import org.objectweb.asm.Opcodes; import java.util.ArrayList; import java.util.List; public class MetaspaceUtil extends ClassLoader { public static List<Class<?>> createClasses() { List<Class<?>> classes = new ArrayList<Class<?>>(); for (int i = 0; i < 10000000; ++i) { ClassWriter cw = new ClassWriter(0); cw.visit(Opcodes.V1_1, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); MethodVisitor mw = cw.visitMethod(Opcodes.ACC_PUBLIC, "<init>", "()V", null, null); mw.visitVarInsn(Opcodes.ALOAD, 0); mw.visitMethodInsn(Opcodes.INVOKESPECIAL, "java/lang/Object", "<init>", "()V"); mw.visitInsn(Opcodes.RETURN); mw.visitMaxs(1, 1); mw.visitEnd(); MetaspaceUtil test = new MetaspaceUtil(); byte[] code = cw.toByteArray(); Class<?> exampleClass = test.defineClass("Class" + i, code, 0, code.length); classes.add(exampleClass); } return classes; } }
设置元空间大小
-XX:MetaspaceSize=5M -XX:MaxMetaspaceSize=5M

然后运行测试类模拟:
package com.zwx.jvm.oom; import java.util.ArrayList; import java.util.List; public class MethodArea { public static void main(String[] args) { //jdk1.8 List<Class<?>> list=new ArrayList<Class<?>>(); while(true){ list.addAll(MetaspaceUtil.createClasses()); } } }
抛出如下异常OOM:Metaspace:
Java Virtual Machine Stacks(Java虚拟机栈)
每个Java虚拟机线程都有一个与线程同时创建的私有Java虚拟机栈。
Java虚拟机栈存储栈帧(Frame)。每个被调用的方法就会产生一个栈帧,栈帧中保存了一个方法的状态信息,如:局部变量,操作栈帧,方出出口等。
调用一个方法,就会产生一个栈帧,并压入栈内;一个方法调用完成,就会把该栈帧从栈中弹出,大致调用过程如下图所示:
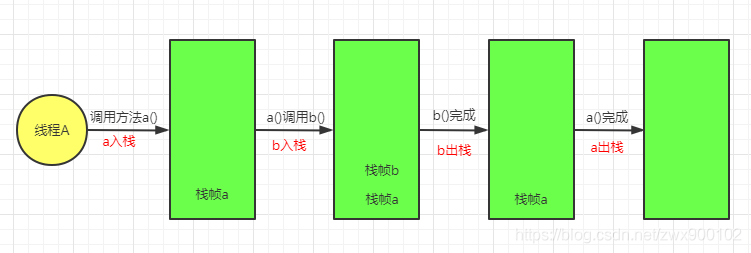
Java虚拟机栈中可能有下面两种异常情况:
- 如果线程执行所需栈深度大于Java虚拟机栈深度,则会抛出StackOverflowError。
上图可以知道,其实方法的调用就是入栈和出栈的过程,如果一直入栈而不出栈就容易发生异常(如递归)。 - 如果Java虚拟机栈可以动态地扩展,但是扩展大小的时候无法申请到足够的内存,则会抛出一个OutOfMemoryError。
大部分Java虚拟机栈都是支持动态扩展大小的,也允许设置固定大小(在Java虚拟机规范中两种都是可以的,具体要看虚拟机的实现)。
注:我们经常说的JVM中的栈,一般指的就是Java虚拟机栈。
模拟栈内StackOverflowError
下面是一个简单的递归方法,没有跳出递归条件:
package com.zwx.jvm.oom; public class JMVStack { public static void main(String[] args) { test(); } static void test(){ test(); } }
输出结果为:
Exception in thread "main" java.lang.StackOverflowError at com.zwx.jvm.oom.JMVStack.test(JMVStack.java:15) at com.zwx.jvm.oom.JMVStack.test(JMVStack.java:15) .....
Native Method Stacks(本地方法栈)
本地方发栈类似于Java虚拟机栈,区别就是本地方法栈存储的是Native方法。本地方发栈和Java虚拟机栈在有的虚拟机中是合在一起的,并没有分开,如:Hot Spot虚拟机。
本地方法栈可能出现如下异常:
- 如果线程执行所需栈深度大于本地方法栈深度,则会抛出StackOverflowError。
- 如果可以动态扩展本地方法栈,但是扩展大小的时候无法申请到足够的内存,则会抛出OutOfMemoryError。
总结
本文主要介绍了jvm运行时数据区的构造,以及每部分区域到底都存了哪些数据,然后去模拟了一下常见异常的产生方式,当然,模拟异常的方式很多,关键要知道每个区域存了哪些东西,模拟的时候对应生成就可以。
本文主要从总体上介绍运行时数据区,主要是有一个概念上的认识,下一篇,将会介绍类加载机制,以及双亲委派模式,介绍类加载模式的同时会对运行时数据区做更详细的介绍。

posted on 2020-09-22 14:57 我用java改变世界 阅读(359) 评论(0) 编辑 收藏 举报


